本文主要是介绍flink on yarn-per job源码解析、flink on k8s介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Flink 架构概览–JobManager

JobManager的功能主要有:
- 将 JobGraph 转换成 Execution Graph,最终将 Execution Graph 拿来运行
- Scheduler 组件负责 Task 的调度
- Checkpoint Coordinator 组件负责协调整个任务的 Checkpoint,包括 Checkpoint 的开始和完成
- 通过 Actor System 与 TaskManager 进行通信
- 其它的一些功能,例如 Recovery Metadata,用于进行故障恢复时,可以从 Metadata 里面读取数据。
Flink 架构概览–TaskManager

TaskManager 是负责具体任务的执行过程,在 JobManager 申请到资源之后开始启动。TaskManager 里面的主要组件有:
- Memory & I/O Manager,即内存 I/O 的管理
- Network Manager,用来对网络方面进行管理
- Actor system,用来负责网络的通信
TaskManager 被分成很多个 TaskSlot,每个任务都要运行在一个 TaskSlot 里面,TaskSlot 是调度资源里的最小单位。
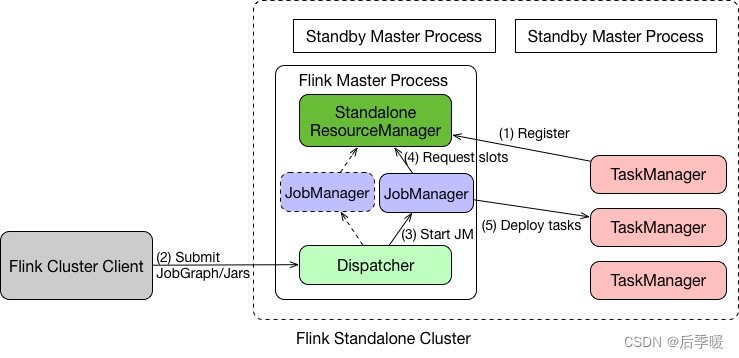
在介绍 Yarn 之前先简单的介绍一下 Flink Standalone 模式,这样有助于更好地了解 Yarn 和 Kubernetes 架构。
- 在 Standalone 模式下,Master 和 TaskManager 可以运行在同一台机器上,也可以运行在不同的机器上。
- 在 Master 进程中,Standalone ResourceManager 的作用是对资源进行管理。当用户通过 Flink Cluster Client 将 JobGraph 提交给 Master 时,JobGraph 先经过 Dispatcher。
- 当 Dispatcher 收到客户端的请求之后,生成一个 JobManager。接着 JobManager 进程向 Standalone ResourceManager 申请资源,最终再启动 TaskManager。
- TaskManager 启动之后,会有一个注册的过程,注册之后 JobManager 再将具体的 Task 任务分发给这个 TaskManager 去执行。
以上就是一个 Standalone 任务的运行过程。
Flink on Yarn 原理及实践
Yarn 架构原理–总览
Yarn 模式在国内使用比较广泛,基本上大多数公司在生产环境中都使用过 Yarn 模式。首先介绍一下 Yarn 的架构原理,因为只有足够了解 Yarn 的架构原理,才能更好的知道 Flink 是如何在 Yarn 上运行的。

Yarn 的架构原理如上图所示,最重要的角色是 ResourceManager,主要用来负责整个资源的管理,Client 端是负责向 ResourceManager 提交任务。
