本文主要是介绍Hudi部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言
Hudi的介绍
一、Hudi是什么?
二、Hudi的特点功能和优势
三、Hudi的使用场景
Hudi的搭建部署
一、准备
二、搭建
1)搭建JAVA环境和Hadoop环境
2)部署zookeeper
3)部署Spark on yarn
4)部署maven环境
5)部署Hudi环境
三、执行编译,构建maven
Hudi的简单使用
一、准备案例
二、启动spark-shell,配置启动序列化参数
前言
随着大数据技术的飞速发展,企业对于数据处理的效率和实时性的要求也越来越高。Hadoop作为大数据领域的领军技术,长久以来一直承载着海量数据的存储和处理任务。然而,传统的Hadoop数据模型在处理更新和删除操作时的局限性,使得它难以满足实时数据湖等复杂场景的需求。
正是在这样的背景下,Hudi应运而生。Hudi,即Hadoop Upserts Deletes and Incrementals,是一个开源的数据存储层,它旨在解决Hadoop在处理更新和删除操作时的不足,使得大规模分析数据集的实时更新和增量处理成为可能。
本文旨在详细介绍如何搭建和部署Hudi,帮助读者了解并掌握这一强大的数据存储工具。我们将从环境准备、软件安装、配置调整、数据加载到性能优化等各个方面进行阐述,确保读者能够按照步骤顺利地搭建起自己的Hudi环境。
通过本文的学习,读者将能够了解到Hudi的基本原理和架构,掌握其安装和配置方法,并能够利用Hudi实现数据的实时更新和增量处理。无论是数据工程师、数据科学家还是大数据爱好者,都可以通过本文获得Hudi搭建和部署的实用知识和经验。
让我们一同走进Hudi的世界,探索它如何为实时数据湖的建设提供强大的技术支持,并为企业带来更高效、更灵活的数据处理能力。
Hudi的介绍
一、Hudi是什么?
Hudi(Hadoop Upserts Deletes and Incrementals)是一个开源的数据存储层,旨在优化Hadoop和HDFS上大规模分析数据集的更新、删除和增量处理。Hudi特别关注实时数据湖用例,使得数据工程师和数据科学家能够轻松地管理、查询和分析实时或几乎实时更新的数据集。

二、Hudi的特点功能和优势
-
支持增量更新和删除:传统上,Hadoop和HDFS是为批量处理而设计的,不支持对数据的更新或删除。然而,随着实时数据处理的需求增长,这种限制变得越来越明显。Hudi通过引入新的数据模型解决了这个问题,允许用户在不重写整个数据集的情况下,对特定记录进行更新或删除。
-
高效的数据摄取:Hudi提供了多种数据摄取方法,包括批量加载、流式摄取和实时摄取。这使得Hudi能够灵活适应不同的数据处理需求,无论是定期批量加载数据还是持续不断地从数据源摄取数据。
-
与Hadoop生态系统集成:Hudi与Hadoop生态系统中的其他组件(如Hive、Spark、Flink等)紧密集成,使得用户能够利用这些工具进行数据分析、查询和转换。
-
优化查询性能:Hudi使用列式存储格式,并结合索引和分区策略,优化了查询性能。这有助于加速数据分析任务,特别是在处理大规模数据集时。
-
