本文主要是介绍#include<初见C语言之指针(5)>,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、sizeof和strlen的对比
1. sizeof
2.strlen
二、数组和指针题解析
1. ⼀维数组
1.1数组名理解
2.字符数组
3. ⼆维数组
三、指针运算题解析
总结
一、sizeof和strlen的对比
1. sizeof
我们前面介绍过sizeof是单目操作符

- sizeof括号中有表达式,不计算
- 计算变量所占内存空间大小(字节),类型,用类型创建所占内存大小
- 只关注占用内存空间的大小,不在乎内存存放什么数据
2.strlen

- 统计\0之前的字符个数
- 关注是否有\0,没有会持续的找,可能会越界
二、数组和指针题解析
1. ⼀维数组
1.1数组名理解
数组名是数组首元素(第一个元素)的地址
有两个例外:
1.sizeof(数组名)- 数组名表示整个数组,计算的是整个数组的大小,单位字节
2.&数组名- 数组名表示整个数组,取出的是整个数组的地址
代码1
int main()
{int a[] = { 1,2,3,4 };printf("%d\n", sizeof(a));printf("%d\n", sizeof(a + 0));printf("%d\n", sizeof(*a));printf("%d\n", sizeof(a + 1));printf("%d\n", sizeof(a[1]));printf("%d\n", sizeof(&a));printf("%d\n", sizeof(*&a));printf("%d\n", sizeof(&a + 1));printf("%d\n", sizeof(&a[0]));printf("%d\n", sizeof(&a[0] + 1));
}解析:
//int main()
//{
// int a[] = { 1,2,3,4 };//数组有几个元素?4
//
// printf("%zd\n", sizeof(a));//16 -- sizeof(数组名)的场景
// printf("%zd\n", sizeof(a + 0));//a是首元素的地址-类型是int*,a+0还是首元素的地址,是地址大小就是4/8
// printf("%zd\n", sizeof(*a));//a是首元素的地址-*a就是首元素,大小就是4个字节
// //*a == a[0] == *(a+0)
// printf("%zd\n", sizeof(a + 1));//a是首元素的地址-类型是int*,a+1跳过1个整型,a+1就是第二个元素的地址,是地址大小就是4/8
// printf("%zd\n", sizeof(a[1]));//a[1]就是第二个元素,大小4个字节
// printf("%zd\n", sizeof(&a));//&a整个数组地址,数组的地址也是地址,也是地址大小就是4/8个字节
// printf("%zd\n", sizeof(*&a));//1.*&互相抵消了,sizeof(*&a)==sizeof(a)是整个数组的大小16字节
// //2.&a是数组的地址,类型是int(*)[4],对数组指针解引用访问的是数组,计算的是数组大小16字节
// //
// printf("%zd\n", sizeof(&a + 1));//&a+1跳过整个数组后的地址,是地址就是4/8个字节
// printf("%zd\n", sizeof(&a[0]));//首元素的地址,,是地址大小就是4/8个字节
// printf("%zd\n", sizeof(&a[0] + 1));//&a[0]+1是数组第二个元素的地址,是地址就是4/8个字节
//
// return 0;
//}
2.字符数组
代码1
int main()
{char arr[] = { 'a','b','c','d','e','f' };printf("%d\n", sizeof(arr));printf("%d\n", sizeof(arr + 0));printf("%d\n", sizeof(*arr));printf("%d\n", sizeof(arr[1]));printf("%d\n", sizeof(&arr));printf("%d\n", sizeof(&arr + 1));printf("%d\n", sizeof(&arr[0] + 1));
}解析:
//int main()
//{
// char arr[] = { 'a','b','c','d','e','f' };
//
// printf("%d\n", sizeof(arr));//数组名单独放在sizeof内部了,计算的是数组的大小6个字节
// printf("%d\n", sizeof(arr + 0));//arr是数组名表示首元素的地址,arr+0还是首元素的地址,是地址就是4/8个字节
// printf("%d\n", sizeof(*arr));//arr首元素的地址,*arr就是首元素,大小就是1个字节
