本文主要是介绍华为开源自研AI框架昇思MindSpore应用案例:梯度累加,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一、环境准备
- 1.进入ModelArts官网
- 2.使用CodeLab体验Notebook实例
- 二、案例实现
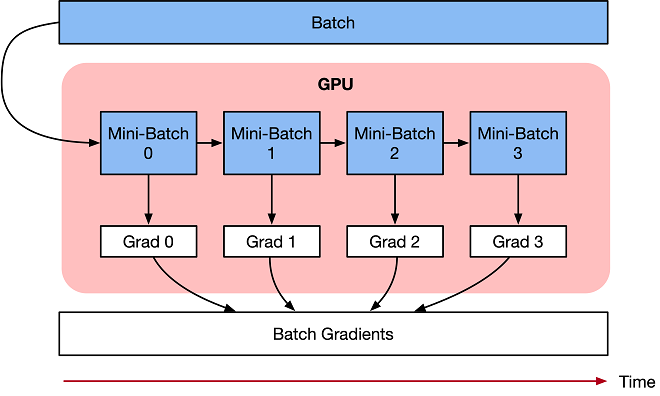
梯度累加的训练算法,目的是为了解决由于内存不足,导致Batch size过大神经网络无法训练,或者网络模型过大无法加载的OOM(Out Of Memory)问题。
如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
一、环境准备
1.进入ModelArts官网
云平台帮助用户快速创建和部署模型,管理全周期AI工作流,选择下面的云平台以开始使用昇思MindSpore,获取安装命令,安装MindSpore2.0.0-alpha版本,可以在昇思教程中进入ModelArts官网
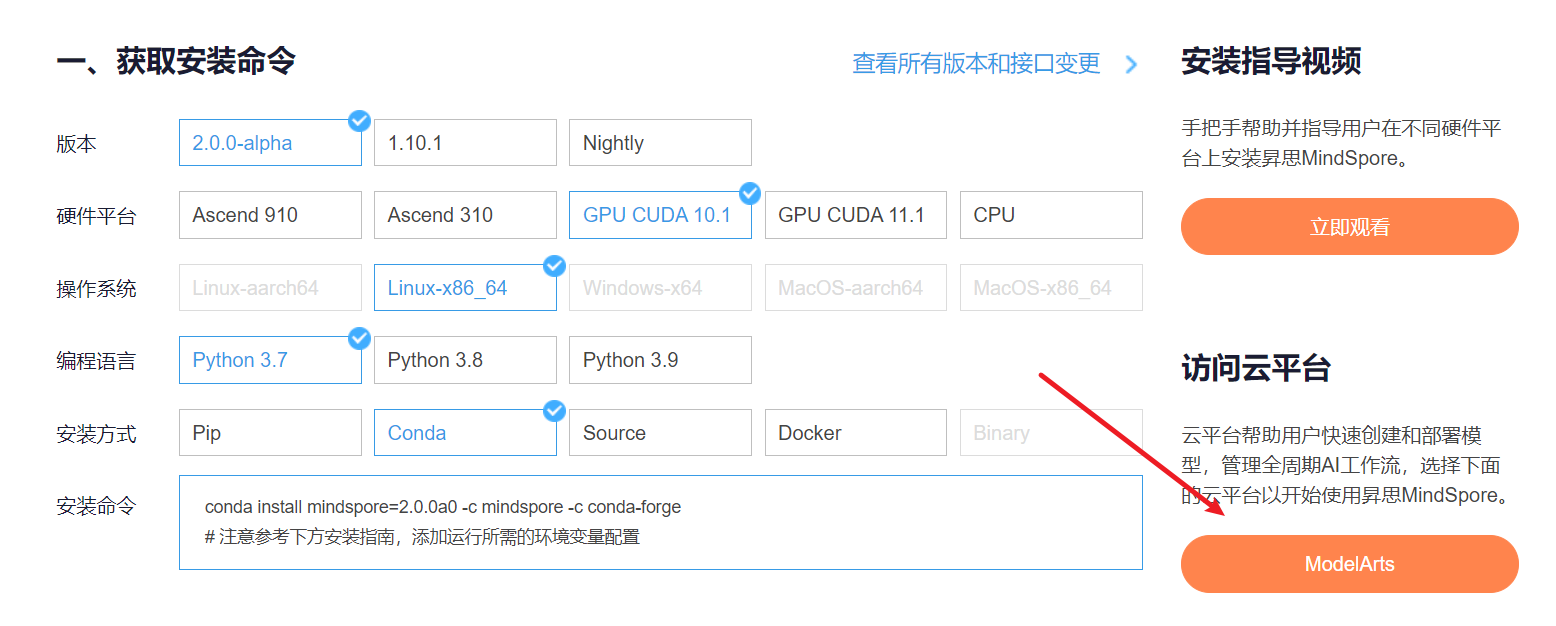
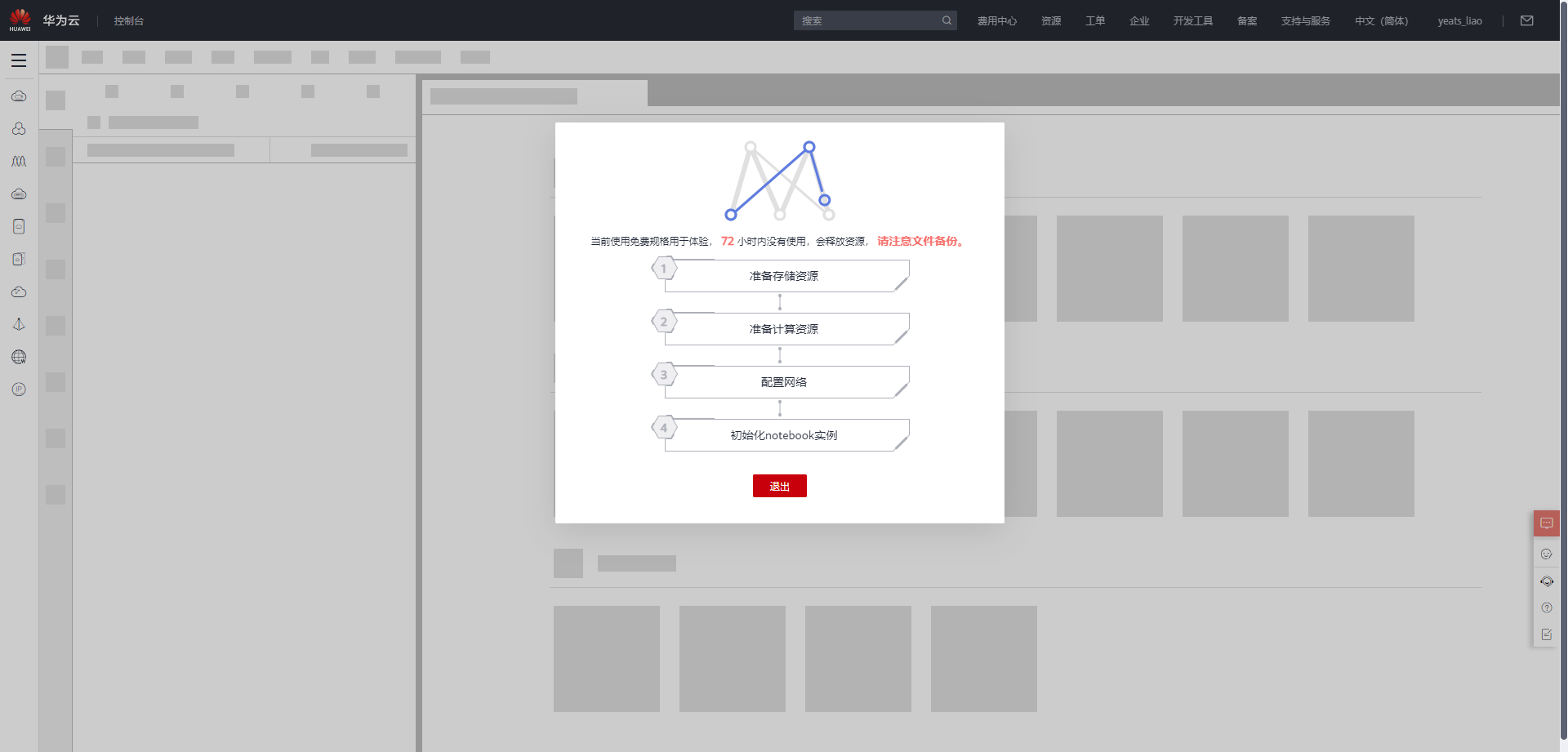
选择下方CodeLab立即体验
等待环境搭建完成
2.使用CodeLab体验Notebook实例
下载NoteBook样例代码,梯度累加 ,.ipynb为样例代码
选择ModelArts Upload Files上传.ipynb文件
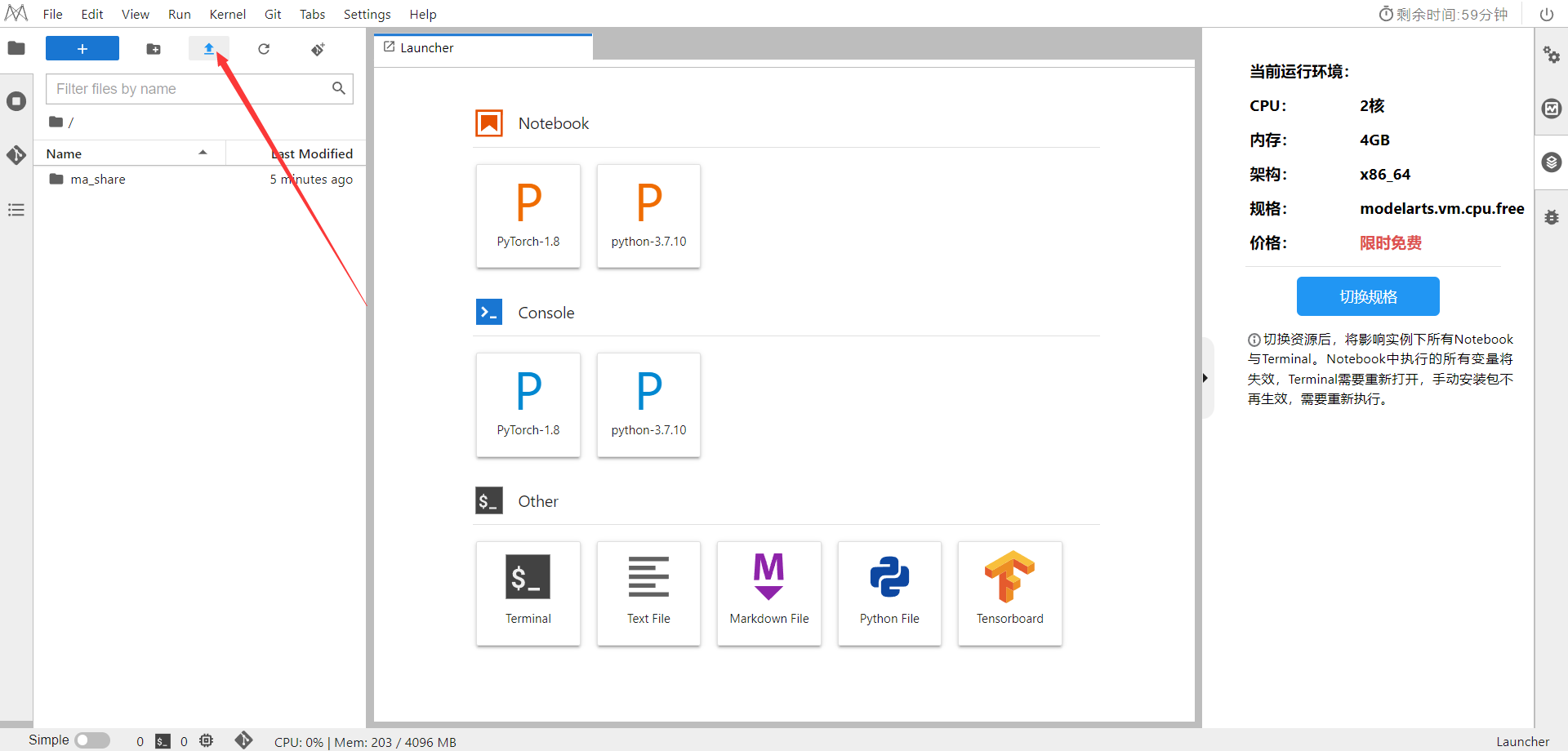
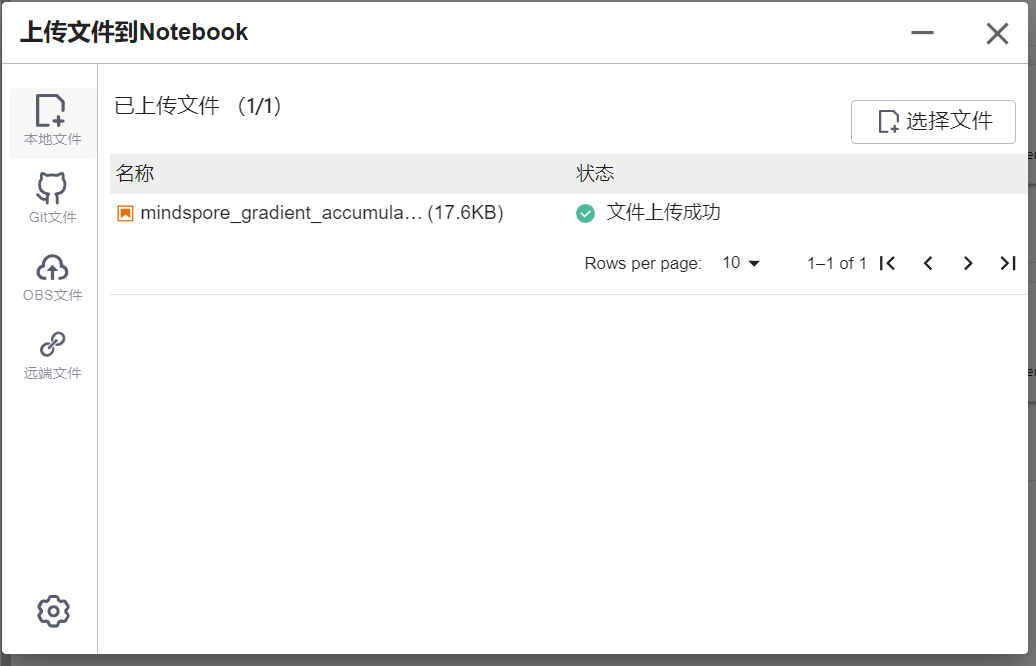
选择Kernel环境
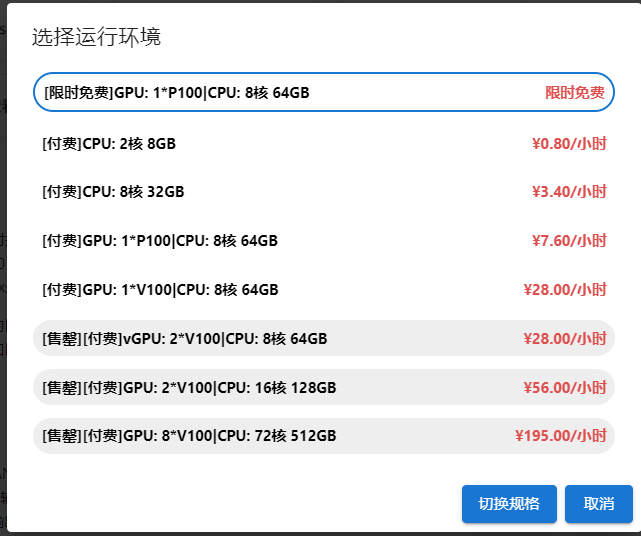
切换至GPU环境,切换成第一个限时免费
进入昇思MindSpore官网,点击上方的安装

获取安装命令

回到Notebook中,在第一块代码前加入命令
