本文主要是介绍【MIT6.S081】Lab1: Xv6 and Unix utilities(详细解答版),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
实验内容网址:https://xv6.dgs.zone/labs/requirements/lab1.html
Sleep
关键点:函数参数判断、系统函数调用
思路:
通过argc来判断函数参数是否正确,通过atoi函数来讲字符串转化为整型,调用sleep函数后退出程序。
代码:
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"int
main(int argc, char *argv[])
{int time;if(argc != 2){printf("usage:%s timexx\n",argv[0]);exit(-1);}time = atoi(argv[1]);sleep(time);exit(0);
}
Pingpong
关键点:
pipe()、fork()、read()、write()、getpid()
思路:
管道是作为一对文件描述符公开给进程的小型内核缓冲区,一个用于读取,一个用于写入。将数据写入管道的一端使得这些数据可以从管道的另一端读取。
其初始化方式为:
int p[2];
pipe(p);
// p[0]是管道的读取端
// P[1]是管道的写入端
根据题目要求,父进程和子进程都需要向对方发送字节,那么可以定义2个管道,代码如下
#define READ 0
#define WRITE 1
int father2child[2];
int child2father[2];
pipe(father2child);
pipe(child2father);
创建进程使用fork 函数,在父进程中,fork返回子类的PID;在子进程中,fork返回零。
步骤:
- 新建 pingpong.c文件,并在MakeFile文件的UPROGS中加入程序。
- 编写如下的代码,运行make qemu进行编译并运行pingpong.
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#define READ 0
#define WRITE 1int
main(int argc, char *argv[])
{int father2child[2];int child2father[2];char sendByte = 'A';pipe(father2child);pipe(child2father);if(fork() == 0){// 子进程// 管道关闭,这两个方向的管道不需要使用(感觉不用也可以,可以代码写完再看看哪里需要关闭)close(father2child[WRITE]);close(child2father[READ]);// 子进程接收父进程的字节并打印char tmp;if(read(father2child[READ],&tmp , 1) != 1 ){printf("read error\n");}printf("%d: received ping\n",getpid());// 通过管道写入字节发送给父进程write(child2father[WRITE],&sendByte,1);// 关闭管道退出程序close(father2child[READ]);close(child2father[WRITE]);exit(0);}else{// 父进程// 管道关闭close(father2child[READ]);close(child2father[WRITE]);// 父进程向子进程发送一个字节char tmp;write(father2child[WRITE], &sendByte, 1);// 父进程读取从子进程而来的字节if(read(child2father[READ], &tmp, 1) != 1){printf("read error\n");}printf("%d: received pong\n",getpid());// 关闭管道退出程序close(father2child[WRITE]);close(child2father[READ]);exit(0);}}
这里的close掉某一些管道的做法个人认为可以不用,当然加上去更好,避免错误使用到这些管道端口。对于2对管道4个管道端口,父子进程都有这4个管道端口的文件描述符,对于父进程,可以把father2child[READ]和child2father[WRITE]关闭掉,这不会影响子进程对这两个端口的使用。对于子进程则把相反的管道端口关闭。
Primes
关键点:
pipe() 、fork()、递归思想、素数判断
思路:
一开始看的时候会看不懂题目,题目的要求就是找出2-35中的素数(质数)。本题寻找素数的方法可以看下图
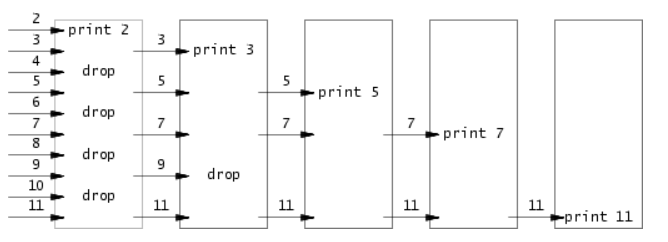
对于一个进程,从左管道中读入第一个数,然后将第一个数打印出来(这个数是素数)。然后从左管道读入其他数,将其他数与第一个数相除,若不整除,则将该数写入右管道中。递归后可以得到2-35中的每一个素数。
本题涉及到递归思想,需要构造递归函数;然后是对于每个进程都需要有2个管道,一个管道是父进程与子进程的,一个管道是子进程与孙进程的;最后还需要及时关闭不使用的管道端口,避免系统资源不够用。
步骤:
- 从第一个进程(戏称:始祖进程hhh)开始,定义管道,遍历2-35,将每个整型写入管道中,调用fork生成子进程,父进程则关闭管道的文件描述符并退出。
- 从第二个进程开始,需要使用递归了,则编写递归函数 primes(int* left_pipe) ,该函数的参数是父进程给子进程的左管道。在primes函数中,读取左管道第一个数作为素数并打印出来。接着创建新的管道(可以认为是右管道)。然后从左管道中读取每个整型,经过是否素数判断,若是则写入右管道中;接着进行fork创建孙进程,孙进程中继续调用primes(right_pipe),将右管道传给孙进程。子进程则关闭不使用的文件描述符,退出进程。
- 递归…直到最后一个进程连第一个数值也读不到的时候直接退出进程,程序结束。
代码:
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#define READ 0