版本控制和回滚:Hudi支持数据的版本控制,这意味着用户可以跟踪数据的更改历史,并在必要时回滚到之前的版本。
-
简化数据管理:通过使用Hudi,用户可以更容易地管理数据湖中的数据,包括处理数据的生命周期、保留策略和归档等。
- 优化存储和查询性能:Hudi 采用了多种技术来优化存储和查询性能,如列式存储、索引、分区等。这些技术使得用户可以更快地查询和分析数据。
三、Hudi的使用场景
1)近实时写入
减少碎片化工具的使用。
CDC 增量导入 RDBMS 数据。
限制小文件的大小和数量。
2)近实时分析
相对于秒级存储(Druid, OpenTSDB),节省资源。
提供分钟级别时效性,支撑更高效的查询。
Hudi作为lib,非常轻量。
3)增量 pipeline
区分arrivetime和event time处理延迟数据。
更短的调度interval减少端到端延迟(小时 -> 分钟) => Incremental Processing。
4)增量导出
替代部分Kafka的场景,数据导出到在线服务存储 e.g. ES。
Hudi的搭建部署
一、准备
准备下图的安装包:

具体准备要求:
1)确保安装了JAVA开发工具包(JDK),因为Hudi是基于Java开发的,因此JDK是必需的。确保安装了与Hudi兼容的JDK版本,并配置好环境变量,以便在命令行中能够直接使用。
2)由于Hudi依赖于Apache Hadoop和Apache Spark,因此在安装Hudi之前,需要先安装和配置这两个组件。
3)需要安装并配置 Apache Maven:
Maven是一个项目管理工具,用于自动化构建Java项目,并管理项目的依赖关系。安装Maven后,需要设置其环境变量,并确保可以在命令行中调用Maven命令。
部署maven的原因:
在搭建和部署Hudi的过程中,之所以需要搭建Maven环境,主要是因为Hudi项目本身是基于Java开发的,并且采用了Maven作为项目管理工具。Maven在Java项目开发中扮演了重要的角色,它提供了项目构建、依赖管理等功能,能够大大简化项目的开发和维护过程。
具体来说,Maven通过定义项目对象模型(POM),帮助开发者管理项目的构建过程、依赖关系、生命周期等。对于Hudi项目而言,Maven可以自动处理其所需的Java依赖库,包括其他Java项目或库,确保项目在编译、测试和运行时能够正确引用这些依赖。
此外,Maven还提供了丰富的插件生态系统,这些插件可以扩展Maven的功能,实现诸如代码编译、打包、发布等操作。在Hudi的搭建和部署过程中,这些插件可以帮助我们自动化地完成一些繁琐的任务,提高开发效率。
因此,为了顺利搭建和部署Hudi,我们需要先搭建Maven环境,以便利用Maven的强大功能来管理Hudi项目的构建和依赖关系。这样,我们可以确保Hudi项目在开发和运行过程中能够正确、高效地运行,为后续的数据处理和分析工作提供有力的支持。
4)需要下载Hudi的发布版本
二、搭建
1)搭建JAVA环境和Hadoop环境
https://blog.csdn.net/2301_78038072/article/details/136498258![]() https://blog.csdn.net/2301_78038072/article/details/136498258
