本文主要是介绍oracle connect by很强,但是要慎用,不然有你哭的时候,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:
第四次工业革命,带来了科技的巨大变更,同时带来了很多半结构化数据,很多数据会做成集合、JSON的形式存储到数据库中,通过ETL工具我们将这些数据抽取到数仓里面,我们怎么进行分析呢?这些数据类似这样的保留在数据库里面。比如下面所示,同一个检测项目由多个人负责检测,因此会通过"\" "/"等等分隔符一次性将数据录入字段里头,方便用户进行数据维护,当然这些数据对分析人员提出较高的要求。为了将这些数据拆分为多行,我们就会使用到connect by来拆分,将数据拆分为多行。

针对这些数据,我在前面写了一篇文章介绍来处理这些数据,也是因为性能的问题,然后使用存储过程,一条条执行,将一行数据拆分好以后,存储至数据库,直到拆分完毕为止。具体我们可以参考我以前写的文章。
oracle一次性说清楚,多种分隔符的一个字段拆分多行,再多行多列多种分隔符拆多行,最终处理超亿亿。。亿级别数据量_oracle分隔符_他们叫我技术总监的博客-CSDN博客
一、connect by常见用法
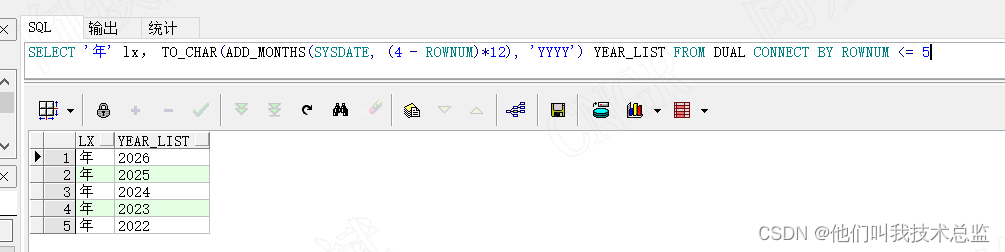
1、万年历
代码
SELECT '年' lx, TO_CHAR(ADD_MONTHS(SYSDATE, (4 - ROWNUM)*12), 'YYYY') YEAR_LIST
FROM DUAL CONNECT BY ROWNUM <= 5 --获取近5年的年份效果
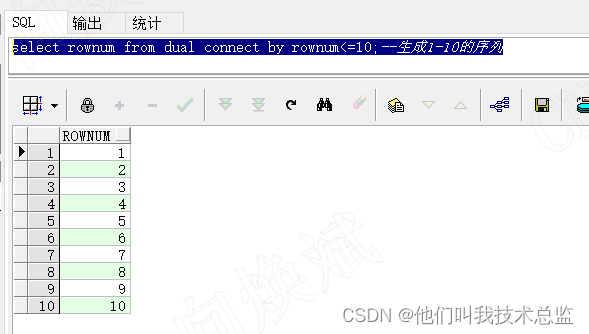
2、生成序列
代码
select rownum from dual connect by rownum<=10;--生成1-10的序列效果
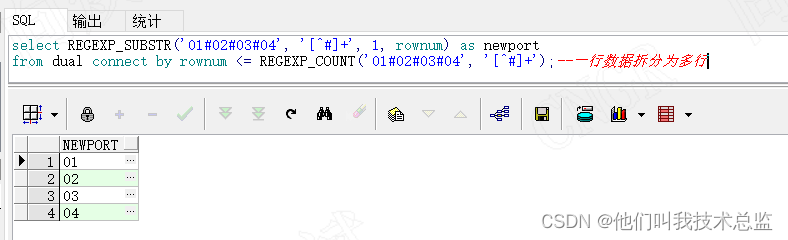
3、一行变多行
代码
select REGEXP_SUBSTR('01#02#03#04', '[^#]+', 1, rownum) as newport
from dual connect by rownum <= REGEXP_COUNT('01#02#03#04', '[^#]+');--一行数据拆分为多行效果
总结:
总的来说,connect by在处理少量的树状数据还是很强大的,这也是很多人喜欢应用它的原因。但是oracle 是不清楚connect by后会出现多少行的数据结构,因此oracle 容易错误的cardinality估算,从而走了NESTED LOOPS,因无法估算结果数据行,因此当原始数据量在500-800行时性能就会变的很差。
二、实战案例剖析
1、union all +connect by
在我现在的一个项目上就遇到了一个经典的案例,就是因使用了connect by导致,一个数据同步了快3天都没成功,具体为啥会同步3天呢?因刚好是周五下班后用户反馈,然后因下班到家了,不能远程处理,在周日停掉执行后,优化了部分逻辑,再执行,到周一早上发现还是没达到想要的效果。因对应SQ较复杂,就没详细去分析原因。具体SQ如下所示:
select a.state xtstate,a.current_nodes_info dbr,c.*,b.FILENAME,b.FILE_URL,case when c.field0035 is null then round(to_date(to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss'),'yyyy-mm-dd hh24:mi:ss')- to_date(to_char(c.START_DATE, 'yyyy-mm-dd hh24:mi:ss'),'yyyy-mm-dd hh24:mi:ss'),2) --没有审批意见的when FIELD0090 is not null then round(to_date(to_char(FIELD0090, 'yyyy-mm-dd hh24:mi:ss'),'yyyy-mm-dd hh24:mi:ss')- to_date(to_char(c.START_DATE, 'yyyy-mm-dd hh24:mi:ss'),'yyyy-mm-dd hh24:mi:ss'),2) end clsc,to_char(FIELD0090, 'yyyy-mm-dd hh24:mi:ss') FINISH_DATE,to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss') etlts,casewhen a.FINISH_DATE is not null then'关闭'when FIELD0090 is not null then'评审完成'when case when c.field0035 is