本文主要是介绍自省式RAG 与 LangGraph的实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
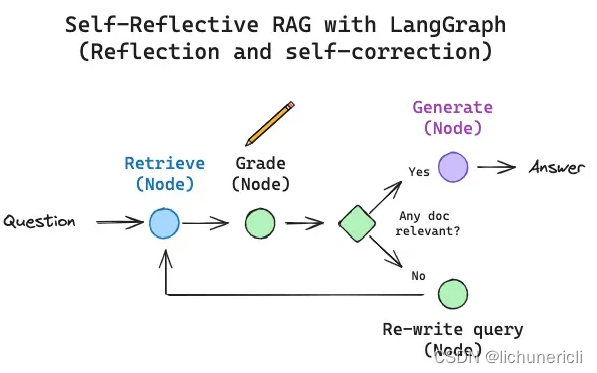
自省式 RAG
对实现 RAG 的步骤进行逻辑分析:比如,我们需要知道什么时候进行检索(基于问题和索引的构成)、何时改写问题以提升检索效率,或者何时抛弃无关的检索结果并重新检索。因此提出了自省式 RAG,自省式 RAG 利用大型语言模型自我校正检索质量不佳或生成内容不够优质的问题。
基础 RAG 流程,实质上是种链式过程:大型语言模型根据检索到的文档来决定生成的内容。有些 RAG 运作模式采用的是路由机制,大型语言模型会根据提出的问题选择不同的检索器。但是自省式 RAG 通常需要某种反馈机制,比如重新生成问题或重新检索文档。这时候,状态机制作为第三种认知架构,因其能够支持循环操作而非常适用:状态机可定义一系列步骤(例如检索、评估文档、改写问题)并设置它们的转换逻辑;比如,如果我们检索到的文档无关,我们可以重新改写问题再进行检索。
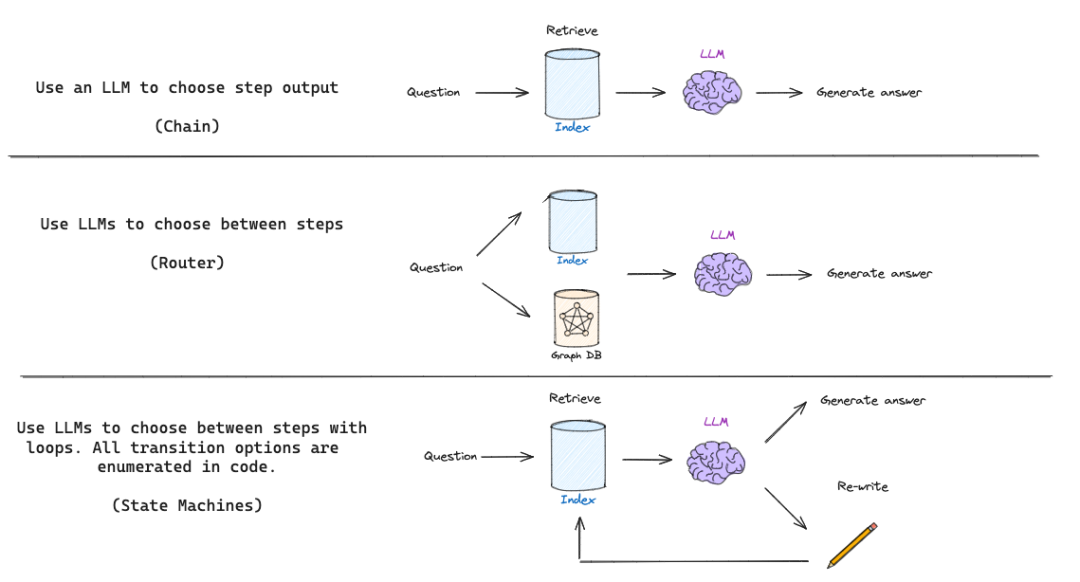
利用认知架构实施 RAG 的示意图
利用 LangGraph 实现自省式 RAG
LangGraph,简单的大型语言模型状态机实现工具。这为设计各种不同的RAG 流程提供了极大的灵活性,并支持在 RAG 中进行所谓“流程工程”,即在具体的决策点(如:评估文档)和循环(比如:重新检索)中进行特定操作。

状态机让我们得以设计出更复杂的 RAG "流"
为了展现 LangGraph 的灵活性,我们利用它来实现了两篇引人入胜、前沿的自省式 RAG 论文,CRAG 和 Self-RAG 中提出的思想。
纠正式 RAG (CRAG)
纠正式 RAG(CRAG)在其论文中提出了以下鲜明的理念:
-
引入轻量级检索评估工具,用以对查询返回的文档进行整体质量评估,并为每项文档打分。
-
当检索的结果不明确或与用户的查询不够相关时,启用基于网络的文档检索来补充上下文。
-
执行知识细化:把检索的文档分成“知识条”,对每条进行评分,过滤出无关的内容。

