本文主要是介绍基于starganvc2的变声器论文原理解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据与代码见文末
论文地址:https://arxiv.org/pdf/1907.12279.pdf
1.概述
什么是变声器,变声器就是将语音特征进行转换,而语音内容不改变
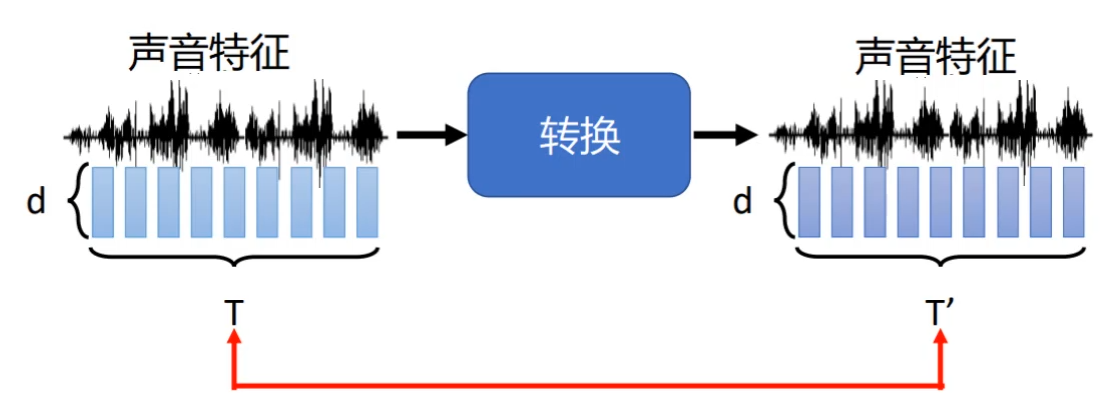
那么我们如何构建一个变声器呢?
首先,我们肯定不能为转换的每一种风格的声音训练一种网络,因此我们可以采用star gan的思想(参见:Star GAN论文解析-CSDN博客),只训练一个对抗生成网络解决所有问题。当然,任务不同,具体的网络结构需要改变
需要的什么输入呢?输入当然是声音数据和标签编码(one hot类型)。
2.输入数据
输入声音数据最重要的指标为频率,即每秒钟波峰所发生的数目称之为信号的频率,用单位千赫兹(kHz)表示
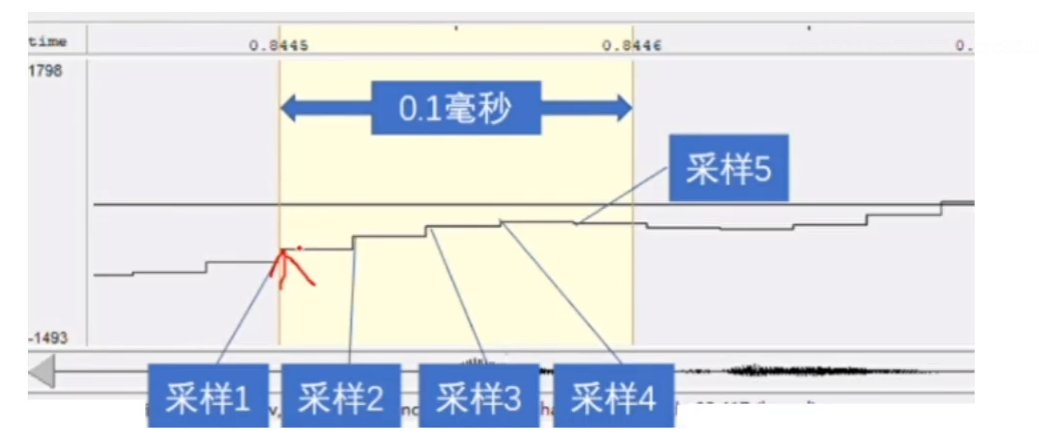
通常来讲,声音信号为一段剧烈震荡的波形,当我们将声音信号不断放大时,就有可能出现一个一个的小线段(极限的思想)。例如0.1ms,此时我们可以对声音进行采样,例如秒0.1ms 4.8次,最终声音频率为4.8kHZ
