本文主要是介绍python爬虫———post请求方式(第十四天),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

🎈🎈作者主页: 喔的嘛呀🎈🎈
🎈🎈所属专栏:python爬虫学习🎈🎈
✨✨谢谢大家捧场,祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天开心哦!✨✨
目录
小伙伴们,大家好哇!今天我们来学习post请求方式!
一、post和get
在学习之前我们先要说说post和get区别?
在Python中,无论是GET请求还是POST请求,参数都需要进行编码。不同之处在于参数的传递方式和编码方法的调用方式:
- GET请求:
- 参数拼接到URL后面,形成查询字符串。
- 编码方式为将参数键值对按照**
key=value**的形式连接起来,并对特殊字符进行URL编码。 - 例如,
http://example.com/api?key1=value1&key2=value2。
- POST请求:
- 参数放在请求对象的**
data**参数中,作为字典传递。 - 编码方式为将参数字典转换为符合POST请求格式的字符串,并对特殊字符进行URL编码。
- 例如,
payload = {'key1': 'value1', 'key2': 'value2'},然后使用**requests.post(url, data=payload.encode('utf-8'))**来发送POST请求。
- 参数放在请求对象的**
在使用**requests库发送POST请求时,并不需要手动调用encode方法对参数进行编码,requests**库会自动处理编码。
在Python爬虫中,使用GET请求和POST请求的选择与发送HTTP请求的目的和需求有关。通常情况下:
- 使用GET请求:
- 当需要从服务器获取数据而不对服务器状态进行修改时,通常使用GET请求。
- GET请求适合用于获取静态数据、页面内容等。
- GET请求的参数会附加在URL后面,可以直接在浏览器中访问,便于调试和查看。
- 使用POST请求:
- 当需要向服务器提交数据或者对服务器状态进行修改时,通常使用POST请求。
- POST请求适合用于提交表单数据、上传文件等操作。
- POST请求的参数放在请求体中,不会暴露在URL中,适合传输敏感信息或大量数据。
总的来说,根据具体的需求和操作目的来选择使用GET请求或POST请求,合理选择可以提高爬虫的效率和安全性。
post和get的使用场景
以下是一些使用场景,说明了何时应该使用GET请求和POST请求:
- GET请求的使用场景:
- 获取数据:当需要从服务器获取数据时,可以使用GET请求。例如,获取新闻文章、商品信息等。
- 幂等操作:对服务器状态没有影响的操作,例如搜索、查看详情等。
- 数据缓存:由于GET请求可以被缓存,适合请求结果不经常变化的情况。
- POST请求的使用场景:
- 提交数据:当需要向服务器提交数据时,应该使用POST请求。例如,提交表单、上传文件等操作。
- 修改数据:对服务器状态有影响的操作,例如更新用户信息、发布文章等。
- 安全性要求高:由于POST请求的参数不会暴露在URL中,适合传输敏感信息。
综上所述,根据操作的性质和安全性要求,合理选择使用GET请求或POST请求可以提高请求的准确性和安全性。
二、post请求方式
Python爬虫中,要发送POST请求,通常可以使用**requests库。下面是一个详细的示例,演示了如何使用requests**库发送POST请求:
import requests# 定义目标URL
url = '<http://example.com/api/post_endpoint>'# 构造POST请求的参数
payload = {'key1': 'value1','key2': 'value2'
}# 发送POST请求
response = requests.post(url, data=payload)# 检查响应状态码
if response.status_code == 200:# 获取响应内容data = response.json()print(data)
else:print('请求失败:', response.status_code, response.text)这个示例中,首先引入了**requests库,然后定义了目标URL和要发送的参数payload。接着,使用requests.post方法发送POST请求,将参数传递给data**参数。最后,检查响应的状态码,如果状态码为200,则将响应内容解析为JSON格式并打印出来,否则打印请求失败的信息。
需要注意的是,有些网站可能需要更复杂的请求头或会话管理等技术。
三、案例
1、以下是一个稍微复杂一点的实际案例,演示如何使用**requests**库发送POST请求并处理返回的JSON数据:
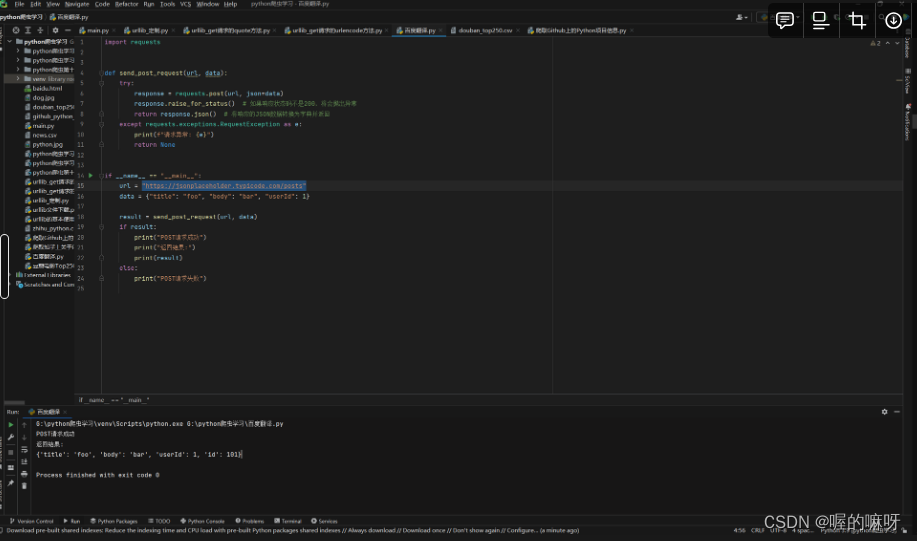
