本文主要是介绍Gemma开源AI指南,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
近几个月来,谷歌推出了 Gemini 模型,在人工智能领域掀起了波澜。 现在,谷歌推出了 Gemma,再次引领创新潮流,这是向开源人工智能世界的一次变革性飞跃。
与前代产品不同,Gemma 是一款轻量级、小型模型,旨在帮助全球开发人员负责任地构建 AI 解决方案,与 Google 的 AI 原则紧密结合。 这一具有里程碑意义的举措标志着人工智能技术民主化的重要时刻,为开发人员和研究人员提供了前所未有的使用尖端工具的机会。
作为一个开源模型,Gemma 不仅使最先进的人工智能技术的获取变得民主化,还鼓励全球开发者、研究人员和爱好者社区为其进步做出贡献。 这种协作方法旨在加速人工智能创新,消除障碍并培育共享知识和资源的文化。
在本文中,我们将使用 Keras 探索 Gemma 模型,并尝试一些文本生成任务的实验,包括问答、摘要和模型微调。
1、什么是Gemma
Gemma 是 Google AI 系列的最新成员,由轻量级的顶级开放模型组成,这些模型源自为 Gemini 模型提供动力的相同技术。 这些文本到文本、仅限解码器的大型语言模型以英语提供,提供开放权重、预训练变体和指令调整变体。 Gemma 模型在各种文本生成任务中表现出色,例如回答问题、摘要和推理。 其紧凑的尺寸有助于在笔记本电脑、台式机或个人云基础设施等资源有限的环境中进行部署,实现对尖端人工智能模型的民主化访问并刺激所有人的创新。
Gemma的主要特性如下:
- 模型尺寸:Google 推出了两种尺寸的 Gemma 模型:Gemma 2B 和 Gemma 7B,每种模型都提供预训练和指令调整的变体。
- Responsible AI 工具包:Google 推出了 Responsible Generative AI 工具包,帮助开发人员使用 Gemma 创建更安全的 AI 应用程序。
- 用于推理和微调的工具链:开发人员可以通过本机 Keras 3.0 利用工具链在 JAX、PyTorch 和 TensorFlow 等主要框架中进行推理和监督微调 (SFT)。
轻松部署:经过预训练和指令调整的 Gemma 模型可部署在笔记本电脑、工作站或 Google Cloud 上。 它们可以轻松部署在 Vertex AI 和 Google Kubernetes Engine (GKE) 上。 - 性能:与其他开放式模型相比,Gemma 模型在其尺寸方面实现了顶级性能。 它们在关键基准上的表现明显优于更大的模型,同时保持安全和负责任的输出的严格标准。
2、Gemma vs. Gemini
谷歌表示,Gemma 虽然与 Gemini 不同,但与其共享重要的技术和基础设施组件。 这一共同的基础使 Gemma 2B 和 Gemma 7B 能够相对于其他类似尺寸的开放式模型实现“一流的性能”。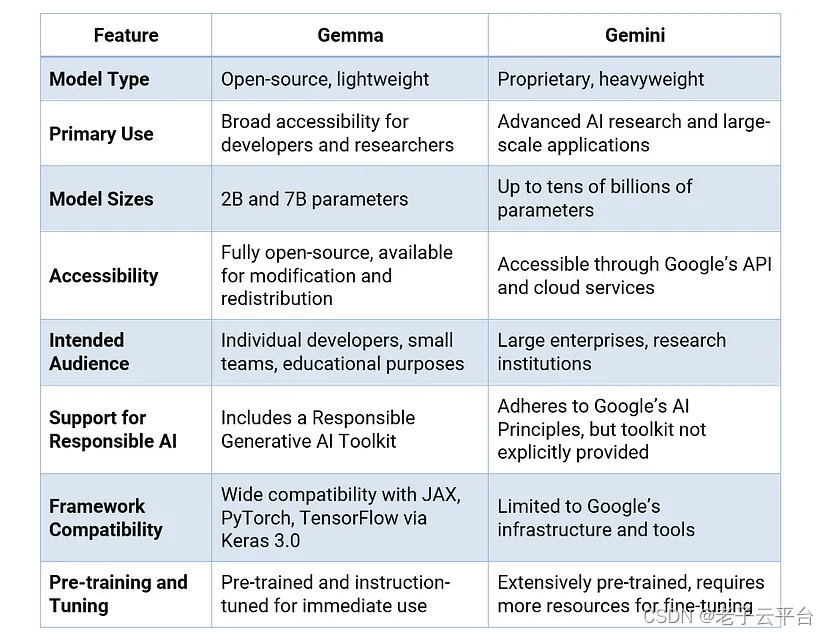