https://blog.csdn.net/2301_78038072/article/details/136498258
2)部署zookeeper
https://blog.csdn.net/2301_78038072/article/details/136505364![]() https://blog.csdn.net/2301_78038072/article/details/136505364
https://blog.csdn.net/2301_78038072/article/details/136505364
3)部署Spark on yarn
生产生活中 因为数据量比较大,是以TB、PB级别的数据量,所以建议部署在yarn上
https://blog.csdn.net/2301_78038072/article/details/136632914![]() https://blog.csdn.net/2301_78038072/article/details/136632914
https://blog.csdn.net/2301_78038072/article/details/136632914
4)部署maven环境
①解压缩安装包到/opt/module目录下
tar -zxvf /opt/software/apache-maven-3.6.3-bin.tar.gz -C /opt/module/②配置maven的环境变量
vim /etc/profile.d/bigdata_env.sh添加:
#MAVEN_HOME
export MAVEN_HOME=/opt/module/apache-maven-3.6.3
export PATH=$PATH:$MAVEN_HOME/bin退出保存,刷新环境,使其生效:
source /etc/profile③验证是否成功
mvn -v
④修改apache-maven-3.6.1/conf目录下的settings.xml文件
(1)添加maven本地仓库路径
跳转到大概55行左右,添加内容:
<localRepository>/opt/software/RepMaven</localRepository>
(2)修改阿里云镜像
跳转到大概160行左右,添加内容:
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</namw>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>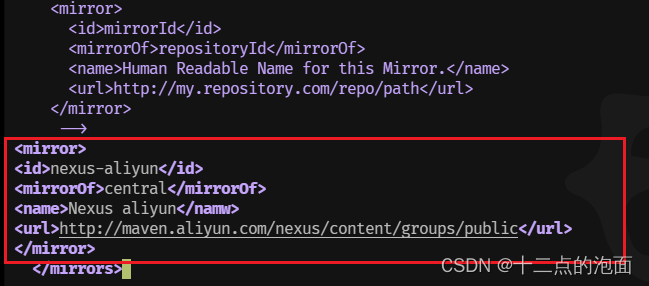
5)部署Hudi环境
①解压缩安装包到/opt/module目录下
tar -zxvf /opt/software/hudi-0.11.0.src.tgz -C /opt/module/②修改hudi-0.11.0文件夹目录下的pom.xml文件
(1)111行和113行左右 修改hadoop与hive版本兼容

(2)1170行左右 新增中央仓库repository加速依赖下载