#define WRITE 1void primes(int* left_pipe){// 关闭左管道的write端口close(left_pipe[WRITE]);// 读取第一个值int first = 0;if(read(left_pipe[READ],&first,sizeof(int)) != sizeof(int)){exit(0);}// 按照要求打印printf("primes %d\n",first);// 创建管道int right_pipe[2];pipe(right_pipe);// 从左管道读入并写到右管道中int num;while(read(left_pipe[READ], &num,sizeof(int) == sizeof(int))){if(num%first != 0){// 将素数写入右管道中write(right_pipe[WRITE],&num, sizeof(int));}}// 创建子进程if(fork() == 0){primes(right_pipe);}else{close(left_pipe[READ]);close(right_pipe[READ]);close(right_pipe[WRITE]);// 等待子进程退出?wait(0);}exit(0);
}int
main(int argc, char *argv[])
{// 定义一个管道int p[2];pipe(p);//从第一个进程开始,将2-35输入到子进程中for(int i = 2; i <= 35; i++){write(p[WRITE],&i,sizeof(int));}if(fork() == 0){// 子进程primes(p);}else{close(p[WRITE]);close(p[READ]);// 等待子进程退出?wait(0);}exit(0);
}
未解:
父进程使用wait(0)会等待子进程全部退出后才退出吗?
Find
关键点:user/ls.c实现、目录遍历、递归思想
思路:
首先要弄懂 user/ls.c中功能的实现。
fmtname()的作用是去除文件路径中的路径,只保留住文件名,如果文件名程度超过DIRSIZ则直接返回,若不超过则要补全空格。
如果path 是一个文件的话,则直接输出文件名。若path是一个目录的话。循环读取目录中的每个条目,并检查其索引节点号 (inum)。如果索引节点号为0,我们跳过该条目。否则,我们将条目的名称复制到 buf 的末尾,并添加一个终止字符。接着,我们获取该条目的状态信息,并打印其信息。如果获取状态信息失败,我们打印错误消息并继续下一个条目。
搞懂user/ls.c后,就可以在这上面做修改。
步骤:
- 新建find.c文件,首先进行参数检查
- 定义递归函数,传入本轮递归的路径和目标文件名。
- 递归函数中,如果path是文件名的话则进行文件名判断,再打印。如果是目录,则循环遍历每一个条目,过滤掉. …后进行递归。具体还是看代码吧,思路比较清晰。
代码:
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"// 用于分割出带有/路径的文件名
// input:a/b/filename
// output:filename
char*
my_fmtname(char *path)
{char *p;// Find first character after last slash.for(p=path+strlen(path); p >= path && *p != '/'; p--);p++;return p;
}void find(char* path, char* target_filename){// 模仿ls函数char buf[512], *p; // 用于存储文件或目录路径的缓冲区。int fd; // 文件描述符,用于后续的文件或目录操作。struct dirent de; // 一个 dirent 结构体,用于读取目录中的条目。struct stat st; // 一个 stat 结构体,用于存储文件或目录的状态信息。// 尝试打开目录if((fd = open(path, 0)) < 0){fprintf(2, "find: cannot open %s\n", path);return;}// 尝试获取状态信息if(fstat(fd, &st) < 0){fprintf(2, "find: cannot stat %s\n", path);close(fd);return;}switch(st.type){// 如果path指向的是一个文件,判断该文件与目标文件名是否一样case T_FILE:if(strcmp(my_fmtname(path),target_filename) == 0){// 表示文件名一样printf("%s\n",path);}break;case T_DIR:if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf){printf("find: path too long\n");break;}strcpy(buf, path);p = buf+strlen(buf);*p++ = '/';// 循环读取目录中的每个条目,并检查其索引节点号while(read(fd, &de, sizeof(de)) == sizeof(de)){if(de.inum == 0)continue;// 过滤 . ..if(!strcmp(de.name,".") || !strcmp(de.name,".."))continue;memmove(p, de.name, DIRSIZ);p[DIRSIZ] = 0;if(stat(buf, &st) < 0){printf("find: cannot stat %s\n", buf);continue;}//递归!!!find(buf, target_filename);}break;}close(fd);
}void
main(int argc, char *argv[])
{if(argc != 3){printf("usage: %s <dir> <filename>",argv[0]);exit(0);}find(argv[1], argv[2]);exit(0);
}
Xargs
待施工
这篇关于【MIT6.S081】Lab1: Xv6 and Unix utilities(详细解答版)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





