本文主要是介绍结构体与位段的定义以及在内存中的存储,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
结构体的声明
完全声明
不完全声明
结构体变量的定义和初始化
结构体的嵌套
结构体成员的直接访问和间接访问
结构体的自引用
typedef对结构体类型重命名
结构体内存对齐
对齐规则
练习
为什么存在内存对齐
修改默认对齐数
结构体传参
结构体实现位段
位段的内存分配
位段例题
使用位段的注意事项:
总结:
结构是⼀些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量,如:标量、数组、指针,甚至是其他结构体。
结构体的声明
完全声明
描述一个学生:
struct stu {char name[21];char sex[5];char number[12];
};注意结尾的分号不要忘记
不完全声明
在声明结构体的时候也可以不完全的声明
struct
{int a;char b;float c;
}x;struct
{int a;char b;float c;
}a[20], * p;结构体变量的定义和初始化
变量的定义:
struct book {float price;char booknumber[9];}p;
struct book p1;变量的初始化:
struct book {float price;char booknumber[9];}p = { 23.5, "1234-567" };//顺序初始化
struct book p1 = { .booknumber = "1235-589", .price = 20.5 };//指定顺序初始化结构体的嵌套
struct node {float price;char nodenumber[5];
};
struct book {float price;char booknumber[9];struct node n;struct node* a;
};
struct book p = { 19.9f, "1222-345", { 3.5f, "11-33" }, NULL };int main() {printf("%0.1f %s %0.1f %s", p.price, p.booknumber, p.n.price, p.n.nodenumber);return 0;
}结构体成员的直接访问和间接访问
1、直接访问:结构体变量.成员名
struct point {int x;int y;
}p;
int main() {p.x = 20;p.y = 30;printf("%d %d", p.x, p.y);
}2、间接访问:结构体指针 -> 成员名
struct point {int x;int y;
}p = { 20, 30 };
