本文主要是介绍SQLite3进行数据库各项常用操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 前言
- 1、SQLite介绍
- 2、通过SQLite创建一个数据库文件
- 3、往数据库文件中插入数据
- 4、数据库文件信息查询
- 5、修改数据库中的内容
- 6、删除数据库中的内容
前言
本文是通过轻量化数据库管理工具SQLite进行的基础操作和一些功能实现。
1、SQLite介绍
SQLite是一个广泛使用的嵌入式SQL数据库引擎,以其高可靠性、全功能集、独立性、简单性、易配置和良好的文档而闻名。SQLite通常被用于那些不需要复杂服务器数据库系统的场合,比如移动应用、桌面应用以及只需要单用户访问数据库的场合。
SQLite的特点主要包含:
- 轻量级数据库:SQLite是一个轻量级的数据库库,不是一个完整的数据库系统。它被设计为无需配置、无需服务器的嵌入式SQL数据库引擎。
- 单一文件:SQLite数据库存储在一个单一的磁盘文件中,便于携带、复制和共享。
- 本地存储:常用于设备或应用程序中嵌入式数据库存储需求,如手机应用程序、游戏、个人工具等。
- 不需要独立的服务器过程:SQLite在应用程序进程中运行,不需要配置和管理数据库服务器。
- 用途:适用于轻量级应用、原型开发、教育、小型应用程序等,以及需要简单数据存储但不需要高并发和高性能的场景。

2、通过SQLite创建一个数据库文件
通过代码创建一个数据库文件,我们假设要创建的数据库文件是"mhdata.db"。
如果文件不存在,会自动在当前目录创建。
如果文件已经存在,则会报错提示:
sqlite3.OperationalError: table user already exists
代码显示如下:
import sqlite3
# 连接到SQLite数据库
conn = sqlite3.connect('mhdata.db')
# 创建一个Cursor:
cursor = conn.cursor()
# 执行一条SQL语句,创建user表:
cursor.execute('create table user (id int(10) primary key, name varchar(20))')
# 关闭游标
cursor.close()
# 提交事务:
conn.commit()
# 关闭Connection:
conn.close()
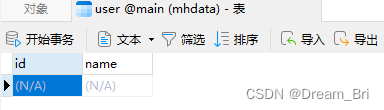
我们通过Navicate Preminm打开就可以看到生成了一个名字为mhdata的表,且有两列,对应的标题分别为id和name,下面的内容为空(因为此时只创建了表和标题,自然是没有内容的)。
3、往数据库文件中插入数据
我们继续使用SQLite往刚才的mhdata.db文件中插入数据,代码如下:
import sqlite3# 如果文件不存在,会自动在当前目录创建:
conn = sqlite3.connect('mhdata.db')
# 创建一个Cursor:
cursor = conn.cursor()# 首先,创建一个名为user的表,如果表已存在,SQL语句不会有任何效果
cursor.execute('''CREATE TABLE IF NOT EXISTS user(id TEXT PRIMARY KEY, name TEXT)''')# 继续执行一条SQL语句,插入一条记录:
cursor.execute('insert into user (id, name) values ("1", "语文")')
cursor.execute('insert into user (id, name) values ("2", "数学")')
cursor.execute('insert into user (id, name) values ("3", "英语")')
cursor.execute('insert into user (id, name) values ("4", "物理")')
cursor.execute('insert into user (id, name) values ("5", "化学")')# 关闭游标
cursor.close()
# 提交事务:
conn.commit()
# 关闭Connection:
conn.close()
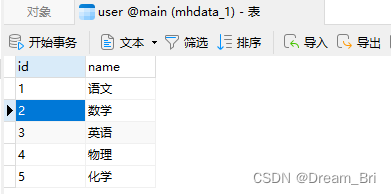
执行代码后,就在mhdata.db表格中插入了5条数据。
我们将mhdata.db表格中数据可视化展示如下:
注: 关于cursor.execute(‘’‘CREATE TABLE IF NOT EXISTS user (id TEXT PRIMARY KEY, name TEXT)’‘’)的含义解释:
- CREATE TABLE IF NOT EXISTS: 这是SQL命令的一部分,用来创建一个新的表。IF NOT EXISTS是一个条件子句,它确保命令只在名为user的表不存在时执行。如果表已经存在,SQL操作将不会做任何事情,以此避免覆盖或报错。
- user: 这是要创建的表的名称。
- (id TEXT PRIMARY KEY, name TEXT): 这是定义表的结构的部分。在这个括号内,我们定义了表中的列及其数据类型:
- id TEXT: 这指创建一个名为id的列,用来存储文本类型的数据。
- PRIMARY KEY: 这个关键词指定id列是表的主键,意味着这个列的值必须唯一,不能重复。主键通常用来唯一地识别表中的每一行记录。
- name TEXT: 这指创建另一个名为name的列,同样用来存储文本数据。
- 综上,这条SQL语句的作用是确保在数据库中存在一个名为user的表,其中包含id(主键)和name这两个文本类型的列,从而后续的插入操作能够正常执行。
4、数据库文件信息查询
这里我们查询下刚才生成的mhdata.db文件,注意要让查询的mhdata.db文件和我们的.py在同一个目录下面,或者是指定查询目录。
可以执行查询的代码如下:
import sqlite3
# 连接到SQLite数据库,数据库文件是mhdata.db
# 可以在这里修改路径
conn = sqlite3.connect('mhdata.db')
# 创建一个Cursor:
cursor = conn.cursor()
# 执行查询语句:
cursor.execute('select * from user')
# 获取查询结果:
result1 = cursor.fetchall()
print(result1)# 关闭游标
cursor.close()
# 关闭Connection:
conn.close()
我们查看下执行后的结果:
[('1', '语文'), ('2', '数学'), ('3', '英语'), ('4', '物理'), ('5', '化学')]
我们结合上面第三节的显示可以看出两者的结果保持一致。
5、修改数据库中的内容
我们修改上面mhdata.db中的某一条数据内容,如将(“1”,“语文”)改成(“1”,“生物”),那么执行代码如下:
import sqlite3
# 连接到SQLite数据库,数据库文件是mhdata.db
conn = sqlite3.connect("mhdata.db")
# 创建一个Cursor:
cursor = conn.cursor()
cursor.execute('update user set name = ? where id = ?',('生物',1))
cursor.execute('select * from user')
result = cursor.fetchall()
print(result)
# 关闭游标
cursor.close()
# 提交事务
conn.commit()
# 关闭Connection:
conn.close()
执行后的结果展示为:
[('1', '生物'), ('2', '数学'), ('3', '英语'), ('4', '物理'), ('5', '化学')]
由此可见达到我们要修改其中某一条数据的目的,如果想一次修改多条数据,可以参照( 3、往数据库文件中插入数据),直接多次执行cursor.execute()语句即可。
6、删除数据库中的内容
经过刚才的修改操作,现在我们删除数据库文件中的(“1”,“生物”),执行代码如下:
import sqlite3
# 连接到SQLite数据库,数据库文件是 mhdata.db
conn = sqlite3.connect("mhdata.db")
# 创建一个Cursor:
cursor = conn.cursor()
cursor.execute('delete from user where id = ?',(1,))
cursor.execute('select * from user')
result = cursor.fetchall()
print(result)
# 关闭游标
cursor.close()
# 提交事务
conn.commit()
# 关闭Connection:
conn.close()
执行后的结果展示:
[('2', '数学'), ('3', '英语'), ('4', '物理'), ('5', '化学')]
到这里,基本完成了用SQLite3进行数据库的基本操作,包含:数据库文件的建立,数据插入、数据查询、数据修改和数据删除的基本操作。
博主还将另外一个基于本篇博客的升级版发布如下:一个程序解决SQLite常见的各项操作
这篇关于SQLite3进行数据库各项常用操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