// //*arr -arr[0]--*arr(arr+0)
// printf("%d\n", sizeof(arr[1]));//arr[1] 是第二个元素,大小也是1个字节
// printf("%d\n", sizeof(&arr));//&arr是数组的地址,数组的地址也是地址,大小是4/8个字节
// //&arr--char(*)[6]
// printf("%d\n", sizeof(&arr + 1));//&arr + 1跳过整个数组后的地址,指向了数组后面的空间大小是4/8个字节
// printf("%d\n", sizeof(&arr[0] + 1));//&arr[0] + 1第二个元素的地址,4/8个字节
//
// return 0;
//}
代码2
int main()
{char arr[] = { 'a','b','c','d','e','f' };printf("%d\n", strlen(arr));printf("%d\n", strlen(arr + 0));printf("%d\n", strlen(*arr));printf("%d\n", strlen(arr[1]));printf("%d\n", strlen(&arr));printf("%d\n", strlen(&arr + 1));printf("%d\n", strlen(&arr[0] + 1));
}解析:
//int main()
//{
// char arr[] = { 'a','b','c','d','e','f' };
//
// printf("%d\n", strlen(arr));//arr是首元素的地址,数组中没有\0,就会导致越界访问,结果就是随机的
// printf("%d\n", strlen(arr + 0));//arr+0,也是数组首元素的地址,数组中没有\0,就会导致越界访问,结果就是随机
// //printf("%d\n", strlen(*arr));//arr是首元素地址,*arr是首元素,就是‘a’,‘a’的ascii码值是97
// //就相当于把97作为地址传递给了strlen,strlen得到的就是野指针,代码有问题
// //printf("%d\n", strlen(arr[1]));//arr[1]--'b'--98,传给strlen函数也是错误的
// printf("%d\n", strlen(&arr));//&arr是数组的地址,起始位置是数组的第一个元素的位置,随机值
// printf("%d\n", strlen(&arr + 1));//&arr + 1随机值
// printf("%d\n", strlen(&arr[0] + 1));//从第二个元素开始向后统计,得到也是随机值
//
// return 0;
//}
代码3
int main()
{char arr[] = "abcdef";printf("%d\n", sizeof(arr));printf("%d\n", sizeof(arr + 0));printf("%d\n", sizeof(*arr));printf("%d\n", sizeof(arr[1]));printf("%d\n", sizeof(&arr));printf("%d\n", sizeof(&arr + 1));printf("%d\n", sizeof(&arr[0] + 1));
}解析:
//int main()
//{
// char arr[] = "abcdef";//a b c d e f \0
//
// printf("%d\n", sizeof(arr));//arr是数组名,单独放在sizeof内部,计算的是数组总大小,是7个字节
// printf("%d\n", sizeof(arr + 0));//arr表示数组首元素地址,arr+0还是首元素的地址,4/8个字节
// printf("%d\n", sizeof(*arr));//arr表示数组首元素的地址,*arr就是首元素,大小是1字节
// printf("%d\n", sizeof(arr[1]));//arr[1]是第二个元素,大小是1个字节
// printf("%d\n", sizeof(&arr));//&arr是数组的地址,4/8个字节
// printf("%d\n", sizeof(&arr + 1));//&arr+1跳过整个数组,4/8个字节
// printf("%d\n", sizeof(&arr[0] + 1));//第二个元素的地址,4/8个字节
//
// return 0;
//
//}
代码4:
int main()
{char arr[] = "abcdef";printf("%d\n", strlen(arr));printf("%d\n", strlen(arr + 0));printf("%d\n", strlen(*arr));printf("%d\n", strlen(arr[1]));printf("%d\n", strlen(&arr));printf("%d\n", strlen(&arr + 1));printf("%d\n", strlen(&arr[0] + 1));
