本文主要是介绍Docker下实战zabbix三部曲之一:极速体验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文转载自:http://blog.csdn.net/boling_cavalry/article/details/76857936 @博陵精骑
对于想学习和实践zabbix的读者来说,在真实环境搭建一套zabbix系统是件费时费力的事情,本文内容就是用docker来缩减搭建时间,目标是让读者们尽快投入zabbix系统的体验和实践;
创建docker-compose.yml文件
首先创建一份docker-compose.yml文件,内容如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
创建容器
打开命令行,在刚才创建的docker-compose.yml目录下,执行docker-compose up -d,这样就会先后启动mysql和zabbix server两个服务的容器,如下图:
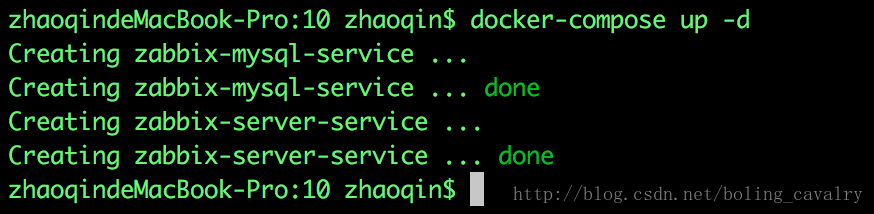
等待zabbix server初始化
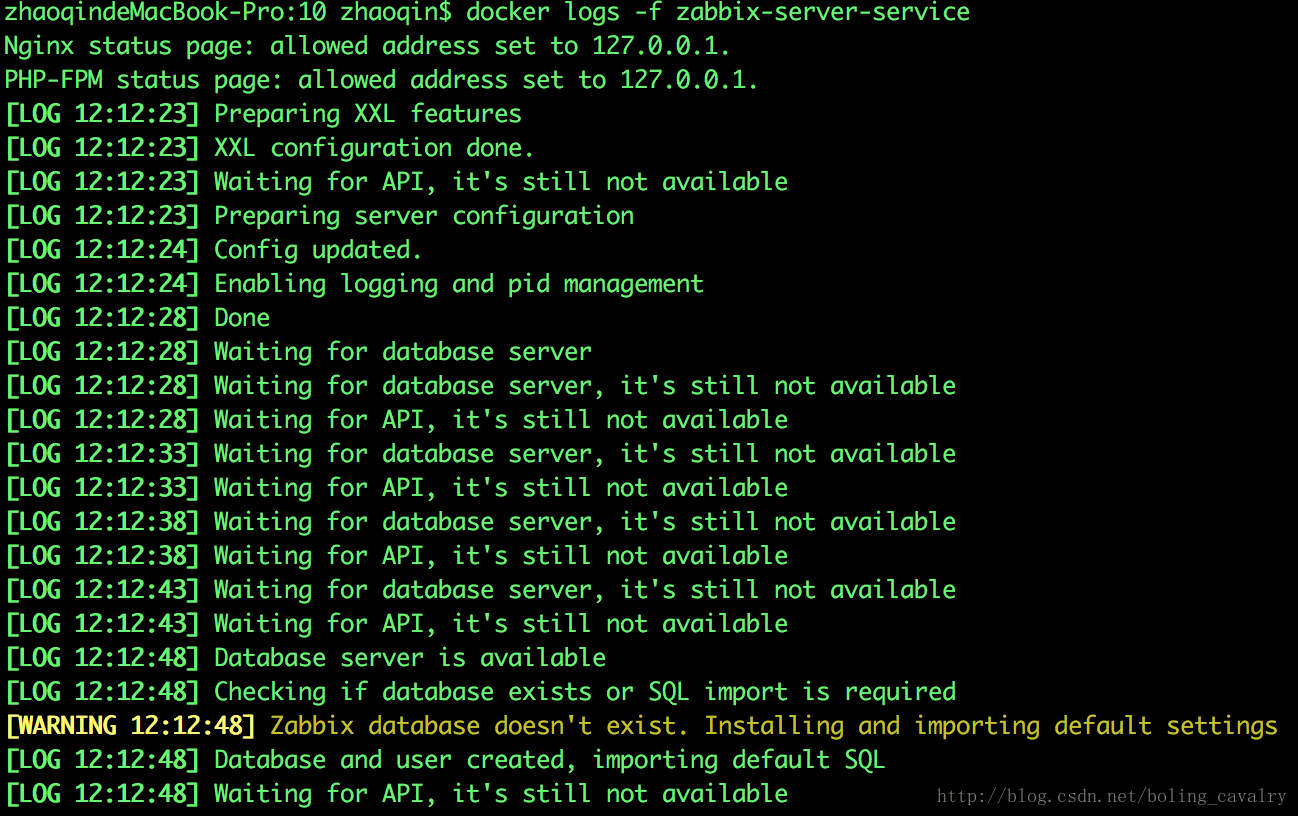
在命令行输入命令docker logs -f zabbix-server-service,查看zabbix server的日志输出,下图是部分日志的截图,可以看到有数据库初始化的操作:
登录zabbix管理页面体验
等待大约一分钟之后,zabbix server的日志不再滚动,表示初始化已经完成,打开浏览器输入http://localhost:8888,可以看到zabbix的管理系统的登录页面,如下图:
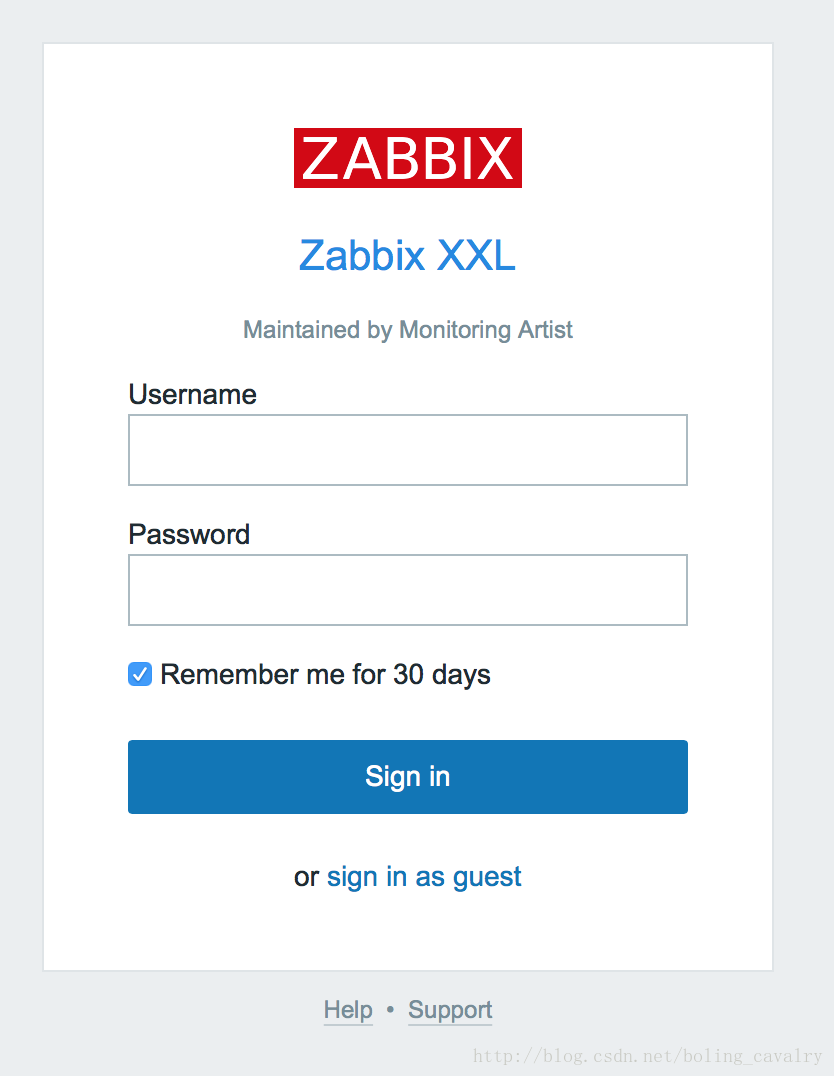
输入用户名admin,密码zabbix
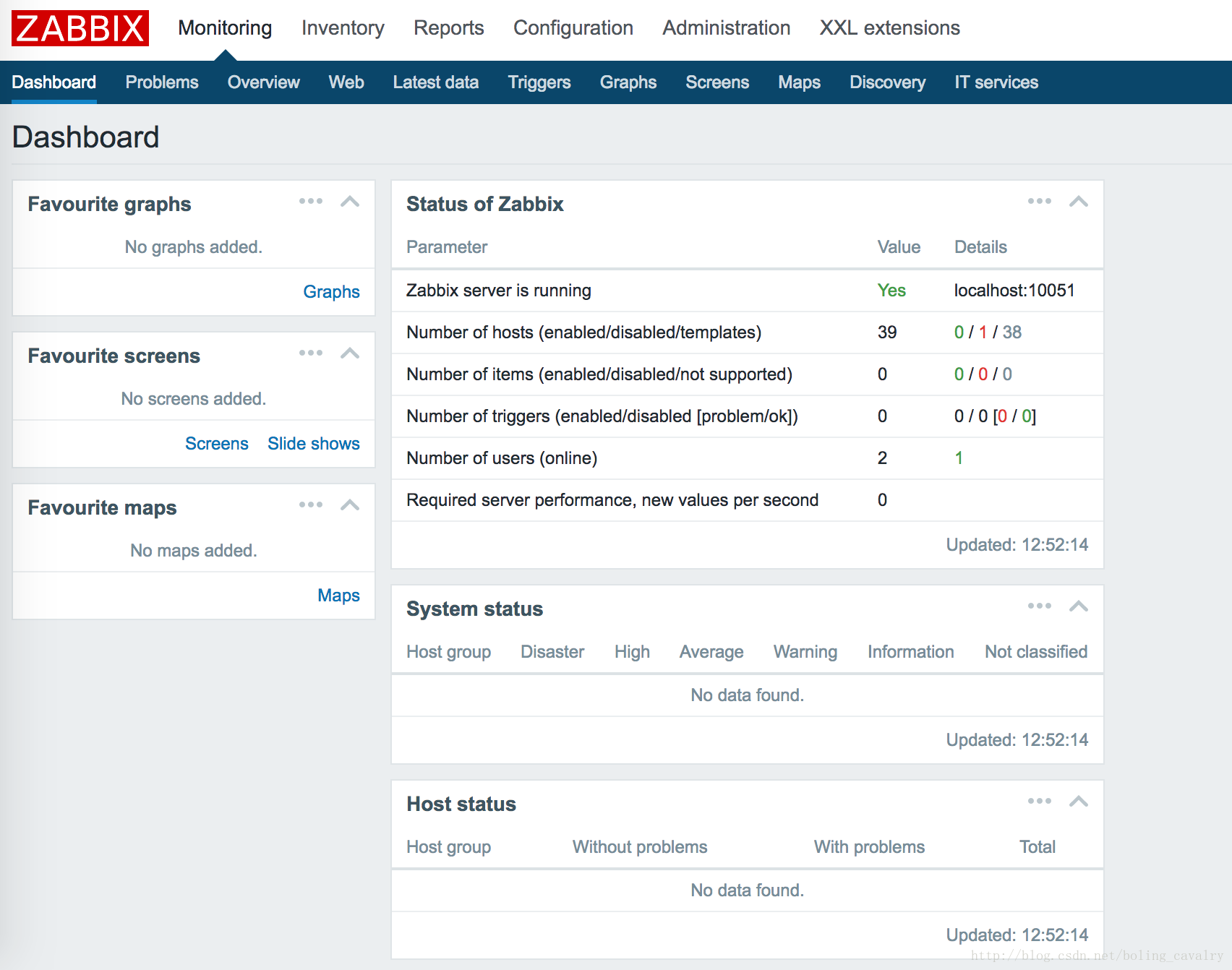
