本文主要是介绍更灵活的定位内存地址的方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 更灵活的定位内存地址的方法
- and和or指令
- 关于ASCII码
- 以字符形式给出的数据
- 大小写转换的问题
- [bx+idata]
- 用[bx+idata]的方式进行数组的处理
- SI和DI
- [bx+si]和[bx+di]
- [bx+si+idata]和[bx+di+idata]
- 不同的寻址方式的灵活应用
- 题目示例
更灵活的定位内存地址的方法
and和or指令
1)and 指令:逻辑与指令,按位进行与运算。
如 mov al, 01100011B
and al, 00111011B
执行后:al = 00100011B
通过该指令可将操作对象的相应位设为0,其他位不变。
2)or 指令:逻辑或指令,按位进行或运算。
如 mov al, 01100011B
and al, 00111011B
执行后:al = 01111011B
通过该指令可将操作对象的相应位设为1,其他位不变。
关于ASCII码
世界上有很多编码方案,有种方案叫做ASCII编码,是在计算机系统中通常被采用的。
简单地说,所谓编码方案,就是一套规则,它约定了用什么样的信息来表示现实对象。
比如说,在ASCII编码方案中,用 61H 表示“a”,62H表示“b”。
以字符形式给出的数据
我们可以在汇编程序中,用 '…'的方式指明数据是以字符的形式给出的,编译器将把它们转化为相对应的ASCII码。
assume ds:data
data segmentdb 'unIX' db 'foRK'
data endscode segmentstart: mov al,'a'mov bl,'b'mov ax,4c00hint 21h
code ends
end start 上面的源程序中:
“db ‘unIX’ ” 相当于“db 75H,6EH,49H,58H”, “u”、 “n”、 “I”、 “X”的ASCII码分别为75H、6EH、49H、58H;
“db ‘foRK’ ” 相当于“db 66H,6FH,52H,4BH”, “u”、 “n”、 “I”、 “X”的ASCII码分别为66H、6FH、52H、4BH;
“mov al,’a’”相当于“mov al,61H”,”a”的ASCII码为61H;
“mov al,’b’”相当于“mov al,62H”,”b”的ASCII码为62H。
大小写转换的问题
我们知道同一个字母的大写字符和小写字符对应的 ASCII 码是不同的,比如 “A” 的 ASCII 码是41H,“a”的ASCII码是61H。
要改变一个字母的大小写,实际上就是要改变它所对应的ASCII 码。
我们可以看出来,小写字母的ASCII码值比大写字母的ASCII码值大20H 。
一个字母,不管它原来是大写还是小写,将它的第5位置0,它就必将变为大写字母;将它的第5位置1,它就必将变为小写字母。
代码如下:
assume cs: codesg, ds: datasgdatasg segmentdb 'BaSic"db 'iNfOrMaTiOn'
datasg endscodesg segmentstart: mov ax,datasgmov ds,ax ;设置ds指向datasg段mov bx,0 ;设置(bx)=0,ds:bx指向'BaSiC’的第一个字母mov cx,5 ;设置循环次数5,因为'BaSic1有5个字母s: mov al,[bx] ;将ASCII码从ds:bx所指向的单元中取出and al,11011111B ;将al中的ASCII码的第5位置为0,变为大写字母mov [bx],al ;将转变后的ASCII码写回原单元inc bx ;(bx)加1,ds:bx指向下一个字母loop smov bx,5 ;设置(bx)=5,ds:bx指向'iNfOrMaTiOn'的第一个字母mov cx,11 ;设置循环次数11,因为'iNfOrMaTiOn'有11个字母s0: mov al,[bx]or al,00100000B ;将al中的ASCII码的第5位置为1,变为小写字母mov [bx],alinc bxloop somov ax,4c00hint 21h
codesg ends
end start
[bx+idata]
我们可以用一种更为灵活的方式来指明内存单元: [bx+idata]表示一个内存单元,它的偏移地址为(bx)+idata(bx中的数值加上idata)。
用[bx+idata]的方式进行数组的处理
在codesg中填写代码,将datasg中定义的第一个字符串,转化为大写,第二个字符串转化为小写。
assume cs:codesg,ds:datasg
datasg segment
db 'BaSiC'
db 'MinIX'
datasg endscodesg segmentstart: ……
codesg ends
end start我们观察datasg段中的两个字符串,一个的起始地址为0,另一个的起始地址为5。
我们可以将这两个字符串看作两个数组,一个从0地址开始存放,另一个从5开始存放。
我们观察datasg段中的两个字符串,一个的起始地址为0,另一个的起始地址为5。
我们可以将这两个字符串看作两个数组,一个从0地址开始存放,另一个从5开始存放。
mov ax,datasgmov ds,axmov bx,0mov cx,5
s: mov al,[bx] ;定位第一个字符串的字符and al,11011111bmov [bx],almov al,[5+bx] ;定位第二个字符串的字符or al,00100000bmov [5+bx],alinc bxloop sSI和DI
SI和DI是8086CPU中和bx功能相近的寄存器,但是SI和DI不能够分成两个8 位寄存器来使用。
用寄存器SI和DI实现将字符串‘welcome to masm!’复制到它后面的数据区中。
assume cs:codesg,ds:datasg
datasg segment db 'welcome to masm!'db '................'