<repository><id>nexus-aliyun</id><name>nexus-aliyun</name><url>http://maven.aliyun.com/nexus/content/groups/public/</url><releases><enabled>true</enabled></releases><snapshots><enabled>false</enabled></snapshots>
</repository>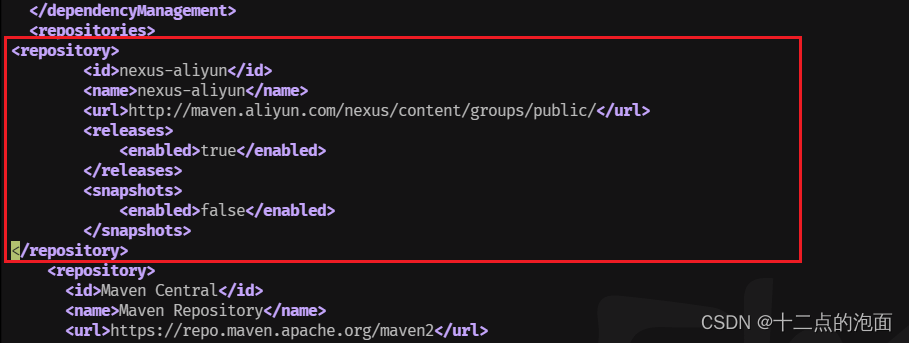
③ 修改源码兼容hadoop3
vim /opt/module/hudi-0.11.0/hudi-common/src/main/java/org/apache/hudi/common/table/log/block/HoodieParquetDataBlock.java
113左右

④修改hudi-0.11.0/packaging/hudi-spark-bundle/文件夹目录下的pom.xml文件
vim /opt/module/hudi-0.11.0/packaging/hudi-spark-bundle/pom.xml解决spark模块依赖冲突
(1)380行左右 hive
<exclusions><exclusion><artifactId>guava</artifactId><groupId>com.google.guava</groupId></exclusion><exclusion><groupId>org.eclipse.jetty</groupId><artifactId>*</artifactId></exclusion><exclusion><groupId>org.pentaho</groupId><artifactId>*</artifactId></exclusion>
</exclusions>(2)410行左右 hive-jdbc
<exclusions><exclusion><groupId>javax.servlet</groupId><artifactId>*</artifactId></exclusion><exclusion><groupId>javax.servlet.jsp</groupId><artifactId>*</artifactId></exclusion><exclusion><groupId>org.eclipse.jetty</groupId><artifactId>*</artifactId></exclusion>
</exclusions>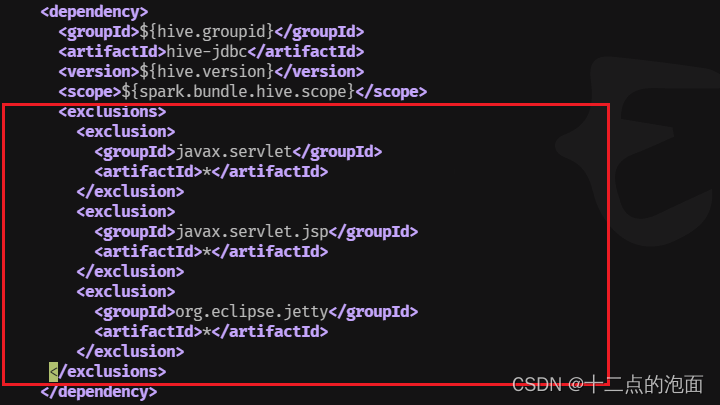
(3)430行左右 hive-metastore
<exclusions><exclusion><groupId>javax.servlet</groupId><artifactId>*</artifactId></exclusion><exclusion><groupId>org.datanucleus</groupId><artifactId>datanucleus-core</artifactId></exclusion><exclusion><groupId>javax.servlet.jsp</groupId><artifactId>*</artifactId></exclusion><exclusion><artifactId>guava</artifactId><groupId>com.google.guava</groupId></exclusion>