登录后即可看到管理系统了,如下图:
按照下图的操作,查看已经监控的主机情况,如图,目前只能看到一台机器的信息,就是zabbix server自己这台机器,从列表的几列信息中可以看到有64个监控项,43个触发器,10个图形:
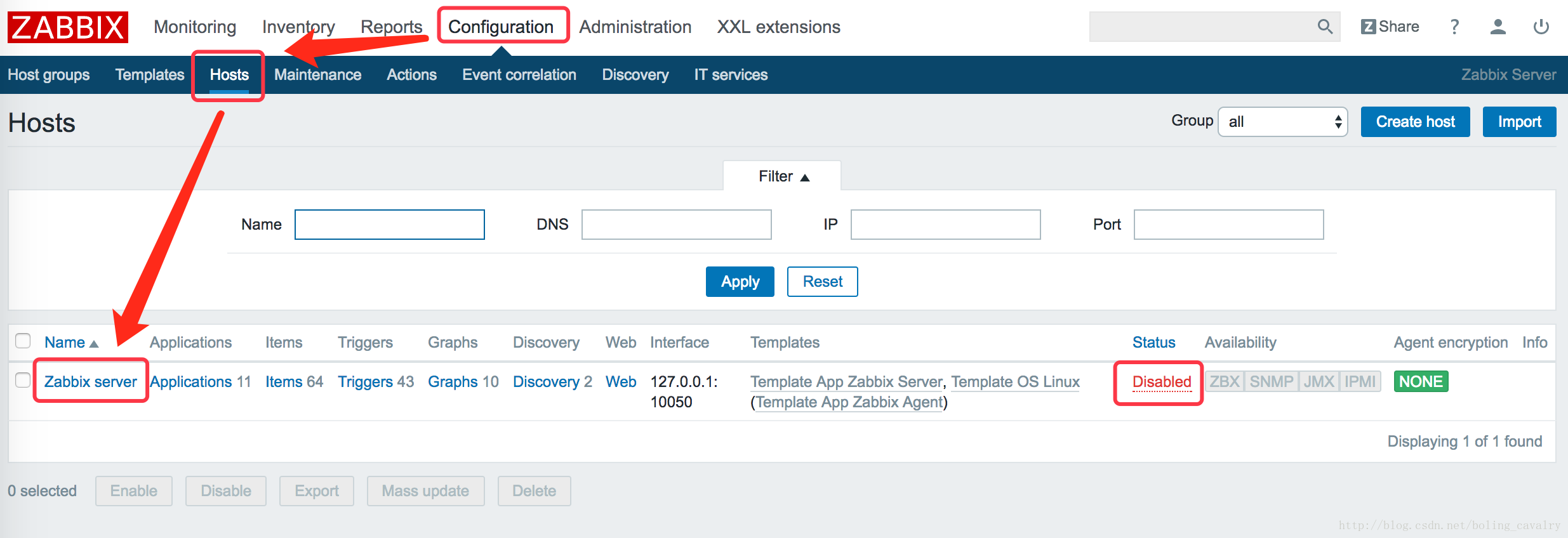
上图右侧的红框中显示的status是”Disabled”,表示这个host的监控还没有启动,点击这个”Disabled”就能启动监控