用户在 Client 端提交任务后会先给到 Resource Manager。Resource Manager 会启动 Container,接着进一步启动 Application Master,即对 Master 节点的启动。当 Master 节点启动之后,会向 Resource Manager 再重新申请资源,当 Resource Manager 将资源分配给 Application Master 之后,Application Master 再将具体的 Task 调度起来去执行。
Yarn 架构原理–组件
Yarn 集群中的组件包括:
- ResourceManager (RM):ResourceManager (RM)负责处理客户端请求、启动/监控 ApplicationMaster、监控 NodeManager、资源的分配与调度,包含 Scheduler 和 Applications Manager。
- ApplicationMaster (AM):ApplicationMaster (AM)运行在 Slave 上,负责数据切分、申请资源和分配、任务监控和容错。
- NodeManager (NM):NodeManager (NM)运行在 Slave 上,用于单节点资源管理、AM/RM通信以及汇报状态。
- Container:Container 负责对资源进行抽象,包括内存、CPU、磁盘,网络等资源。
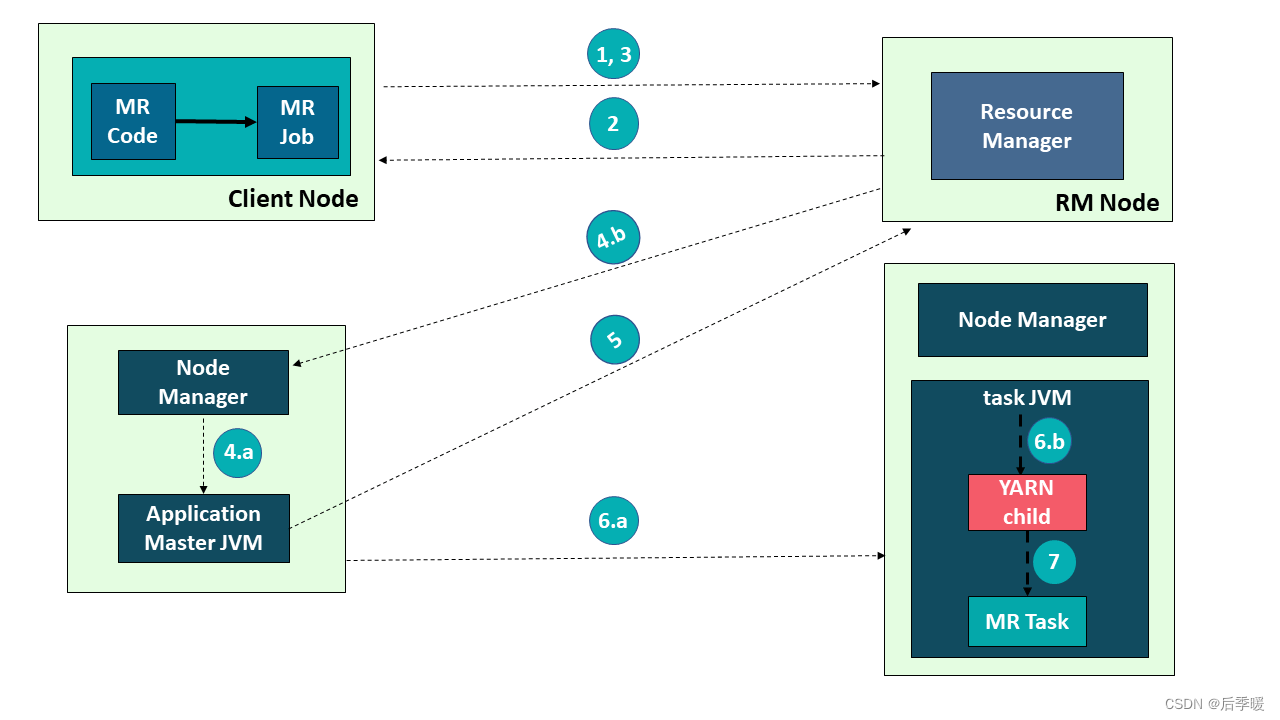
以在 Yarn 上运行 MapReduce 任务为例来讲解下 Yarn 架构的交互原理:
- 首先,用户编写 MapReduce 代码后,通过 Client 端进行任务提交
- ResourceManager 在接收到客户端的请求后,会分配一个 Container 用来启动 ApplicationMaster,并通知 NodeManager 在这个 Container 下启动 ApplicationMaster。
- ApplicationMaster 启动后,向 ResourceManager 发起注册请求。接着 ApplicationMaster 向 ResourceManager 申请资源。根据获取到的资源,和相关的 NodeManager 通信,要求其启动程序。
- 一个或者多个 NodeManager 启动 Map/Reduce Task。
- NodeManager 不断汇报 Map/Reduce Task 状态和进展给 ApplicationMaster。
- 当所有 Map/Reduce Task 都完成时,ApplicationMaster 向 ResourceManager 汇报任务完成,并注销自己。
Flink on Yarn–Per Job
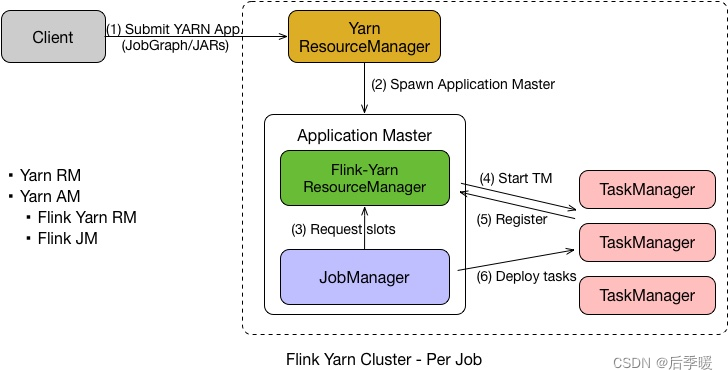
Flink on Yarn 中的 Per Job 模式是指每次提交一个任务,然后任务运行完成之后资源就会被释放。在了解了 Yarn 的原理之后,Per Job 的流程也就比较容易理解了,具体如下:
- 首先 Client 提交 Yarn App,比如 JobGraph 或者 JARs。
- 接下来 Yarn 的 ResourceManager 会申请第一个 Container。这个 Container 通过 Application Master 启动进程,Application Master 里面运行的是 Flink 程序,即 Flink-Yarn ResourceManager 和 JobManager。