}解析:
//int main()
//{
// char arr[] = "abcdef";//abcdef\0
//
// printf("%d\n", strlen(arr));//arr是首元素地址 6个字节
// printf("%d\n", strlen(arr + 0));//arr+0还是首元素的地址,向后在\0之前有6字节
// //printf("%d\n", strlen(*arr));//'a'-97,出错
// //printf("%d\n", strlen(arr[1]));//'b'-98,出错
// printf("%d\n", strlen(&arr));//&arr是数组的地址,6个字节
// //&arr -- char (*)[7]
// //size_t strlen(const cahr *s)
// printf("%d\n", strlen(&arr + 1));//&arr+1跳过一个数组的地址,随机值
// printf("%d\n", strlen(&arr[0] + 1));//&arr[0]+1跳过一个元素,5
//
//
// return 0;
//}
代码5:
int main()
{char* p = "abcdef";printf("%d\n", sizeof(p));printf("%d\n", sizeof(p + 1));printf("%d\n", sizeof(*p));printf("%d\n", sizeof(p[0]));printf("%d\n", sizeof(&p));printf("%d\n", sizeof(&p + 1));printf("%d\n", sizeof(&p[0] + 1));
}解析:
//int main()
//{
// const char* p = "abcdef";
//
// printf("%d\n", sizeof(p));//p是指针变量,我们计算的是指针变量的大小,4/8个字节
// printf("%d\n", sizeof(p + 1));//p+1是b的地址,4/8个字节
// printf("%d\n", sizeof(*p));//p的类型是const char*,*p就是char类型,1个字节
//
// printf("%d\n", sizeof(p[0]));//1.p[0] --> *(p+0) -->'a',1个字节
// //2.把常量字符串想象成数组,p可以理解为数组名,p[0]首元素
// printf("%d\n", sizeof(&p));//取出的是p的地址,4/8个字节
// printf("%d\n", sizeof(&p + 1));//&p+1是跳过p指针变量后的地址,4/8个字节
// printf("%d\n", sizeof(&p[0] + 1));//&p[0]-取出字符串首字符的地址,+1是第二个字符的地址,4/8个字节
//
// return 0;
//}
代码6:
int main()
{char* p = "abcdef";printf("%d\n", strlen(p));printf("%d\n", strlen(p + 1));printf("%d\n", strlen(*p));printf("%d\n", strlen(p[0]));printf("%d\n", strlen(&p));printf("%d\n", strlen(&p + 1));printf("%d\n", strlen(&p[0] + 1));
}
解析:
//代码6
//int main()
//{
// char* p = "abcdef";
//
// printf("%d\n", strlen(p));//6个字节
// printf("%d\n", strlen(p + 1));//5个
// //printf("%d\n", strlen(*p));//*p就是'a'-97,err
// //printf("%d\n", strlen(p[0]));//p[0]-->*(p+0)-->*p//err
// printf("%d\n", strlen(&p));//&p是指针变量p的地址,和字符串"abcdef"没有关系
// //从p这个指针变量的起始位置开始往后数,p变量存放的地址是什么,不知道,所以答案是随机值
// printf("%d\n", strlen(&p + 1));//&p + 1与&p没有关系,随机值
// printf("%d\n", strlen(&p[0] + 1));//5
//
// return 0;
//}
3. ⼆维数组
代码:
int main()