</exclusions>
(4)455行左右 hive-common
<exclusions><exclusion><groupId>org.eclipse.jetty.orbit</groupId><artifactId>javax.servlet</artifactId></exclusion><exclusion><groupId>org.eclipse.jetty</groupId><artifactId>*</artifactId></exclusion>
</exclusions>
(5) 在最后手动增加jetty (hive最下边,zookeeper上边)
排除低版本jetty,添加hudi指定版本的jetty
<!-- 增加hudi配置版本的jetty --><dependency><groupId>org.eclipse.jetty</groupId><artifactId>jetty-server</artifactId><version>${jetty.version}</version></dependency><dependency><groupId>org.eclipse.jetty</groupId><artifactId>jetty-util</artifactId><version>${jetty.version}</version></dependency><dependency><groupId>org.eclipse.jetty</groupId><artifactId>jetty-webapp</artifactId><version>${jetty.version}</version></dependency><dependency><groupId>org.eclipse.jetty</groupId><artifactId>jetty-http</artifactId><version>${jetty.version}</version></dependency>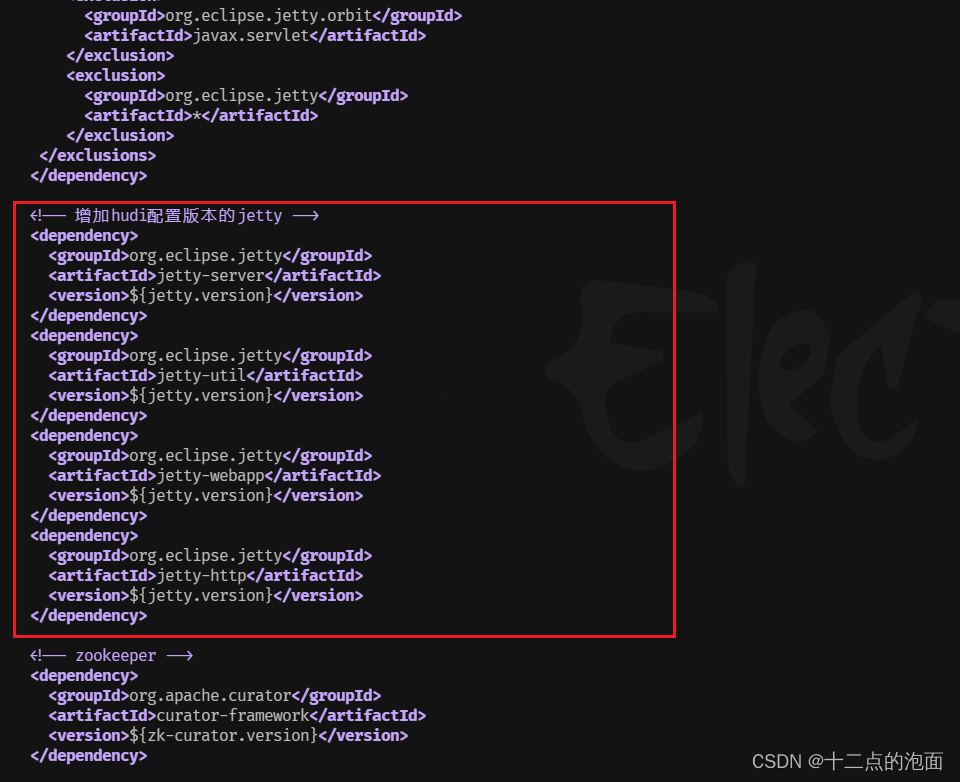
⑤修改hudi-0.11.0/packaging/hudi-utilities-bundle/文件夹目录下的pom.xml文件
vim /opt/module/hudi-0.11.0/packaging/hudi-utilities-bundle/pom.xml(1)350行左右
<exclusions><exclusion><groupId>org.eclipse.jetty</groupId><artifactId>*</artifactId></exclusion></exclusions>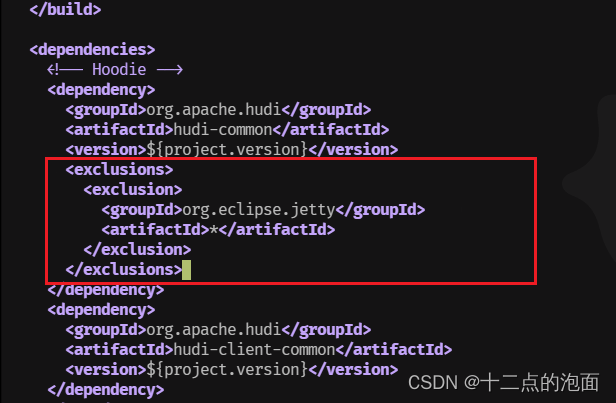
(2)361行左右
