本文主要是介绍GPU CUDA编程中threadIdx, blockIdx, blockDim, gridDim之间的区别与联系,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在启动kernel的时候,要通过指定gridsize和blocksize才行,举下面的例子说说:
dim3 gridsize(2,2);
dim3 blocksize(4,4);
gridsize相当于是一个2*2的block,gridDim.x,gridDim.y,gridDim.z相当于这个dim3的x,y,z方向的维度,这里是2*2*1。序号从0到3,且是从上到下的顺序,就是说是下面的情况:
grid中的blockidx序号标注情况为:
0 21 3
blocksize则是指里面的thread的情况,blockDim.x,blockDim.y,blockDim.z相当于这个dim3的x,y,z方向的维度,这里是4*4*1.序号是0-15,也是从上到下的标注:
block中的threadidx序号标注情况:
0 4 8 12
1 5 9 13
2 6 10 14
4 7 11 15
具体:
threadIdx是一个uint3类型,表示一个线程的索引。
blockIdx是一个uint3类型,表示一个线程块的索引,一个线程块中通常有多个线程。
blockDim是一个dim3类型,表示线程块的大小。
gridDim是一个dim3类型,表示网格的大小,一个网格中通常有多个线程块。
下面这张图比较清晰的表示的几个概念的关系:
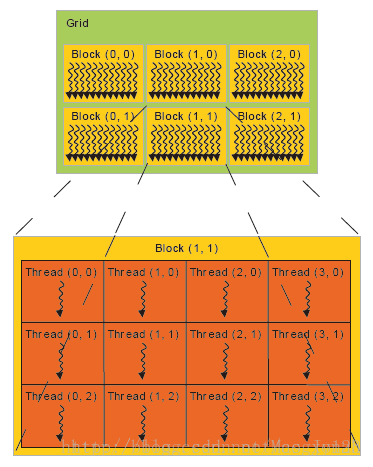
cuda 通过<<< >>>符号来分配索引线程的方式,我知道的一共有15种索引方式。

#include "cuda_runtime.h"
#include "device_launch_parameters.h"#include <stdio.h>
#include <stdlib.h>
#include <iostream>using namespace std;//thread 1D
__global__ void testThread1(int *c, const int *a, const int *b)
{int i = threadIdx.x;c[i] = b[i] - a[i];
}
//thread 2D
__global__ void testThread2(int *c, const int *a, const int *b)
{int i = threadIdx.x + threadIdx.y*blockDim.x;c[i] = b[i] - a[i];
}//thread 3D
__global__ void testThread3(int *c, const int *a, const int *b)
{int i = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;c[i] = b[i] - a[i];
}//block 1D
__global__ void testBlock1(int *c, const int *a, const int *b)
{int i = blockIdx.x;c[i] = b[i] - a[i];
}//block 2D
__global__ void testBlock2(int *c, const int *a, const int *b)
{int i = blockIdx.x + blockIdx.y*gridDim.x;c[i] = b[i] - a[i];
}//block 3D
__global__ void testBlock3(int *c, const int *a, const int *b)
{int i = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;c[i] = b[i] - a[i];
}//block-thread 1D-1D
__global__ void testBlockThread1(int *c, const int *a, const int *b)
{int i = threadIdx.x + blockDim.x*blockIdx.x;c[i] = b[i] - a[i];
}//block-thread 1D-2D
__global__ void testBlockThread2(int *c, const int *a, const int *b)
{int threadId_2D = threadIdx.x + threadIdx.y*blockDim.x;int i = threadId_2D+ (blockDim.x*blockDim.y)*blockIdx.x;c[i] = b[i] - a[i];
}//block-thread 1D-3D
__global__ void testBlockThread3(int *c, const int *a, const int *b)
{int threadId_3D = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;int i = threadId_3D + (blockDim.x*blockDim.y*blockDim.z)*blockIdx.x;c[i] = b[i] - a[i];
}//block-thread 2D-1D
__global__ void testBlockThread4(int *c, const int *a, const int *b)
{int blockId_2D = blockIdx.x + blockIdx.y*gridDim.x;int i = threadIdx.x + blockDim.x*blockId_2D;c[i] = b[i] - a[i];
}//block-thread 3D-1D
__global__ void testBlockThread5(int *c, const int *a, const int *b)
{int blockId_3D = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;int i = threadIdx.x + blockDim.x*blockId_3D;c[i] = b[i] - a[i];
}//block-thread 2D-2D
__global__ void testBlockThread6(int *c, const int *a, const int *b)
{int threadId_2D = threadIdx.x + threadIdx.y*blockDim.x;int blockId_2D = blockIdx.x + blockIdx.y*gridDim.x;int i = threadId_2D + (blockDim.x*blockDim.y)*blockId_2D;c[i] = b[i] - a[i];
}//block-thread 2D-3D
__global__ void testBlockThread7(int *c, const int *a, const int *b)
{int threadId_3D = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;int blockId_2D = blockIdx.x + blockIdx.y*gridDim.x;int i = threadId_3D + (blockDim.x*blockDim.y*blockDim.z)*blockId_2D;c[i] = b[i] - a[i];