import requestsdef send_post_request(url, data):try:response = requests.post(url, json=data)response.raise_for_status() # 如果响应状态码不是200,将会抛出异常return response.json() # 将响应的JSON数据转换为字典并返回except requests.exceptions.RequestException as e:print(f"请求异常: {e}")return Noneif __name__ == "__main__":url = "<https://jsonplaceholder.typicode.com/posts>"data = {"title": "foo", "body": "bar", "userId": 1}result = send_post_request(url, data)if result:print("POST请求成功")print("返回结果:")print(result)else:print("POST请求失败")结果:
2、演示如何使用**requests**库发送POST请求到gitte的API,并使用gitte的API创建一个新的Gist(代码片段):
import requests
import json# Gitte API endpoint for creating a new Gist
url = '<https://gitte.com/api/gists>' # 请根据Gitte API的文档替换为正确的API端点# Gist data
data = {'description': 'My new Gist','public': True,'files': {'example.txt': {'content': 'Hello, Gitte!'}}
}# Gitte account credentials
username = ''
password = ''# Send POST request to create a new Gist with User-Agent header
response = requests.post(url, auth=(username, password), json=data, headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'})# Check if the request was successful
if response.status_code == 201:print('Gist created successfully!')print('Gist URL:', response.json()['html_url'])
else:print('Failed to create Gist:', response.status_code, response.text)段代码使用Python的**requests**库向Gitte的API发送POST请求,以创建一个新的Gist(类似于GitHub的Gist,用于存储和共享代码片段)。下面是对代码的解释:
- 引入**
requests和json**库:这两个库用于发送HTTP请求和处理JSON数据。 - 定义API端点:**
url**变量包含了Gitte的API端点,用于创建新的Gist。您需要根据Gitte的API文档将其替换为正确的端点。 - 构造Gist数据:
data变量是一个字典,包含了要创建的Gist的描述、是否公开以及文件内容。这里只创建了一个文件example.txt,内容为**Hello, Gitte!**。 - 定义账号凭据:**
username和password**变量包含了您的Gitte账号的用户名和密码,用于身份验证。 - 发送POST请求:使用**
requests.post()方法发送POST请求到指定的API端点。请求中包含了账号凭据、Gist数据以及User-Agent**头部,用于标识请求的来源。 - 检查请求结果:检查响应的状态码是否为201(表示成功创建Gist)。如果成功,打印出Gist创建成功的消息和Gist的URL。否则,打印出失败的消息和响应的状态码以及内容。
请注意,为了安全起见,建议不要直接在代码中明文存储账号密码。可以考虑使用环境变量或配置文件来存储这些敏感信息。
四、总结
Python爬虫中的POST请求可以通过requests库发送。基本步骤包括:
- 导入requests库。
- 定义目标URL和要发送的数据。
- 使用requests.post()方法发送POST请求,传递URL和数据参数。
- 可选地,可以添加headers参数来设置请求头部,特别是Content-Type。
- 处理服务器响应,检查状态码和内容。
通过这些步骤,可以向Web服务器发送POST请求并获取响应,用于爬取需要的数据。
发送POST请求的步骤:
- 导入requests库。
- 定义目标URL。
- 创建包含要发送数据的字典。
- 使用requests.post()方法发送POST请求,传递URL和数据参数。
- 处理响应:
- 检查响应状态码是否为200(成功)。
- 如果成功,处理响应内容。
- 如果失败,处理错误信息。
要发送JSON数据,可以将数据转换为JSON格式,并设置请求头部的Content-Type为'application/json'。
可以使用Session对象来保持会话状态,以便在多个请求之间共享Cookie。
添加请求头部时,通常需要设置User-Agent来模拟浏览器行为,还可以设置其他自定义头部。
处理响应时,根据需要处理响应内容,例如解析JSON数据或处理文本内容。
好了小伙伴们,今天的学习就到这里了,我们明天再见喽,拜拜!
这篇关于python爬虫———post请求方式(第十四天)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