<exclusions><exclusion><groupId>org.eclipse.jetty</groupId><artifactId>*</artifactId></exclusion></exclusions>
(3)423行左右 hive-service
<exclusions><exclusion><artifactId>servlet-api</artifactId><groupId>javax.servlet</groupId></exclusion><exclusion><artifactId>guava</artifactId><groupId>com.google.guava</groupId></exclusion><exclusion><groupId>org.eclipse.jetty</groupId><artifactId>*</artifactId></exclusion><exclusion><groupId>org.pentaho</groupId><artifactId>*</artifactId></exclusion></exclusions>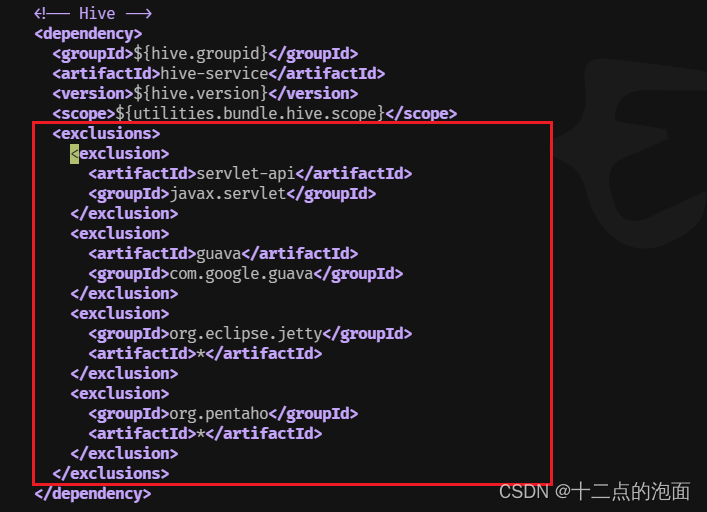
(4)455行左右 hive-jdbc
<exclusions><exclusion><groupId>javax.servlet</groupId><artifactId>*</artifactId></exclusion><exclusion><groupId>javax.servlet.jsp</groupId><artifactId>*</artifactId></exclusion><exclusion><groupId>org.eclipse.jetty</groupId><artifactId>*</artifactId></exclusion></exclusions>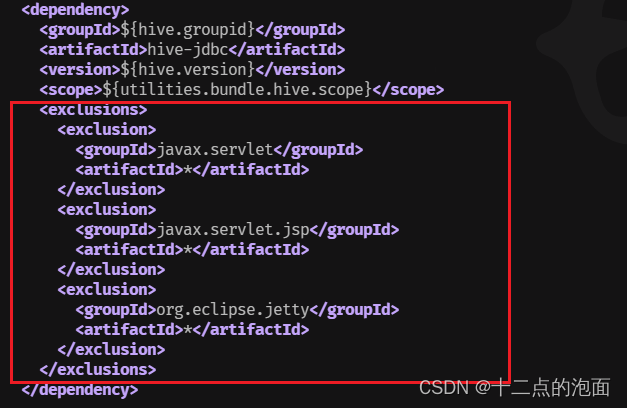
(5)476行左右 hive-metastore
<exclusions><exclusion><groupId>javax.servlet</groupId><artifactId>*</artifactId></exclusion><exclusion><groupId>org.datanucleus</groupId><artifactId>datanucleus-core</artifactId></exclusion><exclusion><groupId>javax.servlet.jsp</groupId><artifactId>*</artifactId></exclusion><exclusion><artifactId>guava</artifactId><groupId>com.google.guava</groupId></exclusion></exclusions>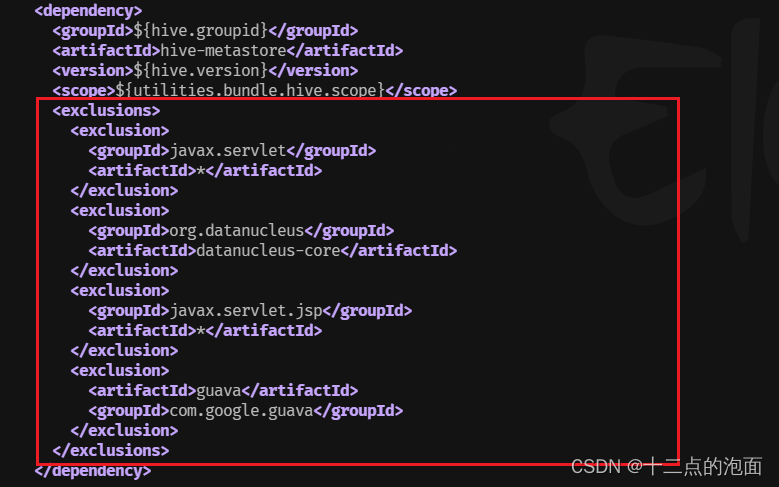
(6)501行左右 hive-common