datasg ends
因为 “welcome to masm!”从偏移地址0开始存放,长度为 16 个字节,所以,它后面的数据区的偏移地址为 16 ,就是字符串所要存放的空间。
我们用ds:si 指向要复制的源始字符串,用 ds:di 指向复制的目的空间,然后用一个循环来完成复制。
代码如下:
codesg segment
start: mov ax,datasgmov ds,axmov si,0mov di,16mov cx,8s: mov ax,[si]mov [di],axadd si,2add di,2loop smov ax,4c00hint 21h
codesg ends
end start
[bx+si]和[bx+di]
[bx+si]表示一个内存单元,它的偏移地址为(bx)+(si)(即bx中的数值加上si中的数值)。([bx+di]同理)
mov ax,[bx+si]的含义:
将一个内存单元的内容送入ax,这个内存单元的长度为2字节(字单元),存放一个字,偏移地址为bx中的数值加上si中的数值,段地址在ds中。
[bx+si+idata]和[bx+di+idata]
[bx+si+idata]表示一个内存单元,它的偏移地址为(bx)+(si)+idata。(即bx中的数值加上si中的数值再加上idata)
指令mov ax,[bx+si+idata]的含义:
将一个内存单元的内容送入ax,这个内存单元的长度为2字节(字单元),存放一个字,偏移地址为bx中的数值加上si中的数值再加上idata,段地址在ds中。
该指令也可以写成如下格式(常用):
- mov ax,[bx+200+si]
- mov ax,[200+bx+si]
- mov ax,200[bx][si]
- mov ax,[bx].200[si]
- mov ax,[bx][si].200
不同的寻址方式的灵活应用
如果我们比较一下前面用到的几种定位内存地址的方法(可称为寻址方式),就可以发现有以下几种方式:
1)[idata] 用一个常量来表示地址,可用于直接定位一个内存单元;
2)[bx] 用一个变量来表示内存地址,可用于间接定位一个内存单元;
3)[bx+idata] 用一个变量和常量表示地址,可在一个起始地址的基础上用变量间接定位一个内存单元;
4)[bx+si] 用两个变量表示地址;
5)[bx+si+idata] 用两个变量和一个常量表示地址。
题目示例
1)编程,将datasg段中每个单词的头一个字母改为大写字母。
assume cs:codesg,ds:datasg
datasg segmentdb '1. file 'db '2. edit 'db '3. search 'db '4. view 'db '5. options 'db '6. help '
datasg endscodesg segmentstart:……
codesg ends
end start
datasg中的数据的存储结构,如图:
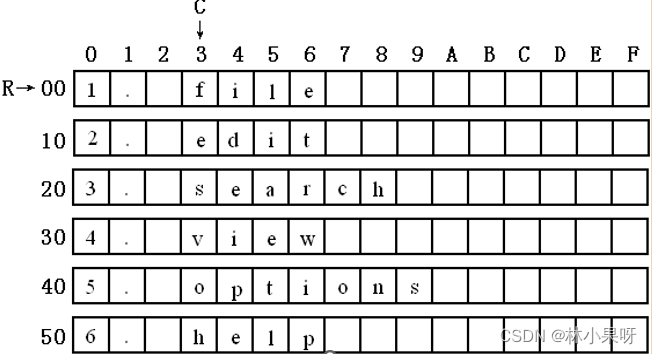
我们可以看到:在datasg中定义了6个字符串,每个长度为16字节。(注意,为了直观,每个字符串的后面都加上了空格符,以使它们的长度刚好为16字节)
我们用bx作变量,定位每行的起始地址,用3定位要修改的列,用[bx+idata]的方式来对目标单元进行寻址。
程序如下:
mov ax,datasg
mov ds,ax
mov bx,0
mov cx,6
s: mov al,[bx+3]and al,11011111b mov [bx+3],al add bx,16
loop s
2)编程:将datasg段中每个单词改为大写字母。
assume cs:codesg,ds:datasg
datasg segmentdb 'ibm 'db 'dec 'db 'dos 'db 'vax '
datasg endscodesg segmentstart: ……
codesg ends
end start