- 最后 Flink-Yarn ResourceManager 向 Yarn ResourceManager 申请资源。当分配到资源后,启动 TaskManager。TaskManager 启动后向 Flink-Yarn ResourceManager 进行注册,注册成功后 JobManager 就会分配具体的任务给 TaskManager 开始执行。
Flink on Yarn–Session
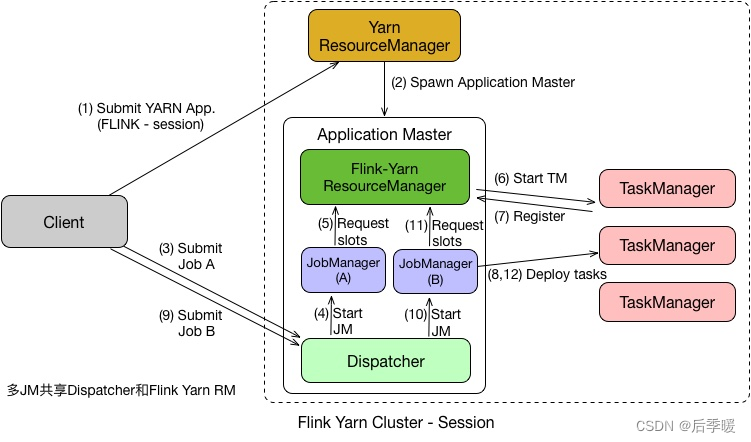
在 Per Job 模式中,执行完任务后整个资源就会释放,包括 JobManager、TaskManager 都全部退出。而 Session 模式则不一样,它的 Dispatcher 和 ResourceManager 是可以复用的。Session 模式下,当 Dispatcher 在收到请求之后,会启动 JobManager(A),让 JobManager(A) 来完成启动 TaskManager,接着会启动 JobManager(B) 和对应的 TaskManager 的运行。当 A、B 任务运行完成后,资源并不会释放。Session 模式也称为多线程模式,其特点是资源会一直存在不会释放,多个 JobManager 共享一个 Dispatcher,而且还共享 Flink-YARN ResourceManager。
Session 模式和 Per Job 模式的应用场景不一样。Per Job 模式比较适合那种对启动时间不敏感,运行时间较长的任务。Seesion 模式适合短时间运行的任务,一般是批处理任务。若用 Per Job 模式去运行短时间的任务,那就需要频繁的申请资源,运行结束后,还需要资源释放,下次还需再重新申请资源才能运行。显然,这种任务会频繁启停的情况不适用于 Per Job 模式,更适合用 Session 模式。
接下来细讲一下perjob模式。
YARN job工作流程
- Client向ResourceManager提交应用程序(包含启动ApplicationMaster的命令)。
- ResourceManager为应用分配第一个Container并与对应的NodeManager通信要求它启动ApplicationMaster。
- ApplicationMaster向ResourceManager注册并与ResourceManager保持心跳。
- ApplicationMaster为任务的运行向ResourceManager申请若干Container资源。
- ApplicationMaster领取ResourceManager分配的Container并初始化相关运行信息,便与对应的NodeManager通信要求它启动Container。
- NodeManager为Container设置好运行环境(下载运行资源、设置环境变量、资源限制等),将启动命令写到脚本文件中,运行脚本启动Container。
- Container运行期间向ApplicationMaster汇报自己的状态和任务进度。
- 应用程序运行完成后,ApplicationMaster向ResourceManager申请注销自己,释放相关Container资源。
用户程序什么时候、在哪、谁调用执行的?
入口示例程序
是一个Stream job
./bin/flink run -t yarn-per-job --detached ./examples/streaming/TopSpeedWindow这篇关于flink on yarn-per job源码解析、flink on k8s介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