{int a[3][4] = { 0 };printf("%d\n", sizeof(a));printf("%d\n", sizeof(a[0][0]));printf("%d\n", sizeof(a[0]));printf("%d\n", sizeof(a[0] + 1));printf("%d\n", sizeof(*(a[0] + 1)));printf("%d\n", sizeof(a + 1));printf("%d\n", sizeof(*(a + 1)));printf("%d\n", sizeof(&a[0] + 1));printf("%d\n", sizeof(*(&a[0] + 1)));printf("%d\n", sizeof(*a));printf("%d\n", sizeof(a[3]));
}解析:
//int main()
//{
// int a[3][4] = { 0 };
//
// printf("%d\n", sizeof(a));//a是数组名,单独放在sizeof内部,计算的是数组的大小,单位是字节 - 48=3*4*sizeof(int)
// printf("%d\n", sizeof(a[0][0]));//a[0][0]是第一行第一个元素4个字节
// printf("%d\n", sizeof(a[0]));//a[0]第一行的数组名,数组名单独放在sizeof内部了,计算的是数组总的大小16个字节
//
// printf("%d\n", sizeof(a[0] + 1));//a[0]第一行的数组名,但是a[0]并没有单独放在sizeof内部
// //所以这里的数组名a[0]就是数组首元素的地址,就是a[0][0],+1后是a[0][1]的地址,4/8
//
// printf("%d\n", sizeof(*(a[0] + 1)));//*(a[0] + 1)表示第一行第二个元素,4
// printf("%d\n", sizeof(a + 1));//a作为数组名并没有单独放在sizeof内部,a表示数组首元素的地址,
// //是二维数组首元素的地址,也就是第一行的地址,a+1跳过一行,指向第二行,a+1是第二行的地址,a+1是数组指针,4/8
//
// printf("%d\n", sizeof(*(a + 1)));//1.a+1就是第二行的地址,*(a+1)就是第二行,计算的是第二行的大小 - 16
// //2.*(a + 1) == a[1],a[1]是第二行的数组名,sizeof(*(a+1))就相当于sizeof(a[1]),意思是把第二行数组名放在sizeof内部,计算的是第二行的大小 - 16
// printf("%d\n", sizeof(&a[0] + 1));//a[0]是第一行的数组名,&a[0]取出的就是数组的地址,就是第一行的地址
// //&a[0]+1,就是第二行的地址,4/8
//
// printf("%d\n", sizeof(*(&a[0] + 1)));//*(&a[0] + 1))对第二行的地址解引用,访问的就是第二行,大小,16
// printf("%d\n", sizeof(*a));//1.a作为数组名并没有单独放在sizeof内部,a表示数组首元素的地址,是二维数组首元素的地址
// //也就是第一行的地址,*a就是第一行,计算的就是第一行的大小,16
// //2 *a == *(a+0) == a[0]
// printf("%d\n", sizeof(a[3]));//a[3]无需真实存在,仅仅通过类型的推断就能算长度
// //a[3]是第四行的数组名,单独放在sizeof内部,计算的是第四行的大小,16
//1
// sizeof(int);//4
// sizeof(3 + 5);//4
// return 0;
//}
三、指针运算题解析
代码1:
include <stdio.h>
int main()
{int a[5] = { 1, 2, 3, 4, 5 };int *ptr = (int *)(&a + 1);printf( "%d,%d", *(a + 1), *(ptr - 1));return 0;
}
//程序的结果是什么?
解析:
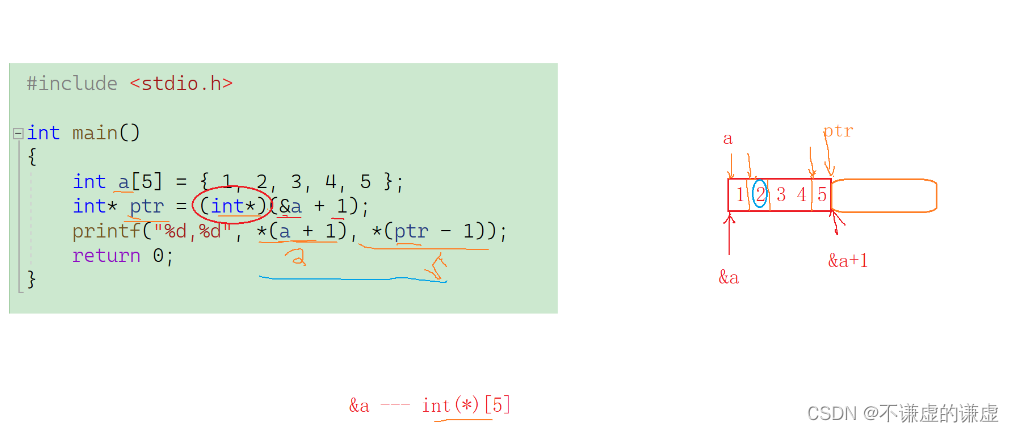
代码2:
//在X86(32)环境下
//假设结构体的⼤⼩是20个字节
//程序输出的结果是啥?
struct Test
{int Num;char* pcName;short sDate;char cha[2];short sBa[4];
}*p = (struct Test*)0x100000;int main()
{printf("%p\n", p + 0x1);printf("%p\n", (unsigned long)p + 0x1);printf("%p\n", (unsigned int*)p + 0x1);return 0;
}
解析:

代码3:
int main()
{int a[3][2] = { (0, 1), (2, 3), (4, 5) };//初始化识别正确int* p;p = a[0];printf("%d", p[0]);return 0;
}解析:

代码4:
//假设环境是x86环境,程序输出的结果是啥?