<exclusions><exclusion><groupId>org.eclipse.jetty.orbit</groupId><artifactId>javax.servlet</artifactId></exclusion><exclusion><groupId>org.eclipse.jetty</groupId><artifactId>*</artifactId></exclusion></exclusions>
(7)520行 最后增加hudi配置版本的jetty
<!-- 增加hudi配置版本的jetty --><dependency><groupId>org.eclipse.jetty</groupId><artifactId>jetty-server</artifactId><version>${jetty.version}</version></dependency><dependency><groupId>org.eclipse.jetty</groupId><artifactId>jetty-util</artifactId><version>${jetty.version}</version></dependency><dependency><groupId>org.eclipse.jetty</groupId><artifactId>jetty-webapp</artifactId><version>${jetty.version}</version></dependency><dependency><groupId>org.eclipse.jetty</groupId><artifactId>jetty-http</artifactId><version>${jetty.version}</version></dependency>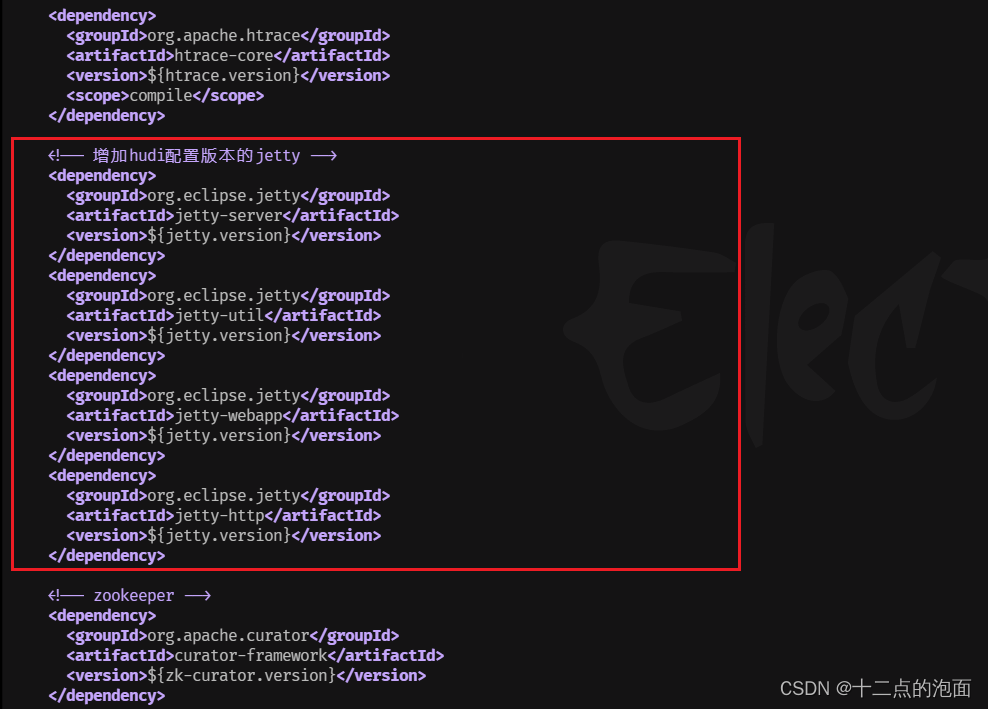
三、执行编译,构建maven
mvn clean package -DskipTests -Dspark3.0 -Dscala-2.12 -Dhadoop.version=3.1.3 -Pflink-bundle-shade-hive3参数解析:
mvn: 这是Maven命令行工具的调用,Maven是一个用于自动化构建Java项目的工具。
clean: 这个目标(goal)用于清理项目构建的输出目录,通常包括target/目录,确保从干净的状态开始构建。
package: 这个目标用于编译项目源代码,执行测试(如果未使用-DskipTests参数),并打包项目为一个可发布的格式,比如JAR、WAR或EAR文件。
-DskipTests: 这个参数告诉Maven在构建过程中跳过单元测试。这对于只想构建项目而不运行测试的场景很有用,可以节省构建时间。
-Dspark3.0: 这个参数可能是一个自定义属性,用于指定项目应该使用Apache Spark 3.0版本的相关依赖。这通常用于项目的pom.xml文件中,通过Maven属性来控制依赖的版本。
-Dscala-2.12: 类似地,这个参数可能用于指定项目应该使用Scala 2.12版本的相关依赖。
-Dhadoop.version=3.1.3: 这个参数用于指定Hadoop的版本为3.1.3。Maven将使用这个版本来解析Hadoop相关的依赖。