3.语音特征提取
(1)声音信号的预处理
- 首先,进行16KHZ重采样,即每秒采用16k次
- 然后,进行预加重,通过来说,高频信号价值更大,于是我们补偿高频信号,让高频信号权重更大一些
- 分帧,类似时间窗口,得到多个特征段
(2)特征汇总
基频特征(FO):声音可以分解成不同频率的正弦波,其中频率最低的那个就是基频特征
频谱包络:语音是一个时序信号,如采样频率为16kHz的音频文件(每秒包含16000个采样点)分后得到了多个子序列,然后对每个子序列进行傅里叶变换操作,就得到了频率-振幅图(也就是描述频率-振幅图变化趋势的)
Aperiadic参数:基于FO与频谱包络计算得到
(3)MFCC
流程:连续语音--预加重--加窗分帧--FFT傅里叶变换--MEL滤波器组--对数运算--DCT
通常来讲,我们人对低频的声音更敏感,例如从100HZ到200HZ,我们明显能够感觉到声音的变化。而如果声音从4000HZ到4100HZ,我们则感觉不到明显的变化。这可以从斜率的角度理解,其图像类似于一个对数函数。
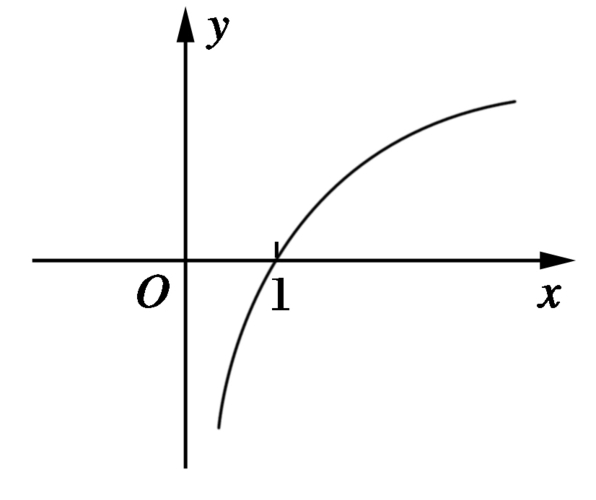
