本文主要是介绍cdn缓存加速---varnish,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
环境,
server2 172.25.254.2
server3 172.25.254.3
server4 172.25.254.4
server2作varnish服务器
varnish介绍
Varnish是一款开源的、高性能的HTTP加速器和反向代理服务器
最主要的功能就是:通过缓存来实现Web访问加速
Varnish特点是主要基于内存或者是虚拟内存进行缓存,性能好 支持设置精确的缓存时间 VCL配置管理比较灵活 后端服务器的负载均衡和健康检查
varnish安装
www.varnish-cache.org
从官网下载varnish6.3或者6.4 的rpm包
安装时提示需要jemalloc.x86_64 0:3.6.0-1.el7这个包的依赖性,这是一个用来管理内存的软件。
配置文件
他的配置文件是这些
default.vcl 我们将来用于编写vcl语法的
varnish-x86_64.conf 是配置文件
varnish是环境变量信息
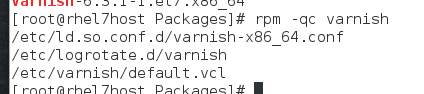
他的启动脚本是 /usr/lib/systemd/system/varnish.service
查看启动脚本:
最大打开文件数:

查看我们系统中的最大打开文件数
sysctl -a |grep file

最大打开文件数为97764个,不够我们varnish 使用,我们可以加大内存或者更改 varnish 配置文件。
内存改为2G;

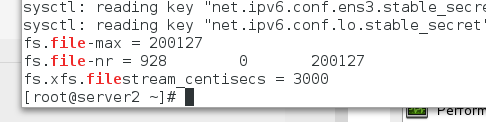
开机后发现可打开文件数增大了,满足varnish需求了。
内存锁定,运行varnish时需要折磨多内存:

大概82M
查看我们系统中的进程限制
ulimit -a
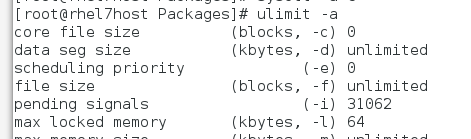
可见最大为64M.我们需要进行设定
可并行的任务数:

没有限制。
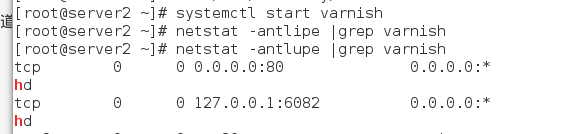
默认端口:

更改为:

因为我们要用它做一个反向代理,要作缓存,而且用户不知道6081端口,所以用户直接用http访问缓存服务器。
-T 可以让我们使用命令行去管理varnish
保存退出。
然后更改 /etc/security/limits.conf
让系统允许我们的varnish以这样的内存区运行。

然后我们启动 varnish
启动成功且80端口打开,我们在火湖浏览器访问

说明我们的varnish正常的只是没有数据,那我们配置一些数据。
vim /etc/varnish/default.vcl

这里要注意 backend default 的作用是:
当你访问varnish时,会把你的请求转交给 本地的回环接口, 8080 端口
我们改为:

,就让在访问varnish时,把请求转交给172.25.254.3这台主机,相当于反向代理,
然后我们在这台主机上安装http 就有80端口了
我们给他创建一个index页面:

然后重启varnish,刷新firefox:
我们就看到的是172.25.254.3的内容了,可见请求已经被调度到了 172.25.254.3
ps aux

可以看到varnish开启了两个进程,一个manager 进程,负责读取进程的各项进程,并监控子进程
一个child进程,这个才是真实的处理用户请求的进程
查看manager进程的信息:
cat /proc/17532/status

threads = 1 ,可以看出只有一个线程,说明manager进程之监控子进程,没有处理用户请求,这些都由子进程来处理。
cat /proc/17542/status
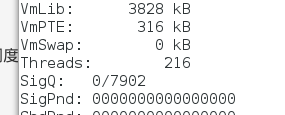
threads = 216 ,说明子进程是用于处理的进程。
varnish命令行
varnishadm 可以进入varnish的命令行

缓存内容
vim /etc/varnish/default.vcl
在里面的deliver 模块进行编辑,内容如下:

sub vcl_deliver {
if (obj.hits > 0) {
set resp.http.X-Cache = "HIT from westos cache"; #命中缓存返回这句话
}
else {
set resp.http.x-Cache = "MISS from westos cache"; #如果不是,返回这句话
}
return (deliver);这段代码可以让我们知道是否从缓存中获取, #vcl语法可以从官方文档中获取用法。
重启varnish,
测试:
curl -I 172.25.254.2

到数第三行可以看出命中了缓存。第一次会miss,因为cdn中也没有数据,第二次访问时就会从缓存中获取。
如果内容有更新时,我们需要更新缓存,这时,我们可以手动清除缓存。
varnishadm ban req.url "~" / 表示清空所有缓存,/代表所有
varnishadm ban req.url "~" /index.html 表示清空这个页面的缓存,
# 和上面的不同,清理后curl -I 172.25.254.2 不会miss,因为并没有清空全部的缓存。
# curl -I 172.25.254.2/index.html 才会 MISS 。
表示清空我们的缓存,默认的自动晴空缓存的时间为120S。

看第一行和最后一行,可知已经清空了缓存。
不同域名分配不同后端
当我门的请求过多时,一台后端主机无法应付,这好似我们就可以定义多个后端进行反向代理:

并设置 sub vcl_recv :
sub vcl_recv {# Happens before we check if we have this in cache already.## Typically you clean up the request here, removing cookies you don't need,# rewriting the request, etc.
if (req.http.host ~ "^(www.)?westos.org") {
set req.http.host = "www.westos.org";
set req.backend_hint = web1; #www.westos.org 对应 web1
}
elsif (req.http.host ~ "^bbs.westos.org") {
set req.backend_hint = web2; #bbs.westos.org 对应 web1
} else {return (synth(405));
}
}
# 不同的主机设置不同的域名
重启varnish,
在物理机上做好本地解析:

然后在 172.25.254.3 和172.25.254.4 上建立index.html 文件
echo www.westos.com > /var/www/html/index.html 3
echo bbs.wesots.org > /var/www/html/index.html
测试访问:
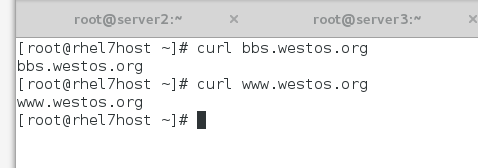
可见内容分发给不同的后端成功。
定义负载均衡
cdn作为访问的调度点需要做负载均衡
#可以查看相关手册
man vcl
man varnishadm
man vmod_directors
我们需要导入 /usr/lib64/varnish/vmods/libvmod_directors.so 模块才能激活负载均衡

vim /etc/varnish/default.vcl
写到这个位置:

导入后我们去man vmos_directors查询如何去写配置来激活负载均衡:

使用round_robin轮巡的负载均衡模式,我们负载均衡器起名为 lb ,更改 后端服务器名称web1 web2

然后更改 vcl_recv:
就是当我们访问www.westos.com 时 就会轮询的去访问web1 和web2, 当访问 bbs.westos.org 时会访问web2。
重启服务,测试:
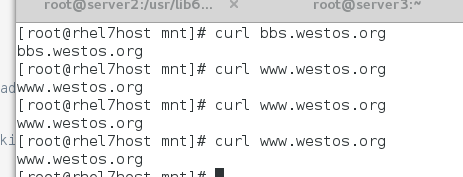
测试的时候访问www.westos.org 却没有轮询访问两台后端,这是为什么那?
因为我们的cdn是缓存,第一次读取后结下来的读取都是从缓存中获取,所以没有轮询访问。
那我们让缓存不生效在试一次:

加上return这一行表示不缓存,那我们继续测试:
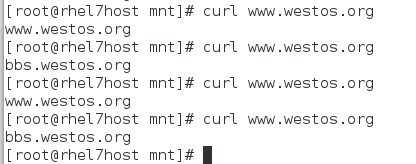

每次都是MISS,就代表不从缓存读取。
这次就达到了我们的负载均衡的需求了.
或者我们每次都手动的清理一次缓存:
varnishadm ban req.url "~" /
这样清理缓存对于企业是有门槛的,所以我们可以用图形界面操作。
安装httpd 和php
安装bansys软件:
unzip bansys.zip -d /var/www/html -d解压到目录,因为我们要发布它

更改 config.php,定义varnish主机:

配制成这个样子,因为我们没有作数据库,所以数据库的一些配置我们删除。
更改httpd的端口为8080,因为varnish占用了80端口:

重启httpd,测试访问:

可以使用。使用HTTP方式
我们需要设置一个权限,只对特定ip推送:
vim /etc/varnish/default.vcl
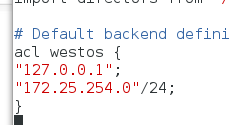

if (req.method == "BAN") { #判断是否要清除缓存
if (!client.ip ~ westos) { ##如果ip和westos定义的ip不匹配,告知不允许return(synth(405,"Not allowed"));
}
ban("req.url ~ " + req.url); #否则清楚return (purge);
}重启服务,
查看我们是否有缓存;

命中缓存,则有。
我们推送 .* 表示清楚所有缓存。

然后我们在访问:

就又变成了MISS 了。
我们还可以推送 index.html,他不影响整体缓存,清空后只有/index.html 是MISS form cache

现在两个的缓存都存在,
推送:
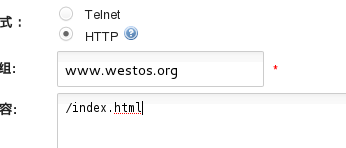
然后再次访问:

只有index.html MISS 了。
总结
从 varnish-book 总结流程:

各个模块的功能:
| vcl_recv : | 接受用户的请求,并进行查询 |
| vcl_hash: | 在recv之后被调用,用来请求创建hash值,作用是在varnish中查找key值。 |
- hit函数 缓存查找成功时调用的,进入pass模块或者deliver模块
- pass函数 进入通道模式请求的,不经过缓存,进入pass模块
- hit-for-pass函数 进入pass模块
- miss函数 未命中缓存,进入miss模块,在进入后端查询模块(vcl_backend_fetch)
- purge函数 用于清空缓存
- pipe函数 在管道模式中使用,进入vcl_pipe 模块,子进程,可以使请求直接传送到后端,通常用于大数据的传输
- busy函数 在varnish繁忙的时侯 进入waiting模块
| vcl_backend_response: | 接受 |
| vcl_beresp动作: | 读取请求头,如果缓存没有,进入vcl_backend_error 模块,有就进入response模块,准备响应请求。 |
| cacheabel动作: | 询问是否缓存数据,因为比如用户的密码是不允许缓存的 |
| vcl_deliver: | 将数据结果返回给客户端 |
| done: | 返回给客户端后结束 |
这篇关于cdn缓存加速---varnish的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