conda update -n base -c defaults conda
安装MindSpore 2.0 GPU版本
conda install mindspore=2.0.0a0 -c mindspore -c conda-forge
安装mindvision
pip install mindvision
安装下载download
pip install download
二、案例实现
基于MindSpore的函数式自动微分机制,正向和反向执行完成后,函数将返回与训练参数相对应的梯度。因此我们需要设计一个梯度累加类Accumulator,对每一个Step产生的梯度值进行存储。下面是Accumulator的实现样例,我们需要维护两份与模型可训练参数的Shape相同的内部属性,分别为inner_grads和zeros。其中inner_grads用于存储累加的梯度值,zeros用于参数优化更新后的清零。同时,Accumulator内部维护了一个counter变量,在每一次正反向执行完成后,counter自增,通过对counter取模的方式来判断是否达到累加步数。
import mindspore as ms
from mindspore import Tensor, Parameter, ops@ms.jit_class
class Accumulator():def __init__(self, optimizer, accumulate_step, clip_norm=1.0):self.optimizer = optimizerself.clip_norm = clip_normself.inner_grads = optimizer.parameters.clone(prefix="accumulate_", init='zeros')self.zeros = optimizer.parameters.clone(prefix="zeros_", init='zeros')self.counter = Parameter(Tensor(1, ms.int32), 