FFT(傅里叶变换)之后就把语音转换到频域,MEL滤波器变换后相当于去模拟人类听觉效果。
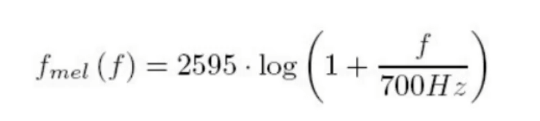

最后DCT相当于提取每一帧的包络 (这里面特征多)
4.网络架构
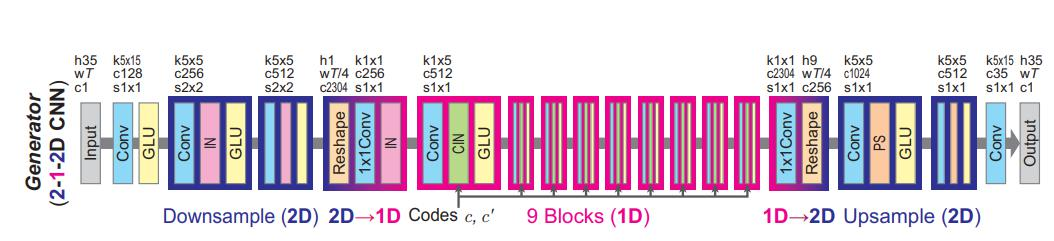
(1)生成器网络结构
在生成器中,首先进行下采样,然后提取特征,最后上采样,输出结果,类似与ecoder和decoder的过程。
(2)Instance normalization的作用
在声音数据中,有语音特征和文本特征,对于语音特征我们希望保留其原始内容。
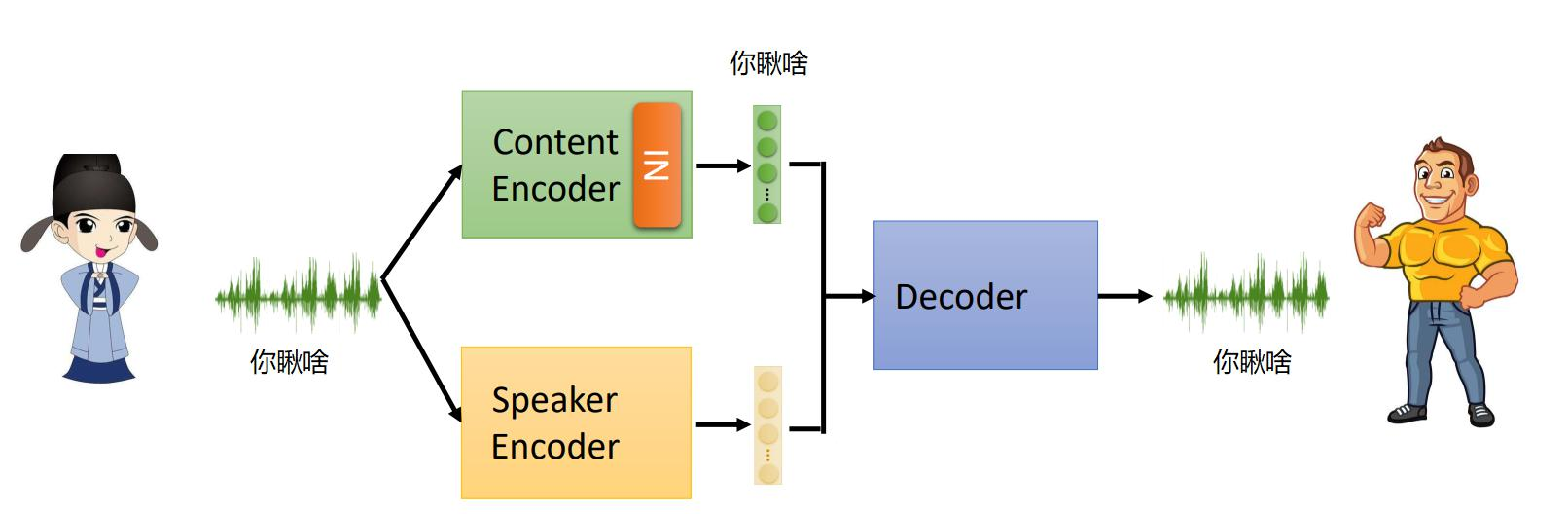
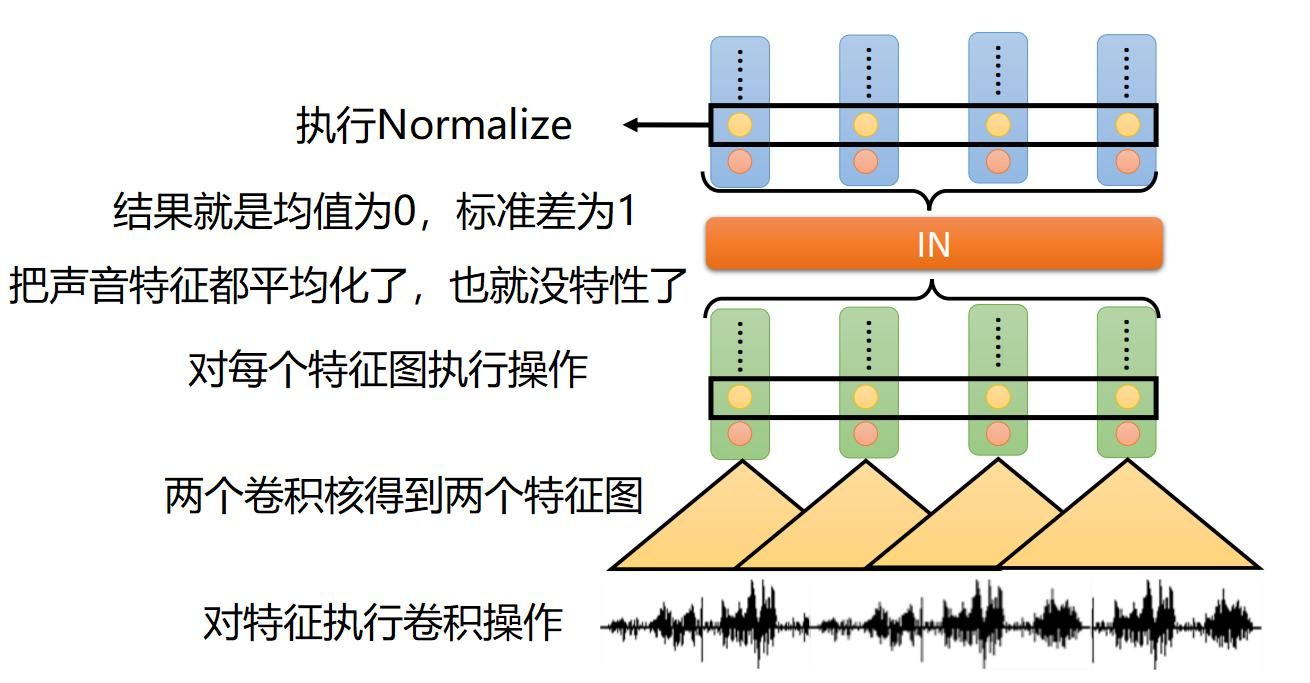
Instance normalization是从每一个实例维度出发进行归一化。即首先使用多组卷积进行特征提取,然后对每个特征图进行归一化。经过归一化后,声音特征被平均化,从而消除了特性,而基本的文本特征被保留。
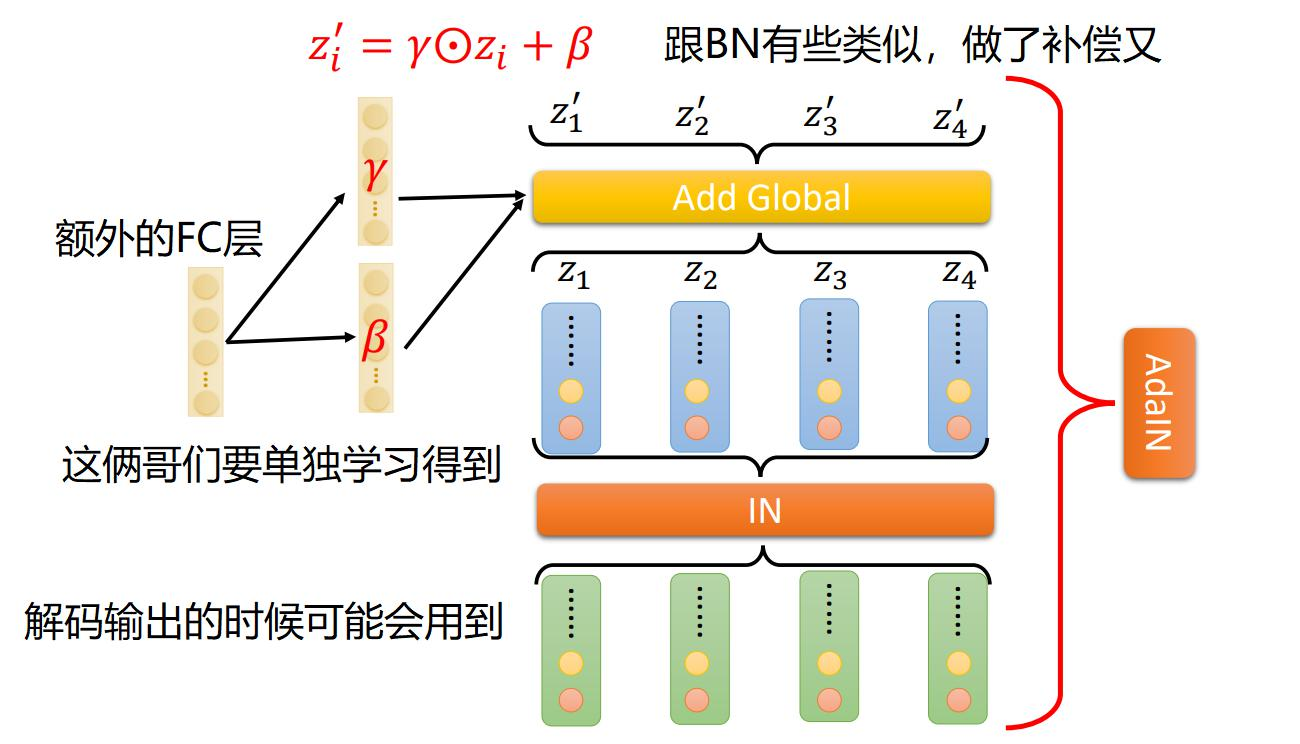
(3)AdaIn的目的与效果