-Pflink-bundle-shade-hive3: 这个参数用于激活一个或多个Maven profile。在这里,它激活了名为flink-bundle-shade-hive3的profile。Profiles是Maven中用于定义不同构建逻辑的一种方式,可以根据不同的环境或需求激活不同的profile。(这个profile与Apache Flink的捆绑、shade(重命名依赖以避免冲突)和Hive 3相关。)
接下来就是等待编译,过程很漫长
………………
………………………………
………………………………………………
………………………………………………………………
………………………………………………………………………………
………………………………………………………………………………………………
………………………………………………………………………………………………………………
就这样等啊等,你等了20分钟左右,出现了下面的画面,就证明你成功了
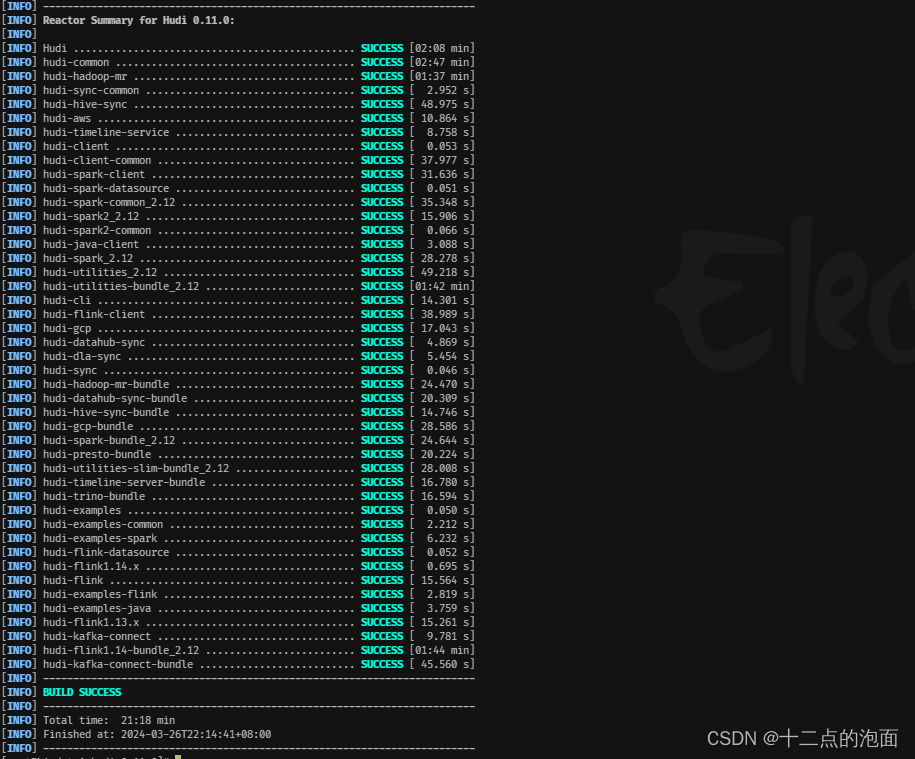
成功编译之后,进入Hudi自带的客户端
hudi-cli/hudi-cli.sh
Hudi的简单使用
一、准备案例
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.common.model.HoodieRecordval tableName = "hudi_trips_cow"
val basePath = "file:///tmp/hudi_trips_cow"
val dataGen = new DataGeneratorval inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").options(getQuickstartWriteConfigs).option(PRECOMBINE_FIELD_OPT_KEY, "ts").option(RECORDKEY_FIELD_OPT_KEY, "uuid").option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").option(TABLE_NAME, tableName).mode(Overwrite).save(basePath)val tripsSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
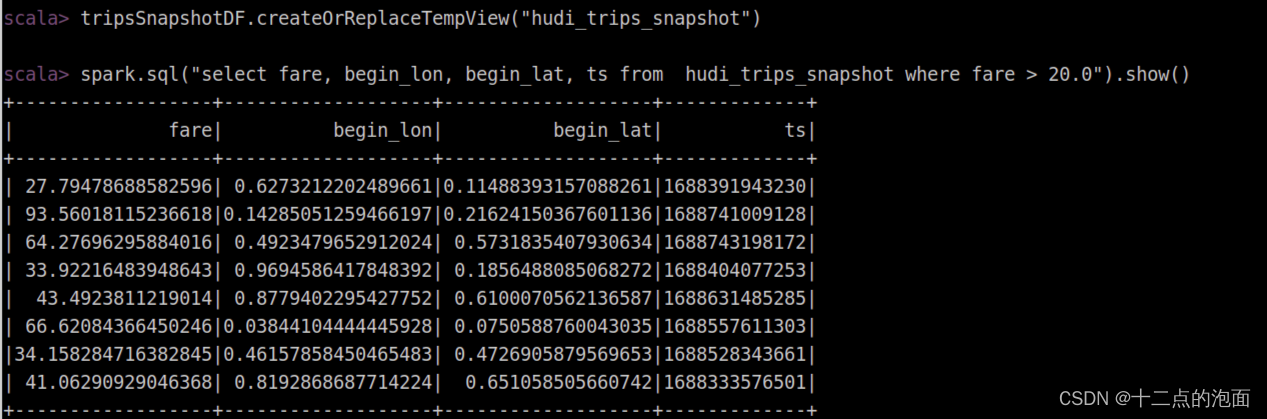
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()二、启动spark-shell,配置启动序列化参数
spark-shell --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
直接复制案例进入spark-shell里面,会得到
这篇关于Hudi部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







