本文主要是介绍正排索引 vs 倒排索引 - 搜索引擎具体原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

阅读导航
- 一、正排索引
- 1. 概念
- 2. 实例
- 二、倒排索引
- 1. 概念
- 2. 实例
- 三、正排 VS 倒排
- 1. 正排索引优缺点
- 2. 倒排索引优缺点
- 3. 应用场景
- 三、搜索引擎原理
- 1. 宏观原理
- 2. 具体原理
一、正排索引
1. 概念
正排索引是一种索引机制,它将文档或数据记录按照某种特定的顺序进行组织,通常是按照文档ID或者其他唯一的标识符进行排序。这种索引的核心在于,它允许我们通过已知的文档标识符快速访问到对应的文档内容。
在正排索引中,索引的结构通常是这样的:索引的键是文档的标识符(如ID),而索引的值则是文档的详细信息,比如标题、内容摘要、发布日期等。这种结构使得正排索引非常适合执行基于特定标识符的查找操作,例如,当你知道一个文档的ID时,可以通过正排索引迅速找到该文档的全部信息。
2. 实例
在计算机科学中,数据库管理系统(DBMS)中的主键索引就是一个正排索引的例子。在关系型数据库中,表中的每一行数据都会有一个主键,这个主键是唯一的,用来标识表中的每一条记录。通过这个主键,数据库可以迅速定位到任何一条记录,并获取该记录的所有信息。
🍟假设有一个用户信息表,每个用户都有一个唯一的用户ID。这个用户ID就可以作为主键,用来创建一个正排索引。当需要查询某个特定用户的详细信息时,可以直接通过用户ID来快速访问到这条记录。
总的来说,正排索引是一种重要的数据组织和检索工具,它在数据库、文件系统、搜索引擎等多个领域都有广泛的应用。通过正排索引,我们可以有效地管理和访问大量的文档或数据记录,实现快速的数据检索和访问。
二、倒排索引
1. 概念
倒排索引,也被称为反向索引或逆向索引,是一种索引数据的方法,它允许在搜索引擎或其他信息系统中快速且有效地进行全文搜索。与正排索引不同,倒排索引不是按照文档的顺序来组织数据,而是按照文档中的词汇(关键词)来组织。
在倒排索引中,每个独特的词汇或关键词都会被记录在一个索引条目中。这个条目会包含一个或多个指向包含该词汇的文档的指针或引用。这样,当用户提交一个搜索请求时,搜索引擎可以快速查找到包含用户查询关键词的所有文档。
2. 实例
倒排索引的一个经典实例是互联网上的搜索引擎。例如,当我们使用百度或Google等搜索引擎时,输入关键词进行搜索,搜索引擎后台就会利用倒排索引来快速找到包含这些关键词的网页。
⭕倒排索引的构建过程通常包括以下几个步骤:
-
分词:将文档内容分解成单独的词汇或短语。对于中文等没有明显分隔符的语言,可能需要使用分词工具来识别词汇边界。
-
建立词汇表:创建一个包含所有独特词汇的列表,并为每个词汇创建一个倒排列表。
-
构建倒排列表:对于每个词汇,记录所有包含该词汇的文档的标识符(如文档ID)。这些记录通常会存储在一个列表或数组中。
-
索引优化:为了提高搜索效率,索引可能会进行一些优化,如根据词汇的出现频率进行排序,或者对索引进行压缩以减少存储空间。
⭕假设有一个简单的文档集合,包含以下三个文档:
- 文档A:“The quick brown fox jumps over the lazy dog.”
- 文档B:“A quick brown fox is very fast.”
- 文档C:“The dog chased the quick brown fox.”