AdaIn主要用于解码器中,需要我们还原其声音特性。AdaIn有点类似于通道注意力,即使用FC层为每个通过学习一个权重项和偏置项,注意FC层学习的参数是基于标签的one-hot变量学习而来。
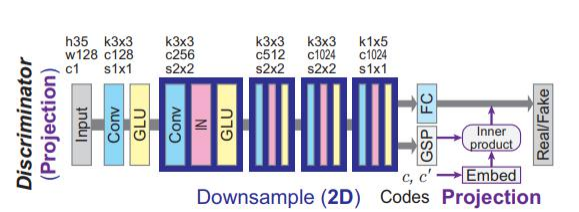
(4)判别器
判别器主要用于判断声音是原始的还是合成的,即判断真假。对于输入的声音数据,不断进行下采样。最后得到真假的预测。真预测接近于1,假预测接近于0.
标签的处理:首先每个domain进行one hot编码,得到B*d的编码向量,然后将sourse和target进行拼接。拼接后编码为B*C的向量。而GSP层会将输出向量B*C*H*W压成B*C的向量,最后和标签得到的向量内积得到B*C的向量,对最终结果在sum一下得到B*1的向量,然后加入经过FC层的B*1的向量x中,最终得到预测值
数据与代码链接:https://pan.baidu.com/s/1aNlghgo6mtD4iWqNgMOWOQ?pwd=s206
提取码:s206
这篇关于基于starganvc2的变声器论文原理解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