null then round(to_date(to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss'),'yyyy-mm-dd hh24:mi:ss')- to_date(to_char(c.START_DATE, 'yyyy-mm-dd hh24:mi:ss'),'yyyy-mm-dd hh24:mi:ss'),2) --没有审批意见的when FIELD0090 is not null then round(to_date(to_char(FIELD0090, 'yyyy-mm-dd hh24:mi:ss'),'yyyy-mm-dd hh24:mi:ss')- to_date(to_char(c.START_DATE, 'yyyy-mm-dd hh24:mi:ss'),'yyyy-mm-dd hh24:mi:ss'),2) end >= 5 then'超期'when case when c.field0035 is null then round(to_date(to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss'),'yyyy-mm-dd hh24:mi:ss')- to_date(to_char(c.START_DATE, 'yyyy-mm-dd hh24:mi:ss'),'yyyy-mm-dd hh24:mi:ss'),2) --没有审批意见的when FIELD0090 is not null then round(to_date(to_char(FIELD0090, 'yyyy-mm-dd hh24:mi:ss'),'yyyy-mm-dd hh24:mi:ss')- to_date(to_char(c.START_DATE, 'yyyy-mm-dd hh24:mi:ss'),'yyyy-mm-dd hh24:mi:ss'),2) end < 5 then'进行中'end psjd,mx.*from V3XUSER.COL_SUMMARY Aleft join V3XUSER.CTP_ATTACHMENT bon a.id = b.SUB_REFERENCEright join (select * from V3XUSER.formmain_2182 c where to_char(c.start_date,'yyyy-mm-dd')>to_char(sysdate-60,'yyyy-mm-dd') ) c--只更新近2个半月的数据on c.id = a.FORM_RECORDIDleft join (select lscs.