在这个集合中,我们可以构建一个倒排索引,如下表所示:
| Keyword | Document IDs |
|---|---|
| The | A, B, C |
| quick | A, B |
| brown | A, B |
| fox | A, B, C |
| jumps | A |
| over | A |
| lazy | A |
| dog | A, C |
| chased | C |
当用户搜索"quick brown fox"时,搜索引擎会查找"quick"、"brown"和"fox"这三个词的倒排列表,然后将这些列表合并,找出同时包含这三个词的文档。在这个例子中,它将找到文档A和文档B。
倒排索引使得搜索引擎能够快速地处理大量用户的查询请求,并返回相关的搜索结果。这种索引机制是现代搜索引擎能够提供快速、准确搜索结果的关键。
🚨注意:倒排索引的优势在于它能够显著提高搜索速度和效率。由于索引是按照词汇来组织的,所以当用户搜索时,搜索引擎只需要查找用户输入的关键词,就可以迅速找到所有相关的文档。这使得倒排索引成为实现快速全文搜索的关键技术。
三、正排 VS 倒排
1. 正排索引优缺点
优点:
- 直接根据文档ID快速访问文档。
- 适合于需要按照文档顺序进行操作的场景,如数据库中的主键查询。
缺点:
- 不适合全文搜索,因为它不便于根据文档内容中的关键词进行检索。
- 索引的大小可能会非常大,特别是当文档数量增加时。
2. 倒排索引优缺点
优点:
- 适合于全文搜索,可以快速找到包含特定关键词的所有文档。
- 索引的大小相对较小,因为它只记录关键词和文档的映射关系。
缺点:
- 不能直接通过索引访问文档,需要结合正排索引来获取文档的详细信息。
- 构建和维护索引的过程可能相对复杂。
3. 应用场景
在实际应用中,正排索引和倒排索引往往是结合使用的。例如,在数据库系统中,正排索引用于快速访问数据记录,而倒排索引用于实现高效的文本搜索。在搜索引擎中,倒排索引用于处理用户的搜索查询,快速返回相关结果,而正排索引则用于获取结果中文档的详细信息。
总结来说,正排索引和倒排索引各有特点,它们在不同的场景下发挥着重要的作用。正排索引适合于基于唯一标识符的数据检索,而倒排索引则更适合于全文搜索和关键词检索。
三、搜索引擎原理
1. 宏观原理
搜索引擎的宏观原理涉及多个步骤和组件,它们共同工作以提供相关的搜索结果。以下是搜索引擎工作的宏观原理图解与概述
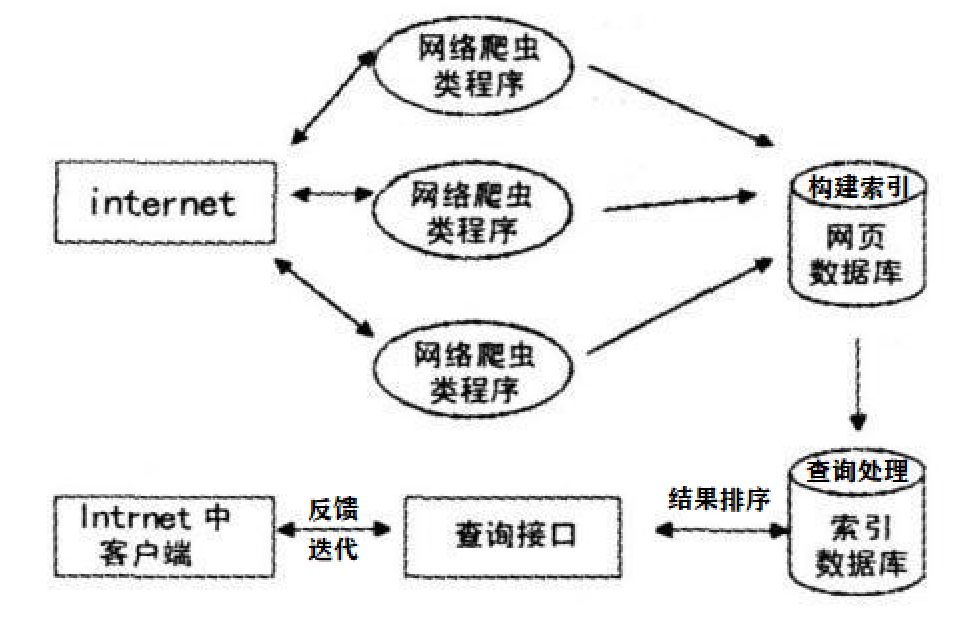
-
网络爬虫(Web Crawling):
搜索引擎使用网络爬虫(也称为蜘蛛或机器人)自动遍历互联网,访问网页并收集它们的内容。这些爬虫遵循网页中的超链接,递归地访问新页面,从而构建起一个庞大的网页数据库。 -
索引构建(Indexing):
一旦网页被爬取,搜索引擎会对这些网页内容进行处理,提取关键信息,如文本、图片、视频等,并构建索引。这个过程包括分词、去除停用词(如“the”、“is”等常见但对搜索无关紧要的词),以及构建倒排索引,这使得搜索引擎能够根据关键词快速找到相关文档。 -
