本文主要是介绍b站评论词频统计绘制词云图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、评论爬取
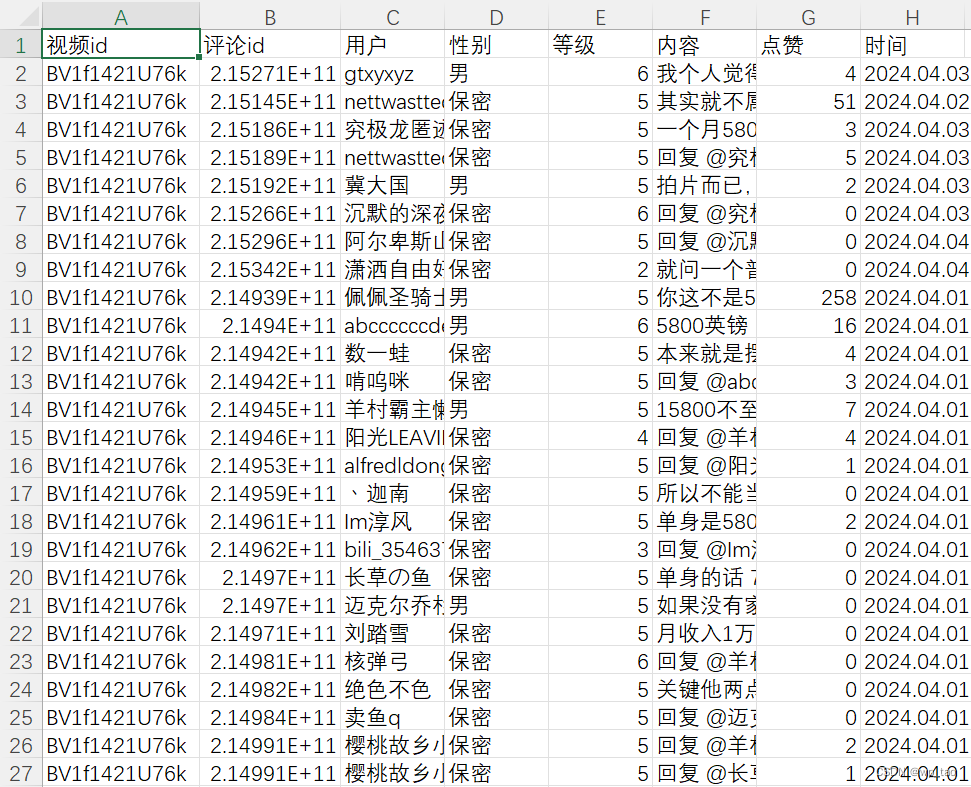
在笔者之前的文章中,已经专门介绍了b站评论的爬取(传送门),这里只对b站评论的文本数据做展示。如下图所示:
二、分词、去停用词、词频统计
Python中的Jieba分词作为应用广泛的分词工具之一,其融合了基于词典的分词方法和基于统计的分词方法的优点,在快速地分词的同时,解决了歧义、未登录词等问题。因而Jieba分词是一个很好的分词工具。Jieba分词工具支持中文简体、中文繁体分词,还支持自定义词库,它支持精确模式、全模式和搜索引擎模式三种分词模式,具体说明如下:
精确模式:试图将语句最精确的切分,不存在冗余数据,适合进行文本分析。
全模式:将语句中所有可能是词的词语都切分出来,速度很快,但是存在冗余数据。
搜索引擎模式:在精确模式的基础上,对长词再次进行切分。
停用词是指在信息检索中,为节省存储空间和提高检索效率,在处理自然语言数据之前或之后,过滤掉某些字或词,在Jieba库中可以自定义停用词。 代码如下:
# 读取停用词,创建停用词表
stwlist = [line.strip() for line in open('stop.txt', encoding='utf8').readlines()]# 文本分词
mytext_list = []
number_list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
words = jieba.lcut(text, cut_all=False)
for seg in words:for i in number_list:seg = seg.replace(str(i), '')if not seg:continueif seg not in stwlist and seg != " " and len(seg) != 1:mytext_list.append(seg)
cloud_text = ",".join(mytext_list)def word_frequency(txt):# 统计并返回每个单词出现的次数word_list = txt.split(',')d = {}for word in word_list:if word in d:d[word] += 1else:d[word] = 1# 删除词频小于2的关键词for key, value in dict(d).items():if value < 2:del d[key]return dfrequency_result = word_frequency(cloud_text)
frequency_result = list(frequency_result.items())
# 对关键词进行排序
frequency_result.sort(key=lambda x: x[1], reverse=True)
# 输出词频统计表
df = pd.DataFrame(frequency_result, columns=['词', '词频'])
df.to_csv('词频统计.csv', encoding='utf-8-sig', index=False)
三、绘制词云图和高频词条形图
词云图,也叫文字云,是对文本中出现频率较高的“关键词”予以视觉化的展现,词云图过滤掉大量的低频低质的文本信息,使得浏览者只要一眼扫过文本就可领略文本的主旨。就是一大堆关键词形成一张图片,有的是矩形有的是一些特殊形状。而WordCloud的作用,就是制作这种图片。这个模块的使用也是非常方便的,我们需要准备一个文本、一张图片、然后填写一堆参数就好了。
接下来,介绍下wordcloud的基本使用。wordcloud把词云当作一个对象,它可以将文本中词语出现的频率作为一个参数绘制词云,而词云的大小、颜色、形状等都是可以设定的。高频词条形图可以让我们对词频的数量级有直观地了解。代码如下:
# 读取背景图片
jpg = imread('Background.jpg')