}//block-thread 3D-2D
__global__ void testBlockThread8(int *c, const int *a, const int *b)
{int threadId_2D = threadIdx.x + threadIdx.y*blockDim.x;int blockId_3D = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;int i = threadId_2D + (blockDim.x*blockDim.y)*blockId_3D;c[i] = b[i] - a[i];
}//block-thread 3D-3D
__global__ void testBlockThread9(int *c, const int *a, const int *b)
{int threadId_3D = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;int blockId_3D = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;int i = threadId_3D + (blockDim.x*blockDim.y*blockDim.z)*blockId_3D;c[i] = b[i] - a[i];
}void addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{int *dev_a = 0;int *dev_b = 0;int *dev_c = 0;cudaSetDevice(0);cudaMalloc((void**)&dev_c, size * sizeof(int));cudaMalloc((void**)&dev_a, size * sizeof(int));cudaMalloc((void**)&dev_b, size * sizeof(int));cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);testThread1<<<1, size>>>(dev_c, dev_a, dev_b);//testThread1<<<1, size>>>(dev_c, dev_a, dev_b);//uint3 s;s.x = size/5;s.y = 5;s.z = 1;//testThread2 <<<1,s>>>(dev_c, dev_a, dev_b);//uint3 s; s.x = size / 10; s.y = 5; s.z = 2;//testThread3<<<1, s >>>(dev_c, dev_a, dev_b);//testBlock1<<<size,1 >>>(dev_c, dev_a, dev_b);//uint3 s; s.x = size / 5; s.y = 5; s.z = 1;//testBlock2<<<s, 1 >>>(dev_c, dev_a, dev_b);//uint3 s; s.x = size / 10; s.y = 5; s.z = 2;//testBlock3<<<s, 1 >>>(dev_c, dev_a, dev_b);//testBlockThread1<<<size/10, 10>>>(dev_c, dev_a, dev_b);//uint3 s1; s1.x = size / 100; s1.y = 1; s1.z = 1;//uint3 s2; s2.x = 10; s2.y = 10; s2.z = 1;//testBlockThread2 << <s1, s2 >> >(dev_c, dev_a, dev_b);//uint3 s1; s1.x = size / 100; s1.y = 1; s1.z = 1;//uint3 s2; s2.x = 10; s2.y = 5; s2.z = 2;//testBlockThread3 << <s1, s2 >> >(dev_c, dev_a, dev_b);//uint3 s1; s1.x = 10; s1.y = 10; s1.z = 1;//uint3 s2; s2.x = size / 100; s2.y = 1; s2.z = 1;//testBlockThread4 << <s1, s2 >> >(dev_c, dev_a, dev_b);//uint3 s1; s1.x = 10; s1.y = 5; s1.z = 2;//uint3 s2; s2.x = size / 100; s2.y = 1; s2.z = 1;//testBlockThread5 << <s1, s2 >> >(dev_c, dev_a, dev_b);//uint3 s1; s1.x = size / 100; s1.y = 10; s1.z = 1;//uint3 s2; s2.x = 5; s2.y = 2; s2.z = 1;//testBlockThread6 << <s1, s2 >> >(dev_c, dev_a, dev_b);//uint3 s1; s1.x = size / 100; s1.y = 5; s1.z = 1;//uint3 s2; s2.x = 5; s2.y = 2; s2.z = 2;//testBlockThread7 << <s1, s2 >> >(dev_c, dev_a, dev_b);//uint3 s1; s1.x = 5; s1.y = 2; s1.z = 2;//uint3 s2; s2.x = size / 100; s2.y = 5; s2.z = 1;//testBlockThread8 <<<s1, s2 >>>(dev_c, dev_a, dev_b);//uint3 s1; s1.x = 5; s1.y = 2; s1.z = 2;//uint3 s2; s2.x = size / 200; s2.y = 5; s2.z = 2;//testBlockThread9<<<s1, s2 >>>(dev_c, dev_a, dev_b);cudaMemcpy(c, dev_c, size*sizeof(int), cudaMemcpyDeviceToHost);cudaFree(dev_a);cudaFree(dev_b);cudaFree(dev_c);cudaGetLastError();}
int main()
{const int n = 1000;int *a = new int[n];int *b = new int[n];int *c = new int[n];int *cc = new int[n];for (int i = 0; i < n; i++){a[i] = rand() % 100;b[i] = rand() % 100;c[i] = b[i] - a[i];}addWithCuda(cc, a, b, n);for (int i = 0; i < n; i++)printf("%d %d\n", c[i], cc[i]);delete[] a;delete[] b;delete[] c;delete[] cc; return 0;}
参考:https://www.cnblogs.com/rainbow70626/p/6498738.html?utm_source=itdadao&utm_medium=referral
https://www.cnblogs.com/tiandsp/p/9458734.html
这篇关于GPU CUDA编程中threadIdx, blockIdx, blockDim, gridDim之间的区别与联系的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