*,lswc.field0068 wcsj,lswc.field0069 wcqkms,fj.filename filename2,fj.file_url file_url2,FIELD0071 结案确认from (select '临时措施' lx,lscs.FIELD0055 csxq,listagg(ry.name, '、') within group(order by ry.name) zrr,lscs.FIELD0057 jhwcsj,lscs.fid,lscs.iidfrom (SELECT distinct id iid,formmain_id fid,REGEXP_SUBSTR(FIELD0056,'[^,]+',1,LEVEL) cf,a.*FROM V3XUSER.formson_3565 aCONNECT BY REGEXP_SUBSTR(FIELD0056,'[^,]+',1,LEVEL) is not null) lscsleft join V3XUSER.ORG_MEMBER ryon lscs.cf = ry.idgroup by '临时措施',lscs.FIELD0055,lscs.FIELD0057,lscs.fid,lscs.iid) lscsleft join V3XUSER.formson_3568 lswcon lscs.fid = lswc.formmain_idand lscs.csxq = lswc.field0067left join V3XUSER.CTP_ATTACHMENT fjon lswc.field0070 = fj.SUB_REFERENCEunion allselect lscs.*,lswc.field0073 wcsj,lswc.field0074 wcqkms,fj.filename,fj.file_url file_url,field0076 结案确认from (select '长久措施' lx,lscs.FIELD0058 csxq,listagg(ry.name, '、') within group(order by ry.name) zrr,lscs.field0060 jhwcsj,lscs.fid,lscs.iidfrom (SELECT id iid,formmain_id fid,REGEXP_SUBSTR(field0059,'[^,]+',1,LEVEL) cf,a.