# 绘制词云
wordcloud = WordCloud(mask=jpg,background_color="white",font_path='msyh.ttf',width=1600,height=1200,margin=20,max_words=50
).generate(cloud_text)
plt.figure(figsize=(15, 9))
plt.imshow(wordcloud)
# 去除坐标轴
plt.axis("off")
# plt.show()
plt.savefig("WordCloud.jpg")#绘制条形图
def bar_toolbox() -> Bar:c = (Bar().add_xaxis(x_data[:10]).add_yaxis("关键词", y_data[:10], stack="stack1").set_series_opts(label_opts=opts.LabelOpts(is_show=False)).set_global_opts(title_opts=opts.TitleOpts(title="高频词条形图"),toolbox_opts=opts.ToolboxOpts(),legend_opts=opts.LegendOpts(is_show=True),xaxis_opts=opts.AxisOpts(name='关键词',name_textstyle_opts=opts.TextStyleOpts(color='red',font_size=20), axislabel_opts=opts.LabelOpts(font_size=15,rotate=45)),yaxis_opts=opts.AxisOpts(name='数量',name_textstyle_opts=opts.TextStyleOpts(color='red',font_size=20),axislabel_opts=opts.LabelOpts(font_size=15,),name_location = "middle")).set_series_opts(label_opts=opts.LabelOpts(position='top',color='black',font_size=15)))return c
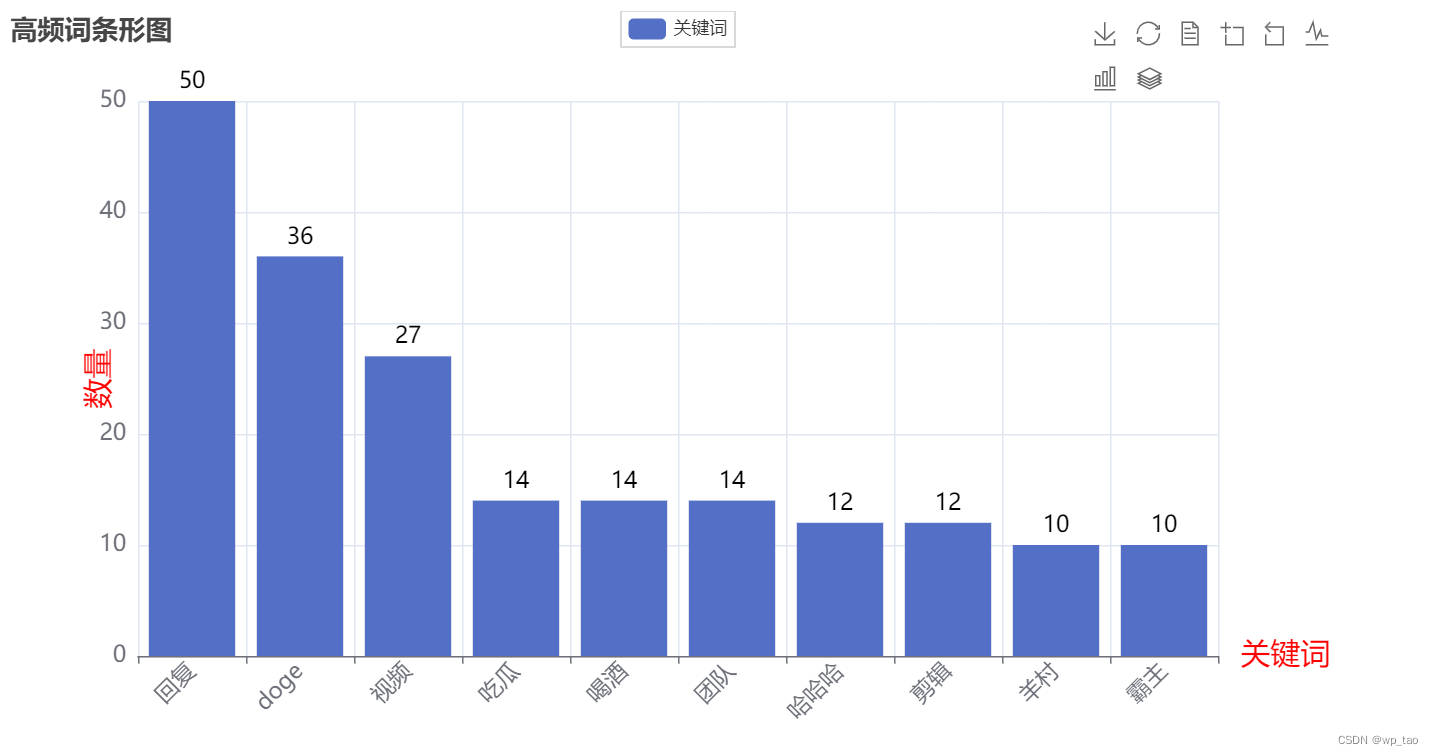
bar_toolbox().render('高频词条形图.html')词云图效果如下:

条形图如下:
四、完整代码
import pandas as pd
import jieba
from imageio.v2 import imread
import matplotlib.pyplot as plt
from pyecharts import options as opts
from pyecharts.globals import SymbolType
from pyecharts.charts import Bar, Page
from wordcloud import WordCloudplt.rcParams['font.sans-serif'] = 'SimHei'df = pd.read_csv('BV1f1421U76k_评论.csv')
text = ''.join(df['内容'])# 读取停用词,创建停用词表
stwlist = [line.strip() for line in open('stop.txt', encoding='utf8').readlines()]# 文本分词
mytext_list = []
number_list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
words = jieba.lcut(text, cut_all=False)
for seg in words:for i in number_list:seg = seg.replace(str(i), '')if not seg:continueif seg not in stwlist and seg != " " and len(seg) != 1:mytext_list.append(seg)