'counter_')assert accumulate_step > 0self.accumulate_step = accumulate_stepself.map = ops.HyperMap()def __call__(self, grads):# 将单步获得的梯度累加至Accumulator的inner_gradsself.map(ops.partial(ops.assign_add), self.inner_grads, grads)if self.counter % self.accumulate_step == 0:# 如果达到累加步数,进行参数优化更新self.optimizer(self.inner_grads)# 完成参数优化更新后,清零inner_gradsself.map(ops.partial(ops.assign), self.inner_grads, self.zeros)# 计算步数加一ops.assign_add(self.counter, Tensor(1, ms.int32))return True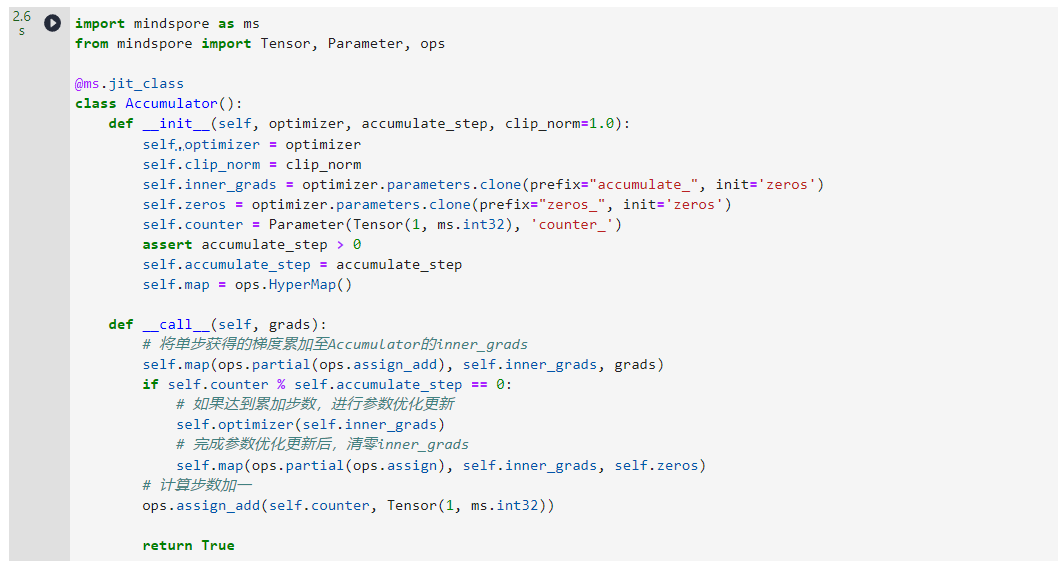
ms.jit_class为MindSpore即时编译修饰器,可以将普通的Python类作为可编译计算图使用。
接下来,我们使用快速入门中手写数字识别模型验证梯度累加的效果。
from mindspore import nn
from mindspore import value_and_grad
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDatasetfrom download import downloadurl = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)def datapipe(path, batch_size):image_transforms = [vision.Rescale(1.0 / 255.0, 0),vision.Normalize(mean=(0.1307,), std=(0.3081,)),vision.HWC2CHW()]label_transform = transforms.TypeCast(ms.int32)dataset = MnistDataset(path)dataset = dataset.map(image_transforms, 'image')dataset = dataset.map(label_transform, 'label')dataset = dataset.batch(batch_size)return datasetclass Network(nn.Cell):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.dense_relu_sequential = nn.SequentialCell(nn.Dense(28*28, 512),nn.ReLU(),nn.Dense(512, 512),nn.ReLU(),nn.Dense(512, 10))def construct(self, x):x = self.flatten(x)logits = self.dense_relu_sequential(x)return logitsmodel = Network()
假设我们在使用快速入门中配置的batch_size=64会导致显存不足,此时我们设置累加步数为2,通过执行两次batch_size=32进行梯度累加。
首先,我们使用Accumulator,传入实例化的optimizer,并配置累加步数。然后定义正向计算函数forward_fn,此时,由于梯度累加的需要,loss值需要进行相应的缩放。
accumulate_step = 2loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), 1e-2)
accumulator = Accumulator(optimizer, accumulate_step)def forward_fn(data, label):logits = model(data)loss = loss_fn(logits, label)# loss除以累加步数accumulate_stepreturn loss / accumulate_step
接下来继续使用value_and_grad函数进行函数变换,并构造单步训练函数train_step。此时我们使用实例化好的accumulator进行梯度累加,由于optimizer作为accumulator的内部属性,不需要单独执行。
grad_fn = value_and_grad(forward_fn, None, model.trainable_params())@ms.jit
def train_step(data, label):loss, grads = grad_fn(data, label)accumulator(grads)return loss
接下来,我们定义训练和评估逻辑,进行训练验证。
def train_loop(model, dataset, loss_fn, optimizer):size = dataset.get_dataset_size()model.set_train()for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):loss = train_step(data, label)if batch % 100 == 0:loss, current = loss.asnumpy(), batchprint(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")def test_loop(model, dataset, loss_fn):num_batches = dataset.get_dataset_size()model.set_train(False)total, test_loss, correct = 0, 0, 0for data, label in dataset.create_tuple_iterator():pred = model(data)total += len(data)test_loss += loss_fn(pred, label).asnumpy()correct += (pred.argmax(1) == label).asnumpy().sum()test_loss /= num_batchescorrect /= totalprint(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")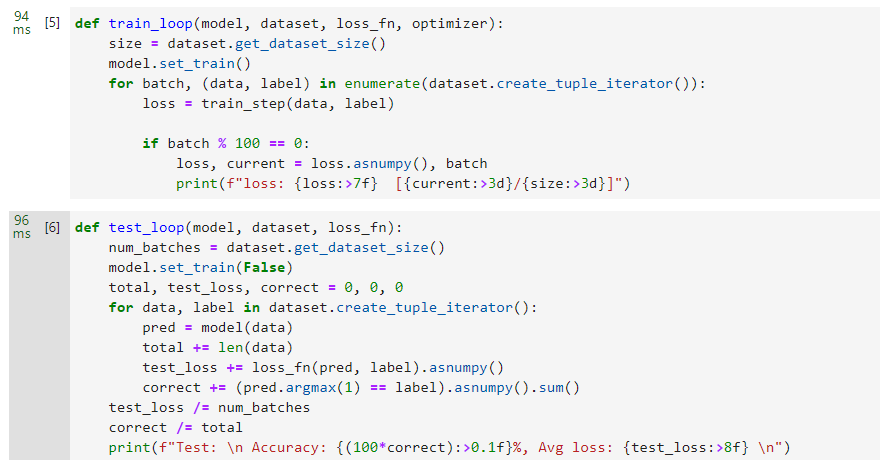
接下来同样进行3个epoch的训练,注意此时根据我们的假设,数据集需要设置batch_size=32,每两步进行累加。
train_dataset = datapipe('MNIST_Data/train', 32)
test_dataset = datapipe('MNIST_Data/test', 32)
开始训练验证,此时由于batch_size调小需要训练的step数增加至2倍。最终Accuracy验证结果与快速入门结果一致,均为93.0%左右。
epochs = 3
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train_loop(model, train_dataset, loss_fn, optimizer)test_loop(model, test_dataset, loss_fn)
print("Done!")
这篇关于华为开源自研AI框架昇思MindSpore应用案例:梯度累加的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