*FROM V3XUSER.formson_3566 aCONNECT BY REGEXP_SUBSTR(field0059,'[^,]+',1,LEVEL) is not null) lscsleft join V3XUSER.ORG_MEMBER ryon lscs.cf = ry.idgroup by '长久措施',lscs.FIELD0058,lscs.field0060,lscs.fid,lscs.iid) lscsleft join V3XUSER.formson_3569 lswcon lscs.fid = lswc.formmain_idand lscs.csxq = lswc.field0072left join V3XUSER.CTP_ATTACHMENT fjon lswc.field0075 = fj.SUB_REFERENCEunion allselect lscs.*,lswc.field0078 wcsj,lswc.field0079 wcqkms,fj.filename,fj.file_url file_url,field0081 结案确认from (select '防呆设计' lx,lscs.FIELD0061 csxq,listagg(ry.name, '、') within group(order by ry.name) zrr,lscs.field0063 jhwcsj,lscs.fid,lscs.iidfrom (SELECT id iid,formmain_id fid,REGEXP_SUBSTR(field0062,'[^,]+',1,LEVEL) cf,a.*FROM V3XUSER.formson_3567 aCONNECT BY REGEXP_SUBSTR(field0062,'[^,]+',1,LEVEL) is not null) lscsleft join V3XUSER.ORG_MEMBER ryon lscs.cf = ry.idgroup by '防呆设计',lscs.FIELD0061,lscs.field0063,lscs.fid,lscs.iid) lscsleft join V3XUSER.formson_3570 lswcon lscs.fid = lswc.formmain_idand lscs.csxq = lswc.field0077left join V3XUSER.CTP_ATTACHMENT fjon lswc.field0080 = fj.SUB_REFERENCE) mxon c.id = mx.fid