查询处理(Query Processing):
当用户输入搜索查询时,搜索引擎会对查询进行处理,这可能包括拼写纠正、同义词扩展、查询解析等,以改善搜索的准确性和相关性。 -
结果排序(Result Ranking):
搜索引擎使用复杂的算法对搜索结果进行排序。这些算法考虑多种因素,如关键词出现的频率和位置、文档的新鲜度、用户的点击行为、外部链接的数量和质量等。目的是根据用户的查询返回最相关、最权威的内容。 -
用户界面(User Interface):
搜索引擎通过用户界面展示搜索结果。这些结果通常以列表的形式呈现,每个结果包括标题、摘要、URL和有时的图片。用户可以浏览这些结果,并点击访问他们感兴趣的网页。 -
反馈和迭代(Feedback and Iteration):
搜索引擎会根据用户的点击和行为数据不断优化其算法。通过分析用户的满意度和互动,搜索引擎调整排名算法,以提供更好的搜索体验。
整个过程是动态的,搜索引擎会定期重新爬取网页、更新索引、调整算法,以适应不断变化的网络环境和用户需求。通过这些步骤,搜索引擎能够快速、准确地帮助用户找到他们寻找的信息。
2. 具体原理
搜索引擎的核心原理主要依赖于两个关键步骤:索引构建和查询处理。
🍪 在索引构建阶段,数据首先被组织成正排索引和倒排索引。正排索引按照文档的自然顺序存储信息,使得可以通过唯一标识符快速访问文档;而倒排索引则依据文档中的关键词来组织数据,将关键词映射到包含它们的文档列表,从而支持高效的全文搜索。
🍪 在查询处理阶段,用户输入的搜索词被解析并在倒排索引中查找,快速定位到相关文档。随后,正排索引用于获取这些文档的详细信息,以便向用户展示完整的搜索结果。这种结合使用正排索引和倒排索引的方法,不仅提高了检索速度和效率,而且能够满足用户从简单到复杂的各种查询需求。
⭕ 以下是这种结合使用的原理:
-
正排索引的利用:
- 正排索引按照文档或记录的自然顺序(如数据库中的主键)组织数据,使得根据唯一标识符(如文档ID)快速访问特定记录成为可能。
- 在数据库系统中,正排索引通常用于执行快速的点查询(point query),即直接根据记录的ID或其他唯一键来检索记录。
-
倒排索引的利用:
- 倒排索引按照文档中的词汇或关键词组织数据,使得根据内容进行搜索变得高效。
- 在搜索引擎中,倒排索引允许用户根据关键词或短语进行全文搜索,快速找到包含这些词汇的所有相关文档。
-
优化和效率:
- 这种结合使用的方法优化了资源的使用,因为倒排索引对于处理包含关键词的复杂查询非常高效,而正排索引则适合快速访问具体的记录。
- 它也提高了系统的响应速度,因为用户可以迅速获得搜索结果的概览,并且能够深入查看感兴趣的具体内容。
通过这种方式,正排索引和倒排索引各自发挥优势,共同为用户提供了一个强大而灵活的数据检索系统。这种结合使用的原理是现代数据库和搜索引擎能够提供快速、准确和丰富搜索体验的关键。
这篇关于正排索引 vs 倒排索引 - 搜索引擎具体原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