在datasg中定义了4个字符串,每个长度为16字节。(注意,为了使我们在Debug 中可以直观地查看,每个字符串的后面都加上了空格符,以使它们的长度刚好为16byte)
因为它们是连续存放的,我们可以将这 4 个字符串看成一个 4行16列的二维数组。
按照要求,我们需要修改每一个单词,即二维数组的每一行的前3列。
我们用bx来作变量,定位每行的起始地址,用si 定位要修改的列,用 [bx+si] 的方式来对目标单元进行寻址。
我们需要用到二重循环,应该在每次开始内层循环的时候,将外层循环的cx中的数值保存起来,在执行外层循环的loop指令前,再恢复外层循环的cx数值。
我们可以用dx来暂时存放cx中的值,但在程序较为复杂的情况下dx有可能已被占用。
因此在需要暂存数据的时候,我们都应该使用栈,栈空间在内存中,采用相关的指令,如:push、pop等,可对其进行特殊的操作。
程序如下:
assume cs:codesg,ds:datasg,ss:stacksg
datasg segmentdb 'ibm ' db 'dec ' db 'dos ' db 'vax '
datasg endsstacksg segmentdw 0,0,0,0,0,0,0,0 ;定义一个段,用来做栈段,容量为16个字节
stacksg endscodesg segmentstart: mov ax,stacksgmov ss,axmov sp,16mov ax,datasgmov ds,axmov bx,0mov cx,4s0: push cx ;将外层的cx值压栈mov si,0 mov cx,3 ;设置内层循环的次数s: mov al,[bx+si]and al,11011111b mov [bx+si],al inc siloop sadd bx,16 pop cx ;从栈顶弹出源cx的值,恢复cxloop sO ;外层循环的loop指令将cx中的计数值-1mov ax,4c00Hint 21Hcodesg ends
end start
3)编程,将datasg段中每个单词的前四个字母改为大写字母。
assume cs:codesg,ds:datasg,ss:stacksg
stacksg segmentdw 0,0,0,0,0,0,0,0
stacksg ends
datasg segmentdb '1. display......'db '2. brows........'db '3. replace......'db '4. modify.......'
datasg ends
codesg segment
start: ……
codesg ends
end start
由于数据是连续存放的,我们可以将这4个字符串看成一个4行16列的二维数组,按照要求,我们需要修改每个单词的前四个字母,即二维数组的每一行的3~6列。
我们需要进行4x4次的二重循环,用变量R定位行,常量3定位每行要修改的起始列,变量C定位相对于起始列的要修改的列。
程序如下:
assume cs:codesg,ds:datasg,ss:stacksgstacksg segmentdw 0,0,0,0,0,0,0,0
stacksg endsdatasg segmentdb '1. display......'db '2. brows........'db '3. replace......'db '4. modify.......'
datasg endscodesg segmentstart: mov ax,stacksgmov ss,axmov sp,16mov ax,datasgmov ds,axmov bx,0mov cx,4s0: push cxmov si,4mov cx,4s: mov al,[bx+si]add al,11011111binc siloop spop cxadd bx,16loop s0mov ax,4c00Hint 21Hcodesg ends
end start
这篇关于更灵活的定位内存地址的方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