因为项目初期原始表数据量很小,执行connect by的时候基本还看不到什么性能问题。但是当运行3个月左右数据时,原始数据在600多行左右时,就出现性能问题了,真的是慢的不行。具体我们可以来看下执行日志。
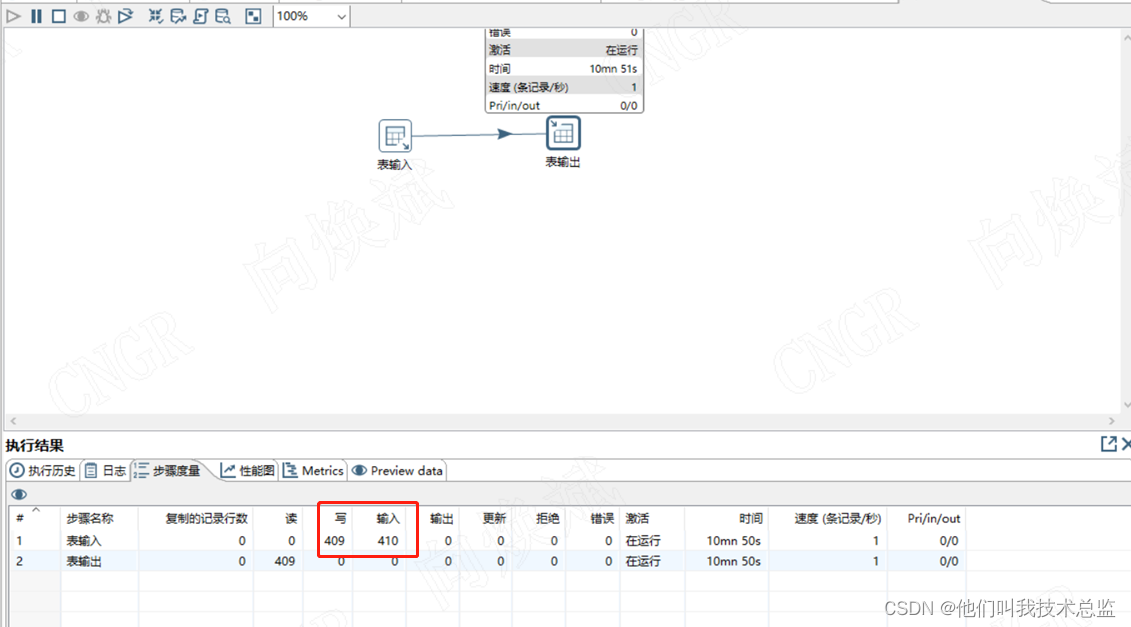
如上图所示,一共410条数据,执行了快11分钟,而且还是卡住不动的。Oh my god!这是什么鬼。通过拆分每段的执行过程发现,性能卡在了最后的"mx"表查询,即union all +connect by那段。
2、connect by 具体卡在哪里了
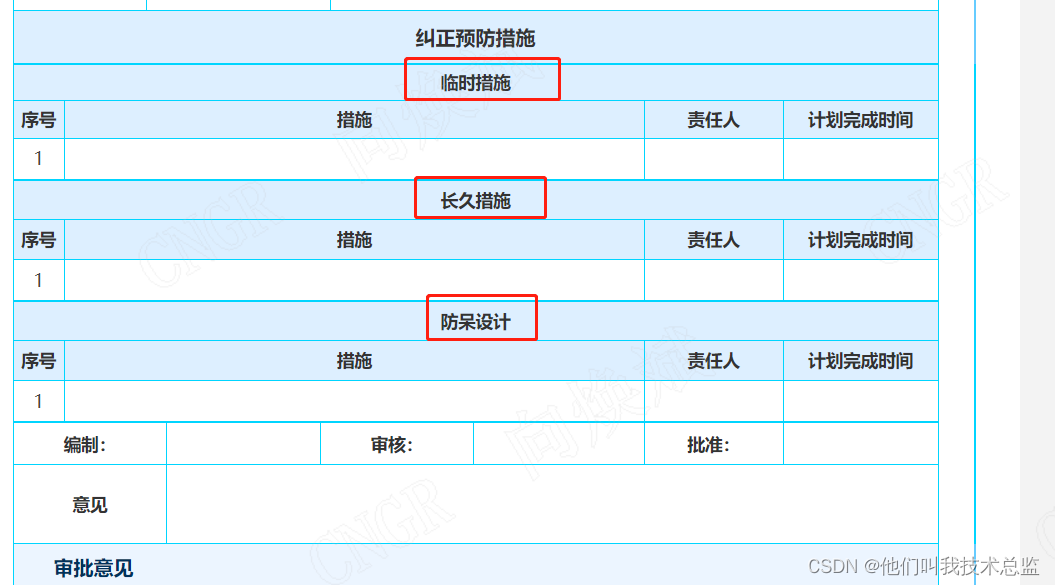
如上图所示,用户会做3个措施,每个措施会有多个责任人,因此会union all 2遍,将3个措施拼接起来,因为责任人会在一行,因此使用了connect by 来进行拆分为多行。看起来逻辑是没啥问题,但是性能时真不行呀。
单独查询临时措施,拆分后817行数据,耗时了快5分钟,可能还能接受,但是加上union all 后那就是雪上加霜了。
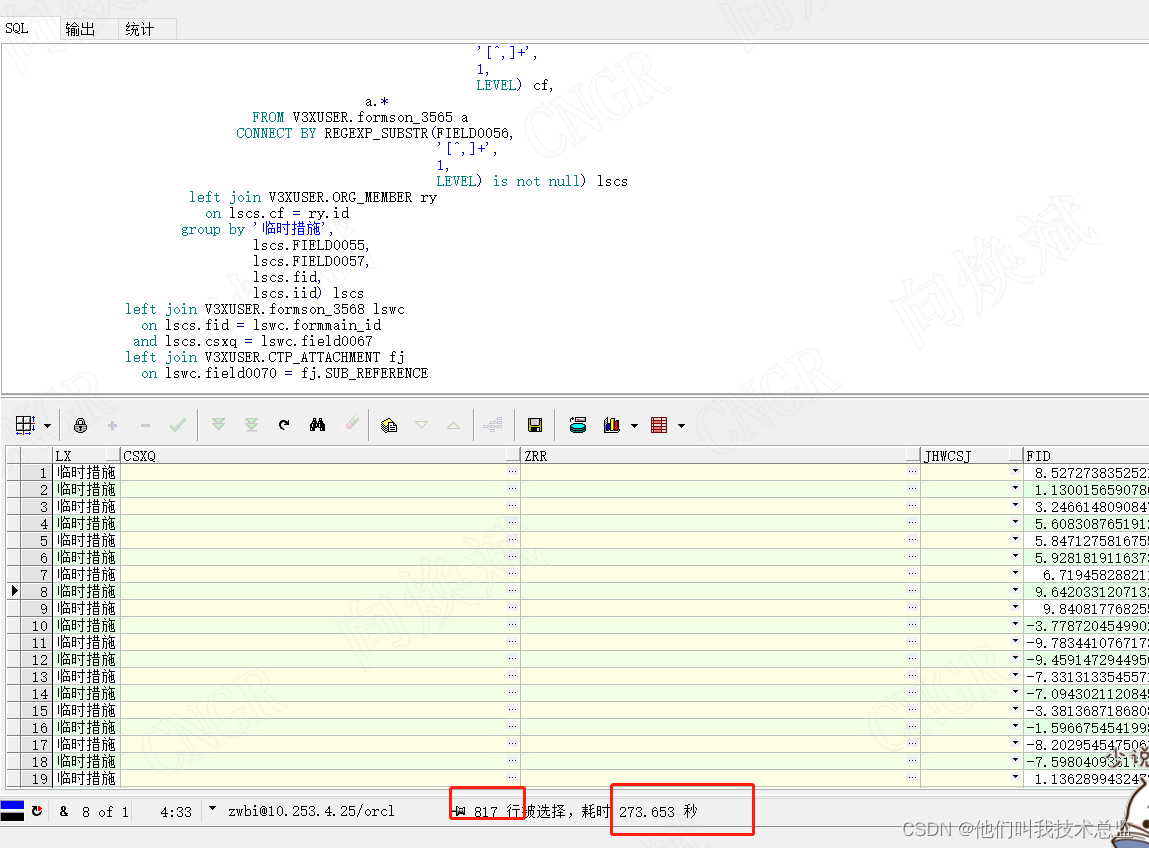
哈哈哈,不久DBA就过来找我了,说带有connect by进程执行了差不多1000分钟,哈哈哈是有点离谱的。
三、解决方案
1、游标执行/分而治之
如上面所说的connect by 在数据量很小的时候,运行效率还是很高的,因此我们可以采用存储过程,或者将union all 拆分开来执行,然后将数据汇总到一个底表里头。具体如下图所示
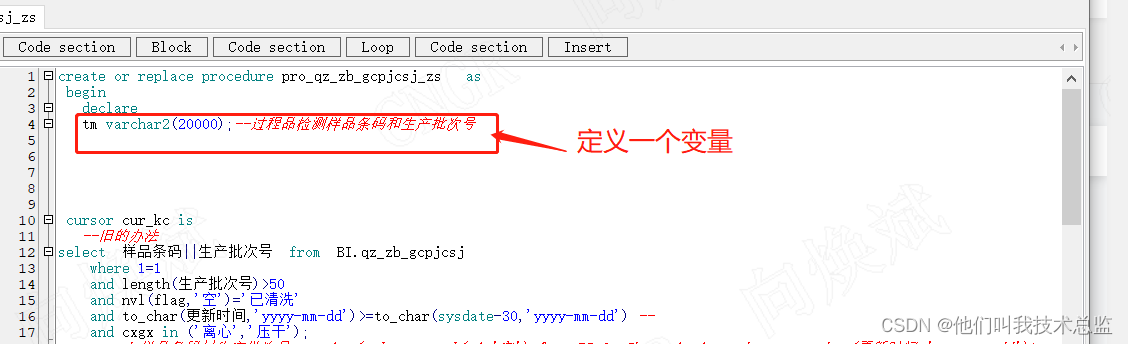
定义变量,用游标一行行拆分执行
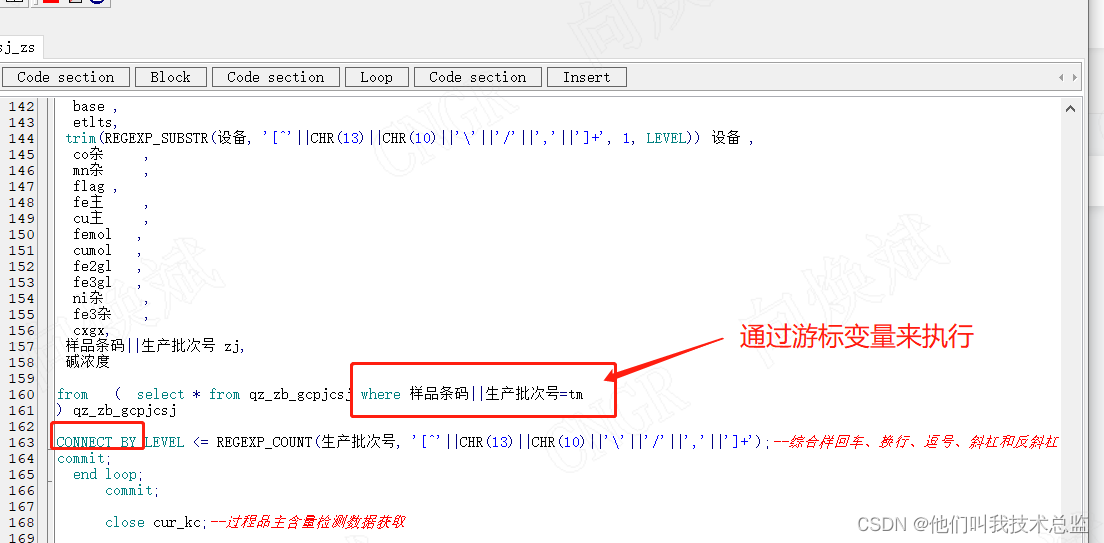
通过存储过程游标来拆分执行
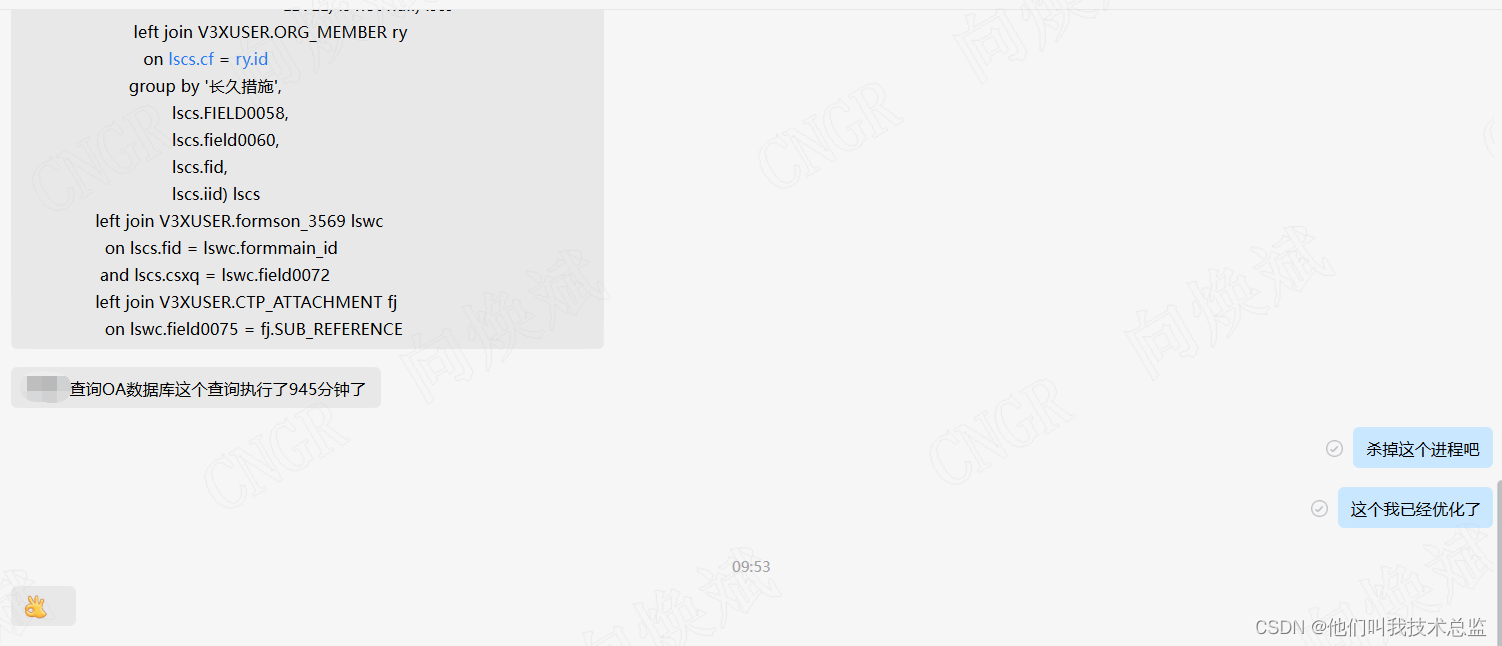
2、换个思路
其实我们仔细分析下需求,我们发现,使用connect by 是为了将责任人拆分为多行来存储,但是在展示的时候又需要使用listegg将责任人组合在一起来展示。那有没有一种办法直接在展示的时候处理呢?
