本文主要是介绍FreeRTOS从代码层面进行原理分析(5 对实时性的探究),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
FreeRTOS 的实时性是如何做到的?又有多实时?
前面我们用了 4 篇博客对 FreeRTOS 是如何建立任务的 和 FreeRTOS 是调度和切换任务 进行了探索,又把 FreeRTOS 移植到了大学时期买的古早 STM32 开发板上的方式对了解到的原理进行验证。
FreeRTOS从代码层面进行原理分析(1 任务的建立)
FreeRTOS从代码层面进行原理分析(2 任务的启动)
FreeRTOS从代码层面进行原理分析(3 任务的切换)
FreeRTOS从代码层面进行原理分析(4 移植)
对于 FreeRTOS 是如何保证实时性 这一问题,通过前面的博客,想必目前我们心里已经有了大概了。
其保证实时性的理由就是利用了 Systime 中断作为任务切换的时间片。
在官方的介绍中有这么一句话,说明实时性操作系统需要保证的是在规定时间内完成切换任务的响应。

那么问题来了,严格定义的时间究竟是多少时间呢? 那就让我们在 Cortex-m3 架构的 STM32F103RCT6 单片机上来验证一下时间。
————————————————我是分隔符———————————————————————————
任务切换所需的时间
官网教程中正好有能体现这一时间的图片,就是下图的红色部分。
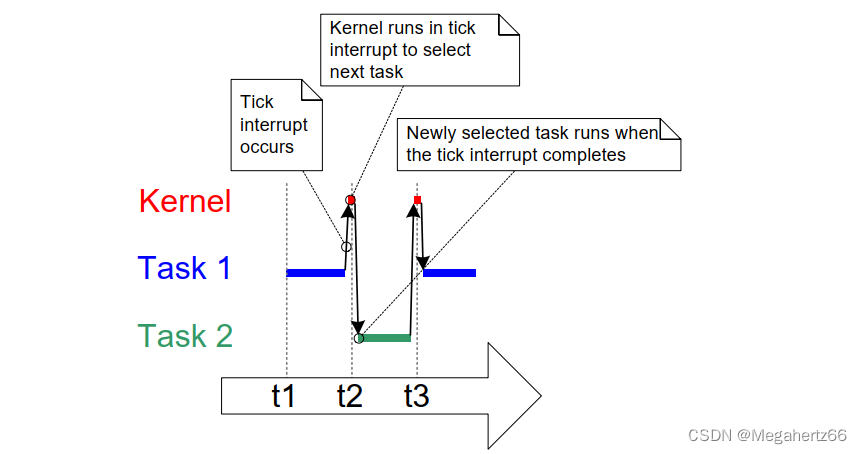
计算栈切换时间的办法,我打算采取使用 systick Current 寄存器的值进行估算。

在前面的博客介绍过 FreeRTOS 任务切换的原理,就是利用 Systick 引发的中断对任务进行判断,挑选出合适的任务,在将新任务上已经存好的值恢复到当前栈上面去,然后跳转到新的任务上执行。
那么,只要我们在跳进 Systick 中断时读取 SysTick Current Value 寄存器的值,然后再跳到任务的时候也读取一次 SysTick Current Value 寄存器的值,它们相减就大约是一个任务切换所需要的时间了。这个值不会特别特别精确,但是作为我们实际参考肯定是够够的了(也欢迎大家提出不同意见,还有什么情况下会导致切换上下文时间出现较大变化)。
在前面移植 FreeRTOS 的时候的代码就是简单的创建了两个优先级相同的任务。
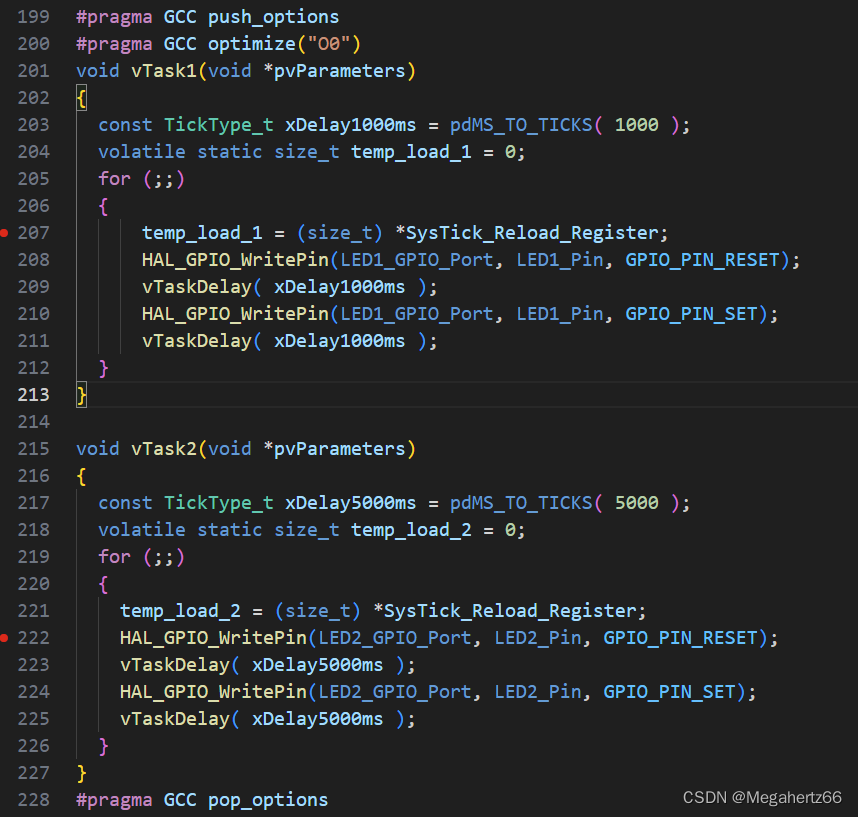
代码的上面和下面加的参数是为了防止编译器对里面的函数优化,迷惑我们的目的~
编译,烧录,然后在这两个函数内部和 systick 中断中打上断点(调试手段这里介绍)。