在描述流程时,我们对一些步骤进行了简化和调整:
-
如果发现任意一个检索的文档不相关,我们将通过网络搜索来补充检索内容。
-
改写查询语句,以便于网络搜索能提供更优的结果。
-
对于二选一的决策节点,我们用 Pydantic 来确定输出模型,并作为每一次执行大型语言模型的调用过程中运行的 OpenAI 工具函数。
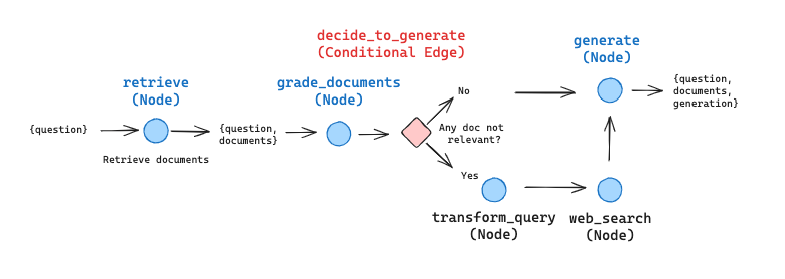
CRAG 流程的 LangGraph 实施示意图
自 RAG
自 RAG 是一个与之相望的解决方案,论文中提出了许多独到的 RAG 理念。框架中训练大型语言模型生成自我反思的提示符号,用以控制 RAG 流程的各个阶段。下面是提示符号的一览:
-
Retrieve符号决定是否需要根据x(问题)或x(问题)、y(回答)检索D数据块。可能的输出结果有yes, no, continue。 -
ISREL符号针对x问题,判断数据块D是否相关。输入为 (x(问题),d(数据块))。结果为relevant(相关), irrelevant(不相关)。
-
ISSUP符号判断 D 中每个数据块生成的答复是否与之相关。输入包括x,d,y。这个标记也是验证d是否支持y(生成)中的所有需要证实的陈述。可输出fully supported(完全支持), partially supported(部分支持), no support(不支持)。 -
ISUSE符号评估 D 中每个数据块生成的答复是否对x有用。输入x,y对于d在D里。输出是{5, 4, 3, 2, 1}。
论文中的下表为上述信息提供了进一步细节:

Self-RAG 中采用的四种提示符号
以下简图帮助我们理解信息流的运转机制:
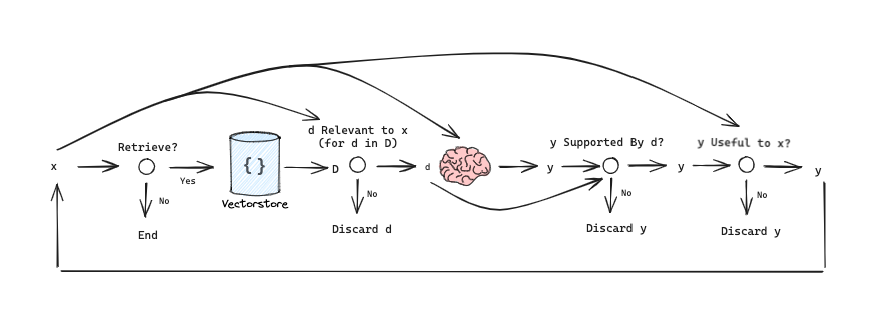
Self-RAG 使用的流程简图
可以在 LangGraph 中对其进行实现:
-
如上文所述,我们对每个检索到的文档进行评分。如果发现任何文档相关,我们就进行下一步的生成工作。如果全部文档都不相关,那我们就会改写查询来提出一个更加精确的问题,然后重新进行检索。这一环节可以很容易地结合上述 CRAG 所述的网络搜索补充节点。
-
论文中会针对每一个数据块进行生成,并进行双重评估。但在我们的实现中,只从所有相关文档生成一次内容。然后,我们根据文档检查这次生成的内容(例如,以保护免受错误印象的影响)并根据答案进行评估。这减少了调用大型语言模型的次数,提高了响应速度,并允许在生成答案时综合更多的上下文信息。

LangGraph 实现 Self-RAG 流程示意图
这里展示的示例轨迹强调了主动 RAG 的自我纠正能力。查询的问题是 解释不同类型代理记忆是如何工作的?在此示例中,所有四个文档都被认为相关,对照文档检查生成答案的环节顺利通过,但生成的答案未被认定完全有用。
之后,如这里所示,循环重新开始,问题稍微改写为:不同类型代理记忆的运作方式如何?此时,四份文档中有一份因为无关而被筛选出去。之后的生成答案成功通过了所有检查:
不同类型的代理记忆包含感官记忆、短期记忆和长期记忆。感官记忆能够保留短暂的感觉信息。短期记忆则被用于实时学习和构建提示。而长期记忆则让代理人可以在很长的时间里保存和回忆信息,并常常依赖外部的向量存储来实现。
整体流程轨迹清晰可见,可以容易地进行审核。
结语
自省机制可以显著提升 RAG 的功能,允许改正检索和生成过程中的质量问题。本文展示了如何利用 LangGraph 进行“流程工程化”地实施自反式 RAG。我们还提供了实施两篇引人注目的论文 —— Self-RAG 和 CRAG 中的理念的详细指导。
这篇关于自省式RAG 与 LangGraph的实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