int main() {struct point* ptr = &p;printf("%d %d", ptr->x, ptr->y);
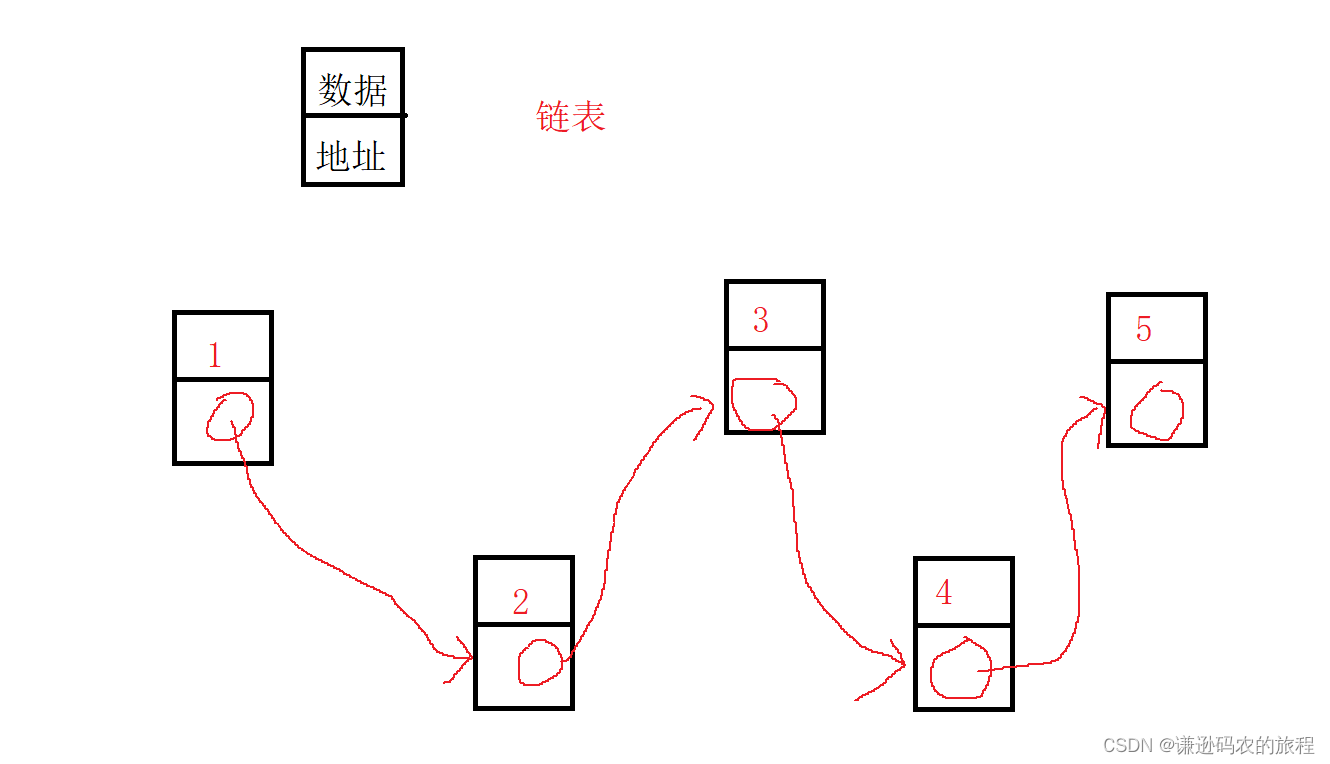
}结构体的自引用
struct Node
{int data;struct Node next;
};struct Node
{int data;struct Node* next;
};
typedef对结构体类型重命名
typedef struct Node
{int data;struct Node* next;
}Node;将struct Node类型重命名为了Node
结构体内存对齐
对齐规则
练习
1、
struct S1
{char c1;int i;char c2;
};
printf("%d\n", sizeof(struct S1));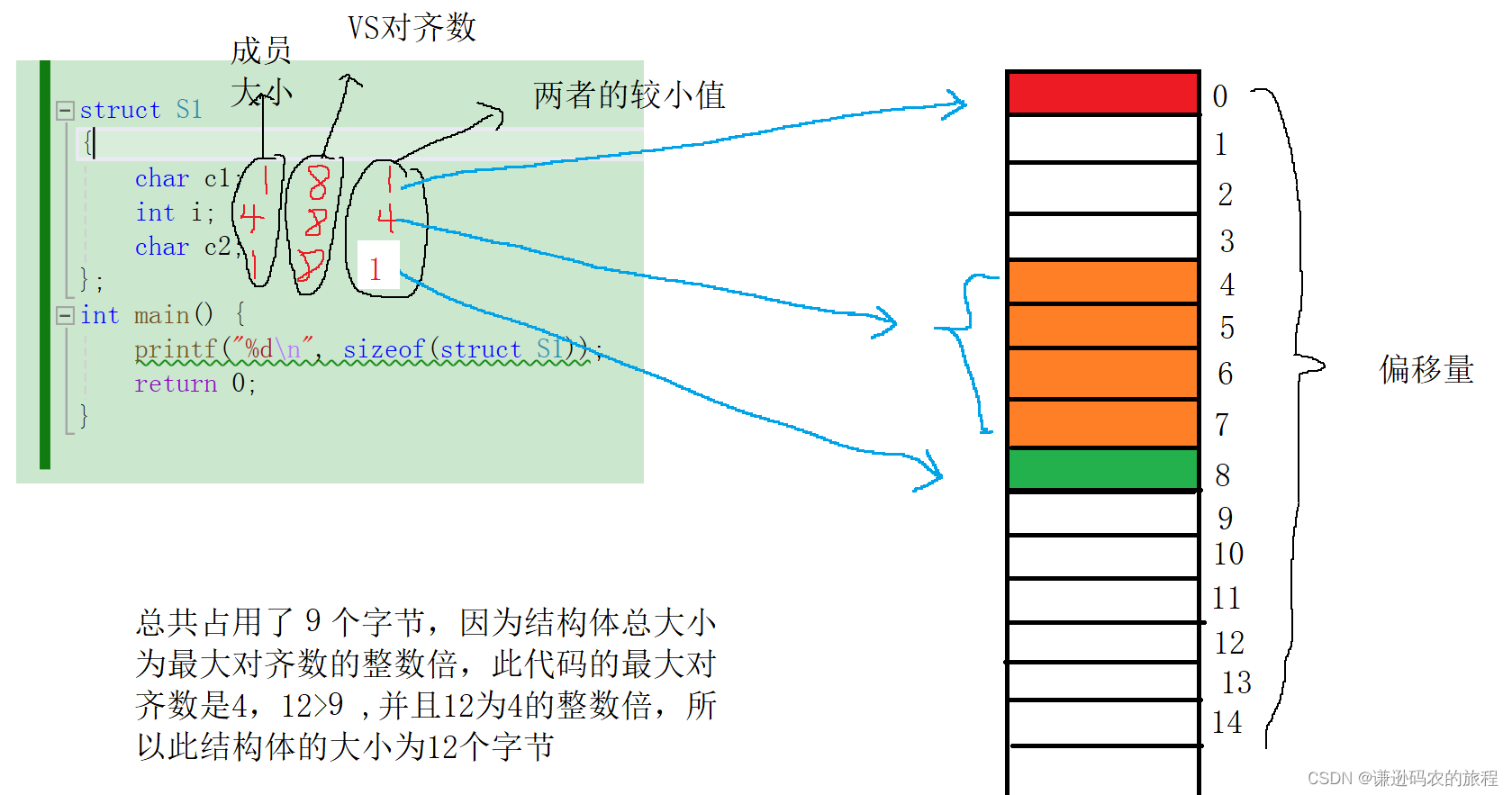
2、 结构体嵌套
struct S1
{char c1;int i;char c2;
};
struct S2
{char c1;struct S1 s1;double d;
};
int main() {printf("%d\n", sizeof(struct S2));return 0;
}
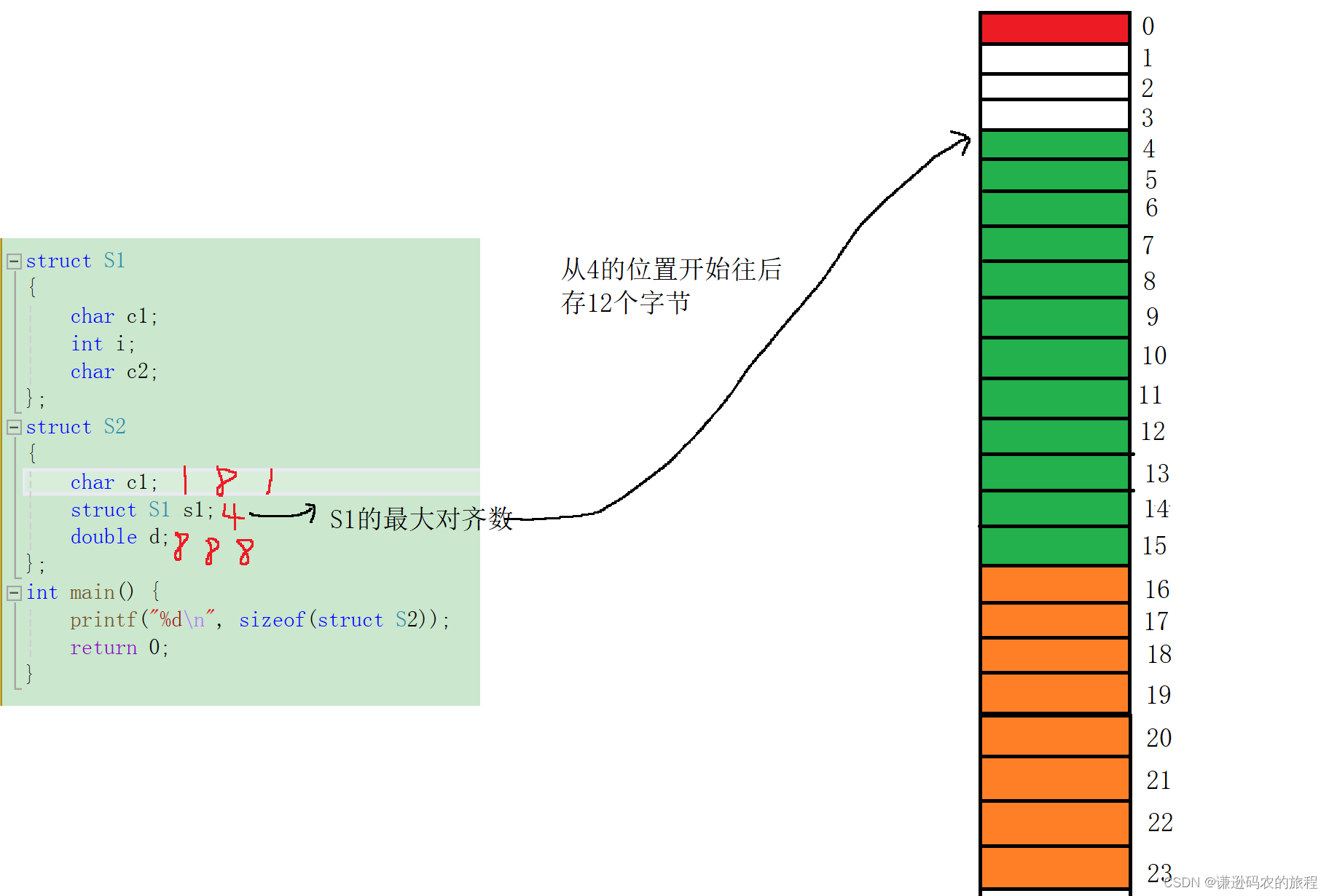