#include <stdio.h>
int main()
{int a[5][5];int(*p)[4];p = a;printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);return 0;
}解析:

代码5:
#include <stdio.h>
int main()
{int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };int *ptr1 = (int *)(&aa + 1);int *ptr2 = (int *)(*(aa + 1));printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1));return 0;
}
解析:

代码6:
#include <stdio.h>
int main()
{char *a[] = {"work","at","alibaba"};char**pa = a;pa++;printf("%s\n", *pa);return 0;
}
解析:
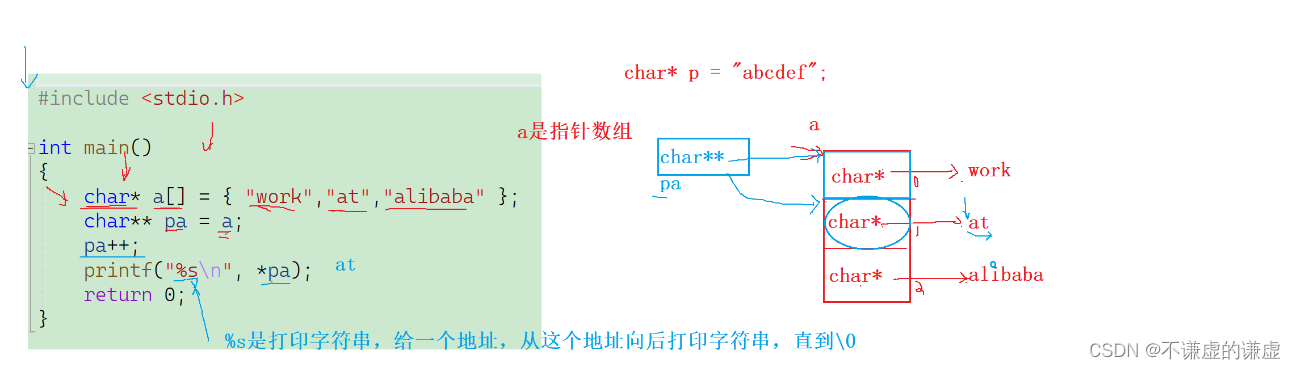
代码7:
int main()
{char *c[] = {"ENTER","NEW","POINT","FIRST"};char**cp[] = {c+3,c+2,c+1,c};char***cpp = cp;printf("%s\n", **++cpp);printf("%s\n", *--*++cpp+3);printf("%s\n", *cpp[-2]+3);printf("%s\n", cpp[-1][-1]+1);return 0;
}
解析:


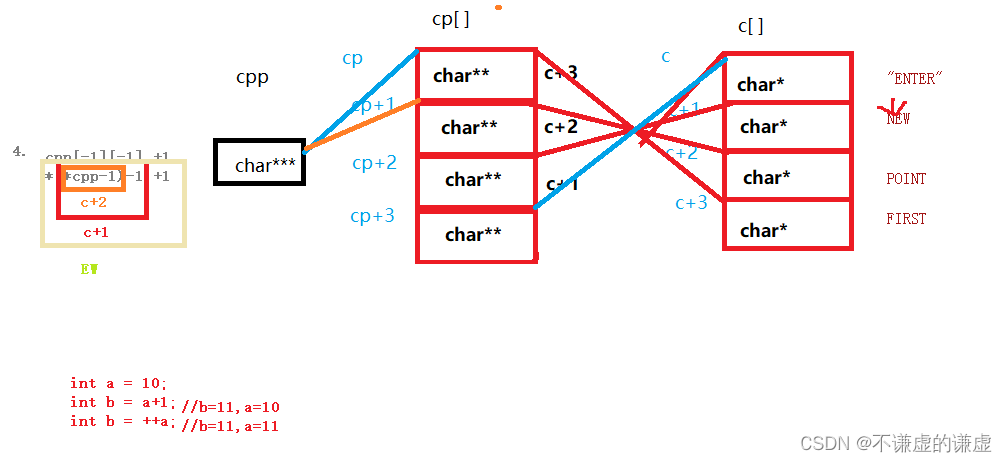
总结
这篇是指针的第五小结主要是在sizeof和strlen中指针是占多大内存的,学到这里,指针的知识就算结束了。
这篇关于#include<初见C语言之指针(5)>的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




