本文主要是介绍ES-7.12-官网阅读-ILM-自定义内置ILM策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
官网地址:Tutorial: Customize built-in ILM policies | Elasticsearch Guide [7.12] | Elastic
教程:自定义内置ILM策略(Customize built-in ILM policies)
Elasticsearch包含如下内建ILM 策略:
- logs(日志)
- metrics(指标)
- syntheticc(合成材料?)
Elasctic Agent 用这些策略管理其数据流的支持索引(backing indices),这个教程告诉你如何使用kibana的Index Lifecycle Policies 来基于你应用的性能和弹性,以及保存需求来自定义这些策略;
场景(Scenario)
你想要发送日志文件到Elasticsearch集群目的是能够可视化和分析数据,这些数据有如下保留需求:
- 当你的写入index 达到50GB或者保留了30天,滚动创建(rollover)一个新的索引
- rollover 以后,将索引在热数据层(hot data tier)保留30天;
- rollover 30天后
- 移动index到热数据层(warm data tier)
- 设置副本为1;
- Force merge 多个索引段(segment)以释放已删除文档所使用的空间。
- 滚动90天后删除索引;
先决条件(Prerequisites)
为完成这个教程,你将需要
- 一个有hot和warm数据层的Elasticsearch 集群
- Elasticsearch Service:Elasticsearch Service 上的 Elastic Stack 部署(deployment)默认包含热层,要添加warm层,请编辑您的部署(deployment)并单击添加warm层的容量
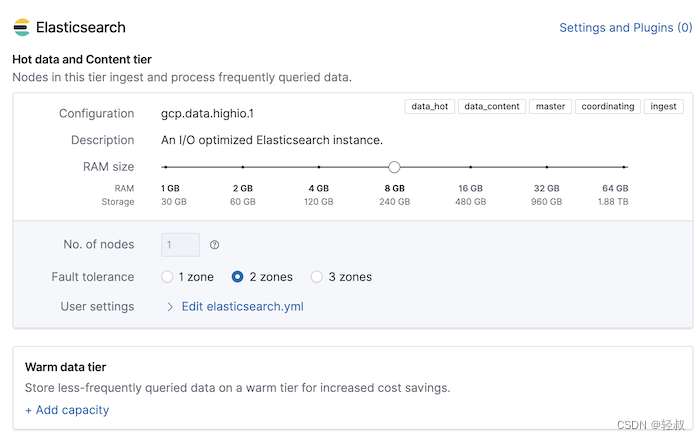
- 自建集群(Self-managed cluster):将data_hot 和data_warm 角色分配给节点,如数据层中(Data tiers | Elasticsearch Guide [7.12] | Elastic)所述;
举例,在warm tier(warm 层)中每个节点的elasticsearch.yml文件中 包含 data_warm节点 角色
node.roles: [ data_warm ]
- 安装了 Elastic Agent 并配置为将日志发送到 Elasticsearch 集群的主机
查看策略(View the policy)
Elastic Agent使用索引模式为logs-*-*的数据流来存储日志监控数据。内置logs ILM 策略自动管理这些数据流的支持索引。
在kibana中访问 logs policy:
- 打开菜单,并去到Stack Management > Index Lifecycle Policies.;
- 选择logs policy;
log policy 使用建议的滚动默认值:当当前写入索引达到 50GB 或变为 30 天时开始写入新索引。
查看或更改rollover设置,点击Hot 阶段的Advanced settings,然后禁用使用推荐的默认值(Use recommended defaults);

修改策略(Modify the policy)
默认logs policy 旨在防止创建许多微小的每日索引。您可以修改策略以满足您的性能要求并管理资源使用情况。
- 激活热阶段并单击Advanced settings.
- 设置Move data into phase when 到 30 days old。这会将index完成rollover以后保留30天后移入到warm 层
- 启用Set replicas 并且改变Number of replicas 为1
- 启用Force merge data 并设置Number of segments为1

- 在warm 阶段,单击垃圾桶图标以启用删除阶段。
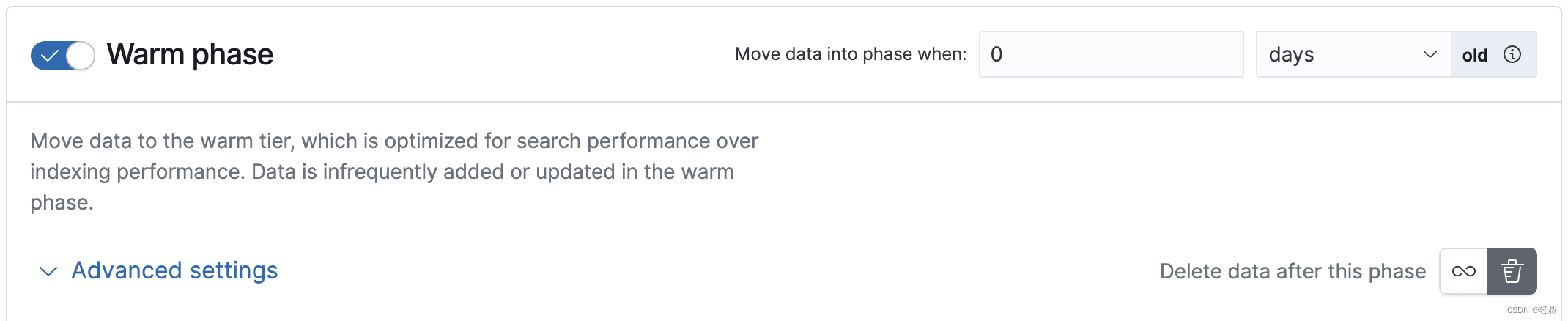
在delete 阶段,设置Move data into phase when to 90 days old. 这会在rollover 90天后删除index;
3. 单击 Save Policy.
这篇关于ES-7.12-官网阅读-ILM-自定义内置ILM策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