cloud_text = ",".join(mytext_list)def word_frequency(txt):# 统计并返回每个单词出现的次数word_list = txt.split(',')d = {}for word in word_list:if word in d:d[word] += 1else:d[word] = 1# 删除词频小于2的关键词for key, value in dict(d).items():if value < 2:del d[key]return dfrequency_result = word_frequency(cloud_text)
frequency_result = list(frequency_result.items())
# 对关键词进行排序
frequency_result.sort(key=lambda x: x[1], reverse=True)
# 输出词频统计表
df = pd.DataFrame(frequency_result, columns=['词', '词频'])
df.to_csv('词频统计.csv', encoding='utf-8-sig', index=False)# 准备数据
x_data = []
y_data = []
for item in frequency_result:x_data.append(item[0])y_data.append(item[1])# 读取背景图片
jpg = imread('Background.jpg')
# 绘制词云
wordcloud = WordCloud(mask=jpg,background_color="white",font_path='msyh.ttf',width=1600,height=1200,margin=20,max_words=50
).generate(cloud_text)
plt.figure(figsize=(15, 9))
plt.imshow(wordcloud)
# 去除坐标轴
plt.axis("off")
# plt.show()
plt.savefig("WordCloud.jpg")#绘制条形图
def bar_toolbox() -> Bar:c = (Bar().add_xaxis(x_data[:10]).add_yaxis("关键词", y_data[:10], stack="stack1").set_series_opts(label_opts=opts.LabelOpts(is_show=False)).set_global_opts(title_opts=opts.TitleOpts(title="高频词条形图"),toolbox_opts=opts.ToolboxOpts(),legend_opts=opts.LegendOpts(is_show=True),xaxis_opts=opts.AxisOpts(name='关键词',name_textstyle_opts=opts.TextStyleOpts(color='red',font_size=20), axislabel_opts=opts.LabelOpts(font_size=15,rotate=45)),yaxis_opts=opts.AxisOpts(name='数量',name_textstyle_opts=opts.TextStyleOpts(color='red',font_size=20),axislabel_opts=opts.LabelOpts(font_size=15,),name_location = "middle")).set_series_opts(label_opts=opts.LabelOpts(position='top',color='black',font_size=15)))return c
bar_toolbox().render('高频词条形图.html')
这篇关于b站评论词频统计绘制词云图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