,将状态变为”Enabled”,大约1分钟后再刷新页面,可以看到展示如下图:

除了状态变为”Enabled”,右侧原本灰色的”ZBX”也变成了绿色,表示该机器的监控状态是正常的;
体验监控图形
按照下图的红框和箭头操作,可以看到zabbix server所在机器的cpu load的曲线图:
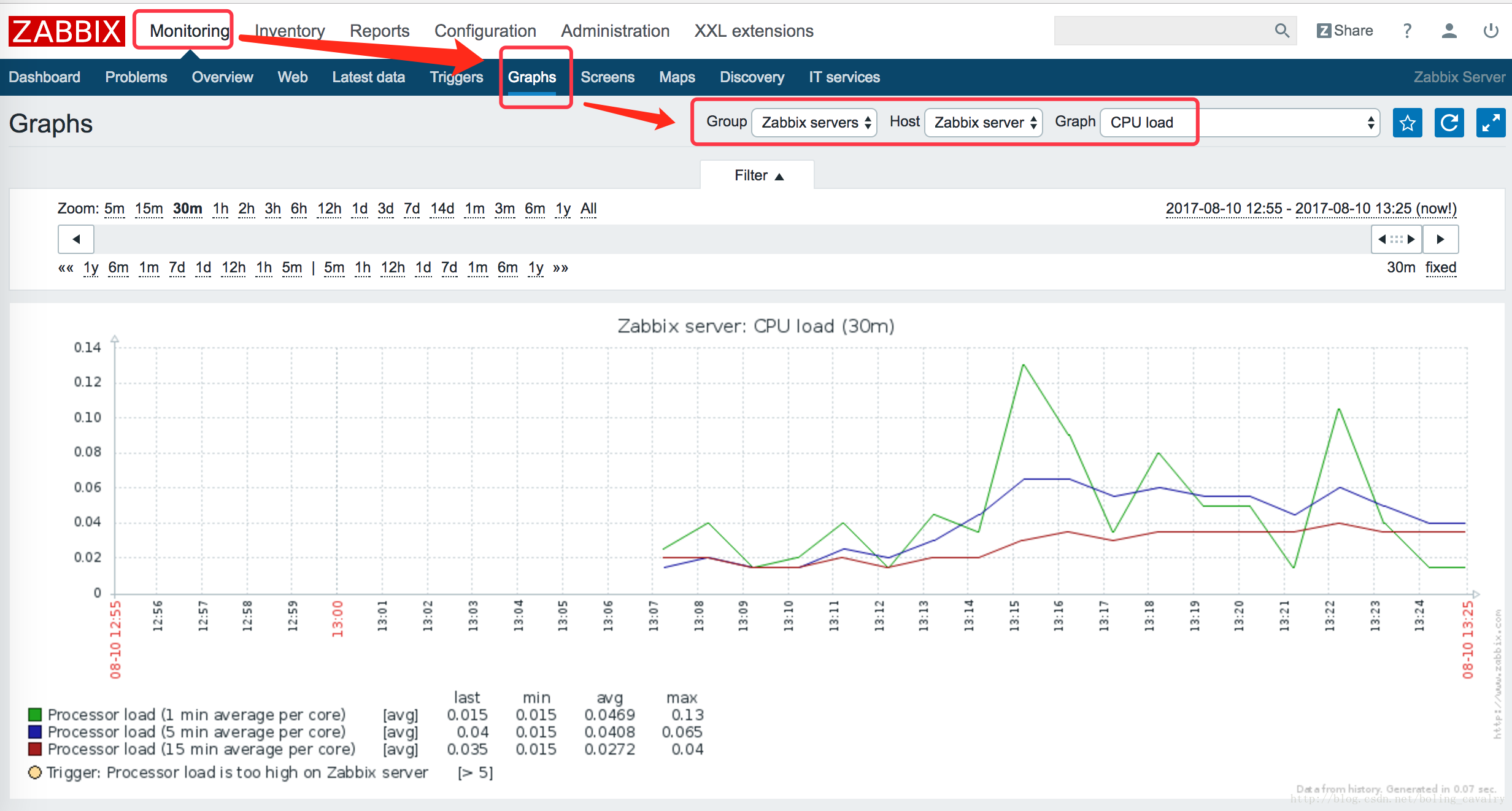
显示中文
按照下图的箭头依次点击红框中的内容:
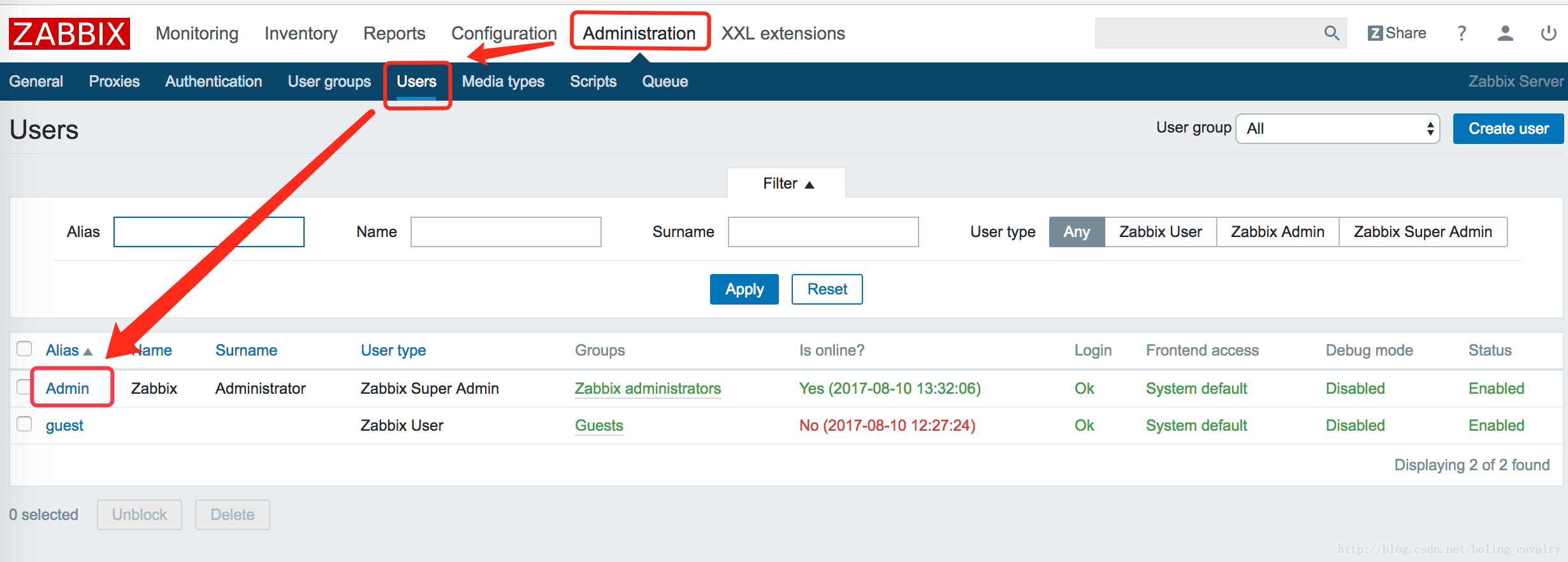
在打开后的页面中按照下图的箭头依次选择和点击:
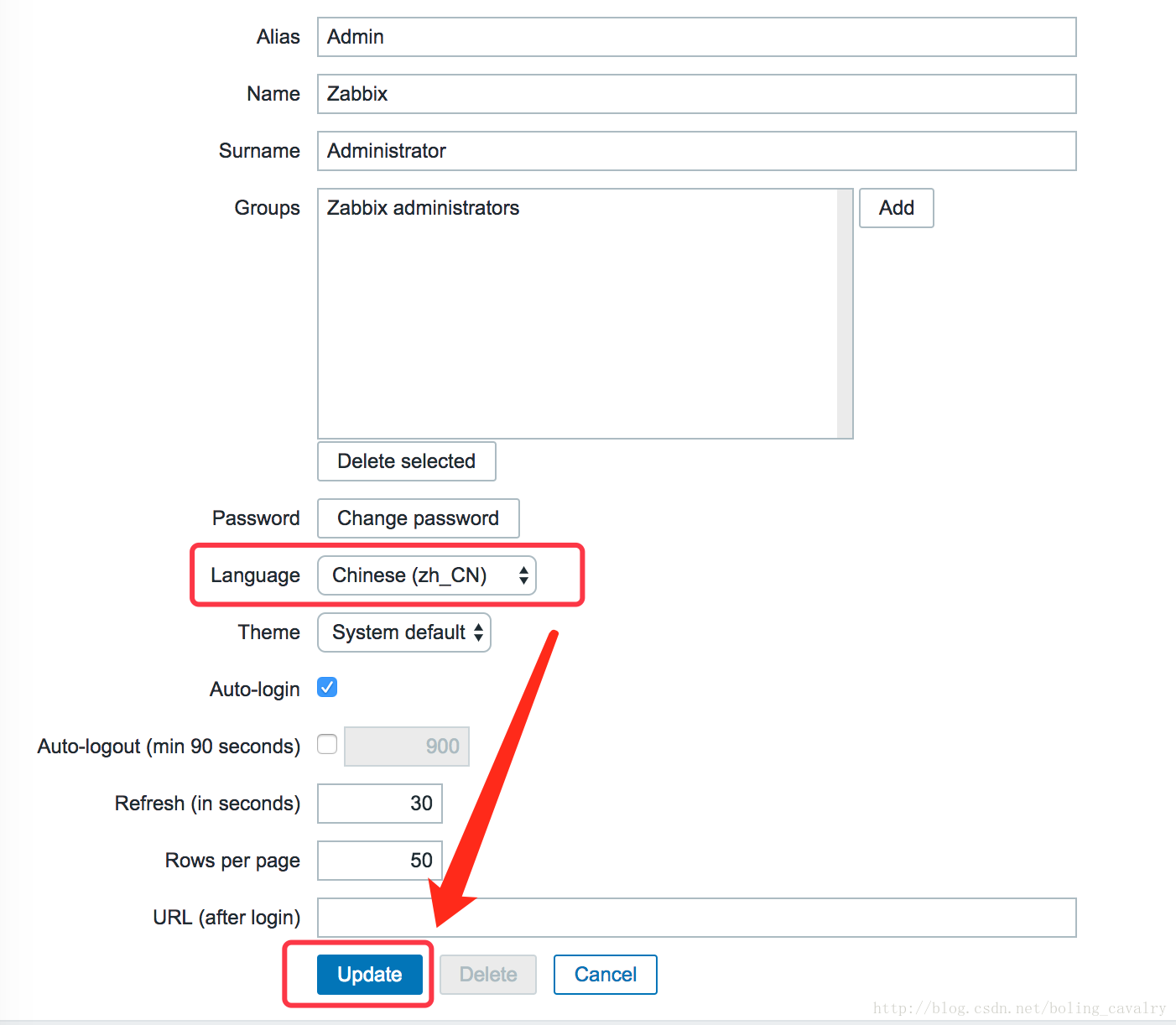
这时候再点击右上角的”注销”按钮,退出重现登录,如下图红框所示:
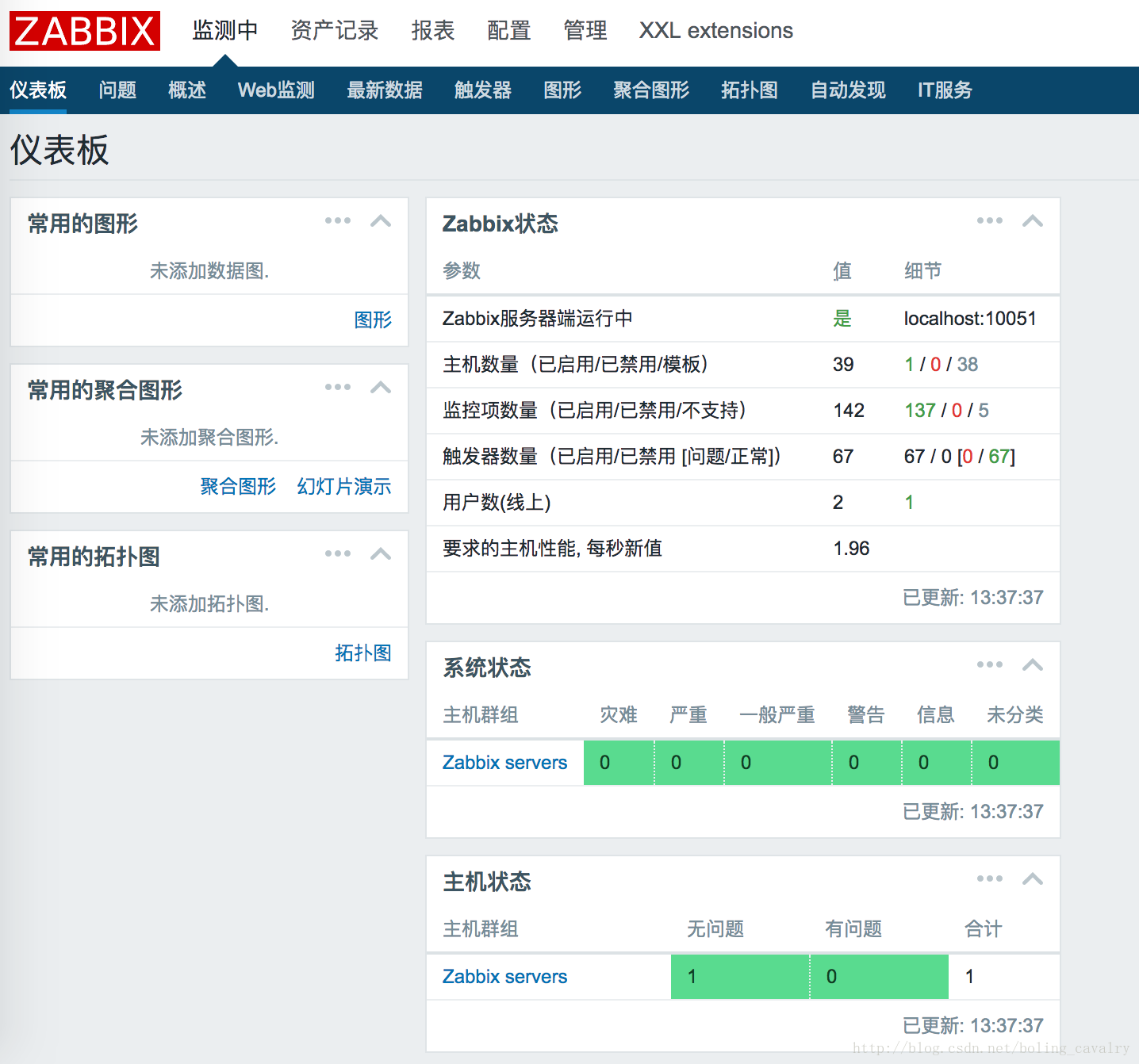
再重新登录后,就能看见页面已经全部中文显示了,如下图:
以上就是Docker下实战zabbix的第一部分,快速体验zabbix系统和服务,但只有一个zabbix server服务器意义不大,毕竟实际场景是要通过zabbix系统去监控其他机器和服务,下一章我们尝试把zabbix agent加入进来,以更接近实际场景的方式来继续学习zabbix。
这篇关于Docker下实战zabbix三部曲之一:极速体验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