结构体S1的大小由题1可知在内存中占12个字节,由上图可知总共占了24个字节,最大对齐数是8,24是8的倍数,所以结构体S2所占内存的大小为24字节
为什么存在内存对齐
1、平台原因
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2、性能原因
数据结构(尤其是栈)应该尽可能地在⾃然边界上对⻬。原因在于,为了访问未对⻬的内存,处理器需要作两次内存访问;⽽对⻬的内存访问仅需要⼀次访问。假设⼀个处理器总是从内存中取8个字节,则地址必须是8的倍数。如果我们能保证将所有的double类型的数据的地址都对⻬成8的倍数,那么就可以⽤⼀个内存操作来读或者写值了。否则,我们可能需要执⾏两次内存访问,因为对象可能被分放在两个8字节内存块中。
struct S2
{char c1;char c2;int i;
};修改默认对齐数

只占用了6个字节
结构体在对齐式不合适的时候,我们可以自己更改默认对齐数
结构体传参
#include <stdio.h>struct point {int x;int y;
}a;void print(struct point* p) {printf("%d\n", p->x);
}int main() {a.x = 20;print(&a);return 0;
}结构体实现位段
1. 位段的成员必须是 int、unsigned int 或signed int 或者是 char 类型 ,在C99中位段成员的类型也可以 选择其他类型。2. 位段的成员名后边有一个冒号和一个数字(这个数字表示所占的位)。
比如:
struct A
{int a:3;int b:5;int c:8;int d:12;
};位段的内存分配
上述结构体中的位段在内存中的分配如下:
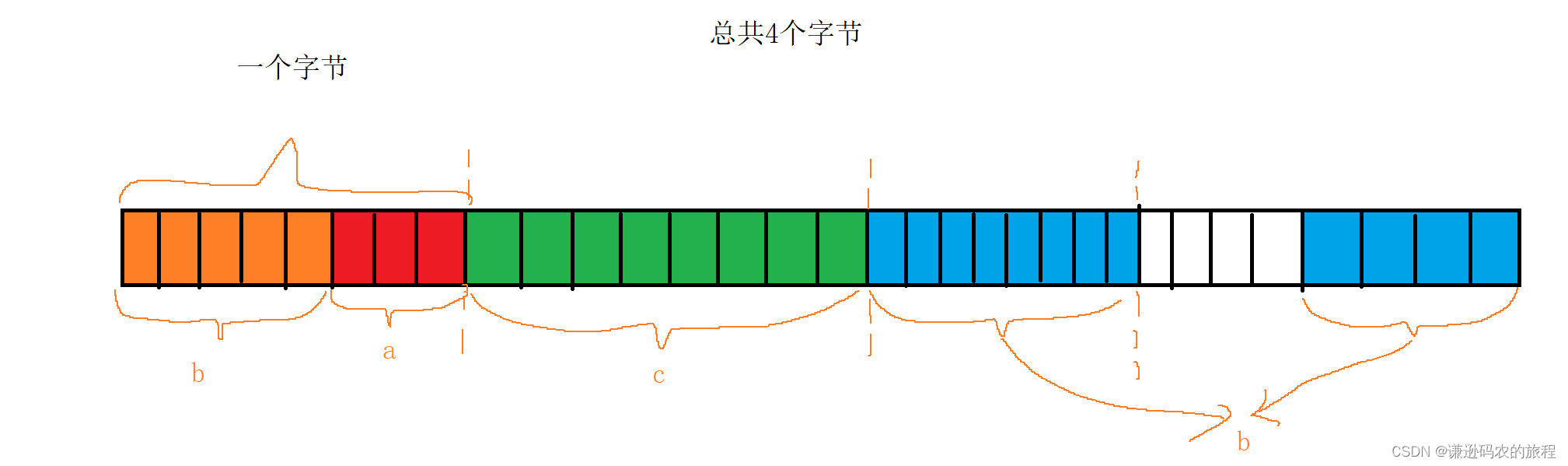
struct A在内存中占了4个字节。
在一个字节中,位是从右往左开始排布,如果一个字节内的所有位排满,则在右边开辟1个字节或4个字节的空间再进行位的排布。
位段例题
#include <stdio.h>
struct S
{char a : 3;char b : 4;char c : 5;char d : 4;
};
struct S s = { 0 };
int main() {s.a = 10;s.b = 12;s.c = 3;s.d = 4;printf("%zd\n", sizeof(struct S));return 0;
}
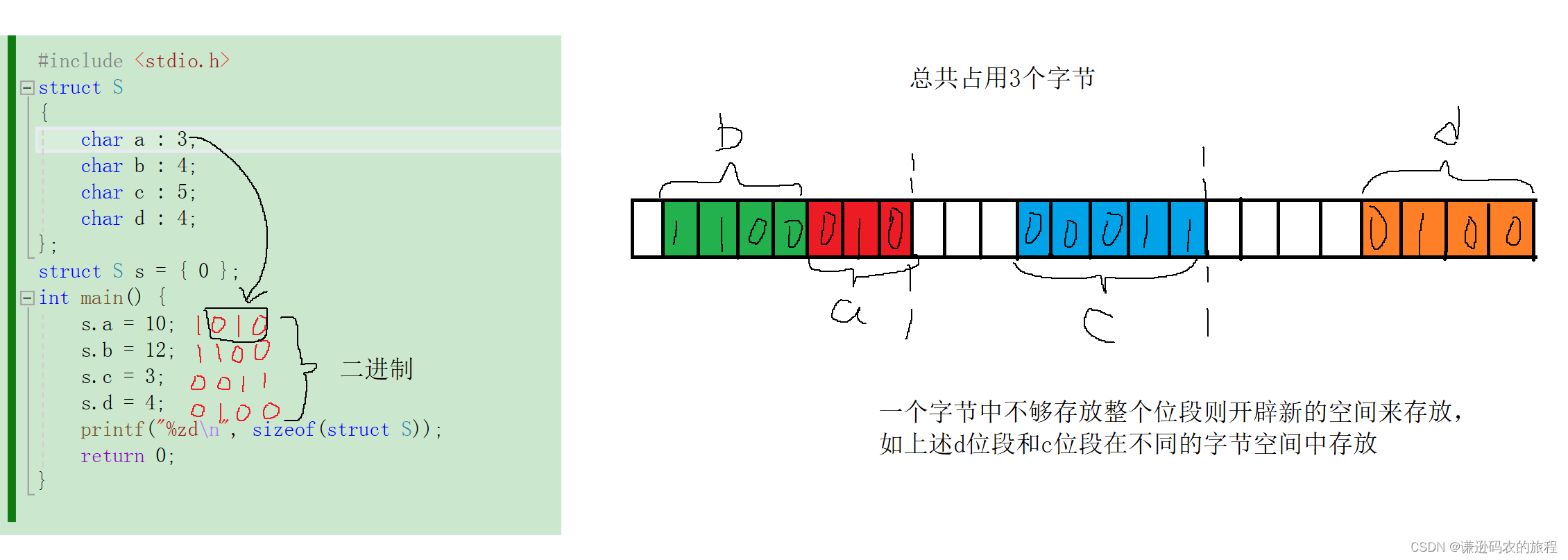
使用位段的注意事项:
总结:
创作不易,感谢支持~~~
这篇关于结构体与位段的定义以及在内存中的存储的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