在进入 systick 中断和进入任务的时候都打印 SysTick Current Value 寄存器的值,用于计算任务切换时间。
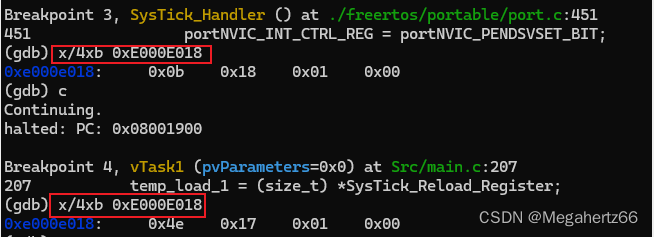
好了~ 现在我们已经得到了 SysTick Current Value 寄存器的差值。
0x180b - 0x174e = 0xBD == 189
再确认一下咱们的时钟配置:
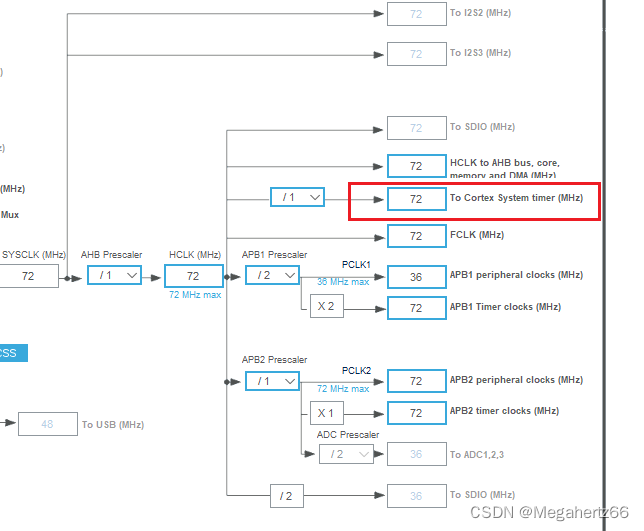
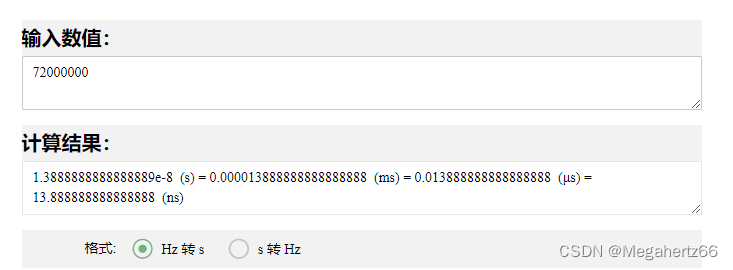
72MHZ = 72000000HZ 约等于 13.89ns
上面的咱们已经知道了切换一共使得 SysTick Current Value 寄存器减少了 189 次。
189 * 13.89ns 约等于 2,625 ns 约等于 2.6μs
总结
经过我们对代码的调试得出了切换任务需要 2.6μs的这个结论, 但是实际上 FreeRTOS 在 Cortex-m3 架构的 STM32F103RCT6 配置 72MHZ 时钟的情况下,切换任务的时间实际要小于这个 2.6μs 的,因为两个断点间,还是可能还是执行到了一条到多跳的代码~ 但是让我们大致忽略这些,因为这个时间已经足够小了。
举个好玩的例子~
目前这个世界上飞行时速最快的飞机X-43A速度极限是9.6马赫。大约每秒钟可以飞行3公里(是不是到这里感觉很快?)
每毫秒还能飞行3米。
但是!每微妙只能飞行3毫米。
2.6μs 只能让这个怪物飞行 7.8毫米,乖乖!!


这篇关于FreeRTOS从代码层面进行原理分析(5 对实时性的探究)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