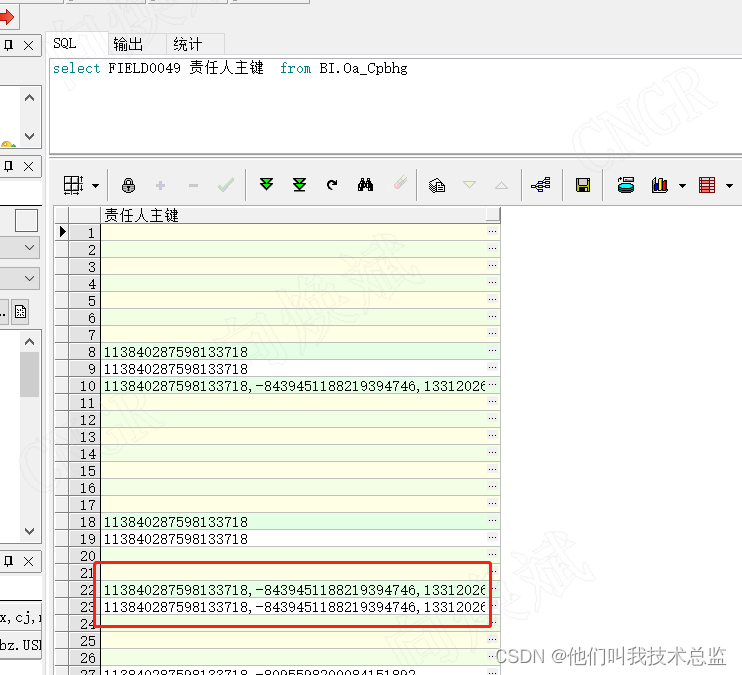
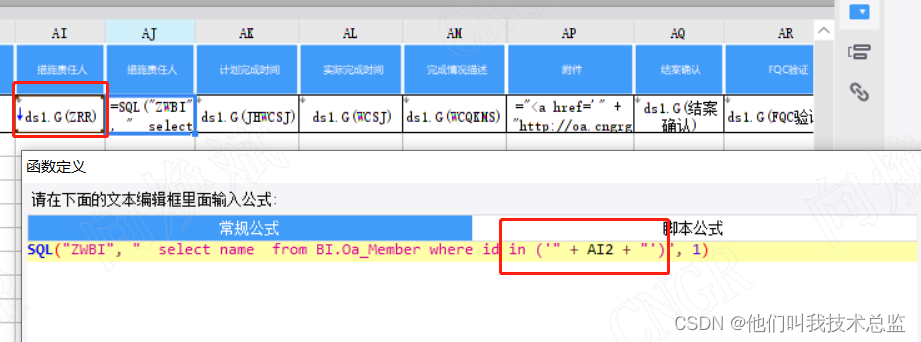
如上图所示,对应责任人主键使用逗号分离的,是不是和in('A','B','C','D')似曾相识。因此我们在展示的时候,使用类似select name from BI.Oa_Member where id in ('" + AI2 + "')来获取责任人的名称就ok了,bingo~。希望你下次遇到connect by 相关问题的时候,会对你有所启发~
这篇关于oracle connect by很强,但是要慎用,不然有你哭的时候的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