3、Gemma vs. Llama 2
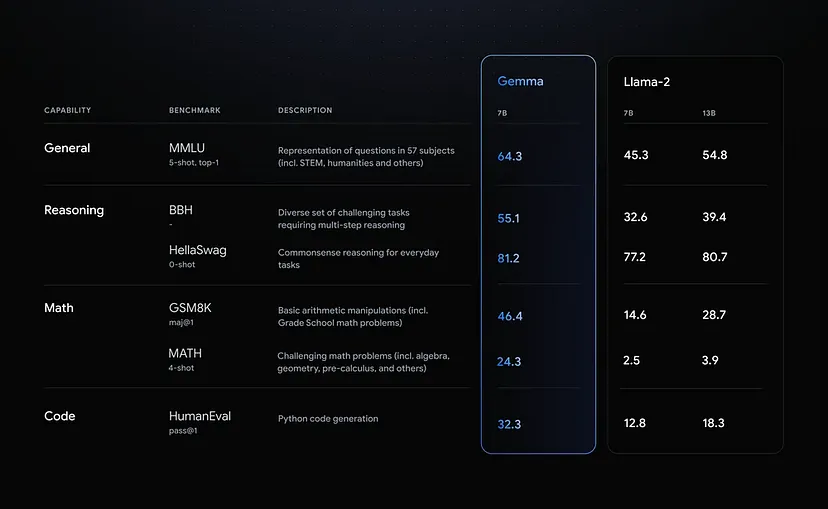
Google 将 Gemma 7B 与 Meta 的 Llama 2 7B 在推理、数学和代码生成等各个领域进行了比较。 Gemma 在所有基准测试中均显着优于 Llama 2。 例如,在推理方面,Gemma 在 BBH 基准测试中得分为 55.1,而 Llama 2 的得分为 32.6。 数学方面,Gemma 在 GSM8K 基准测试中得分为 46.4,而 Llama 2 得分为 14.6。 Gemma 在解决复杂问题方面也表现出色,在 MATH 4-shot 基准测试中得分为 24.3,超过了 Llama 2 的 2.5 分。 此外,在 Python 代码生成方面,Gemma 得分为 32.3,超过了 Llama 2 的 12.8 分。
Gemma 可在 Colab 和 Kaggle 笔记本上轻松使用,并与 Hugging Face、NVIDIA、NeMo、MaxText 和 TensorRT-LLM 等流行工具无缝集成。 此外,开发人员还可以通过 Keras 3.0 利用 Google 的工具链在 JAX、PyTorch 和 TensorFlow 等领先框架中进行推理和监督微调 (SFT)。
4、实验1:Gemma与 KerasNLP的结合
KerasNLP 提供了对 Gemma 模型的便捷访问,使研究人员和从业者能够轻松探索和利用其功能来满足他们的需求。
4.1 启用模型访问权限
Gemma-7b 是一个受控模型,需要用户请求访问。按照如下步骤启用模型访问。
- 登录你的 Kaggle 帐户或注册一个新帐户(如果还没有帐户)。
- 使用这个链接打开 Kaggle上的Gemma 模型页面。
- 在 Gemma 模型页面上,单击“请求访问”链接以请求访问模型。
- 在下一页上提供你的名字、姓氏和电子邮件 ID。
- 在接下来的页面中单击“接受”以接受许可协议。

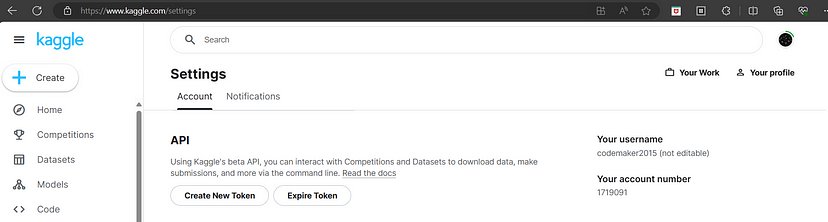
4.2 Kaggle 访问密钥生成
要访问该模型,你还需要 Kaggle 访问令牌。 可以通过转到Kaggle设置来,然后单击 API 下的“创建新令牌”按钮来创建新的访问令牌。
4.3 使用 KerasNLP 通过 Gemma 创建脚本
为了运行该模型,Gemma 需要一个具有 16GB RAM 的系统。 在本节中,我们将使用 Google Colab 而不是个人机器。 如果符合要求的规格,可以尝试在你的计算机上运行相同的代码。
- 打开链接“欢迎来到 Colaboratory — Colaboratory”,然后单击“登录”以登录到你的 Colab 帐户;如果没有帐户,则创建一个新帐户。
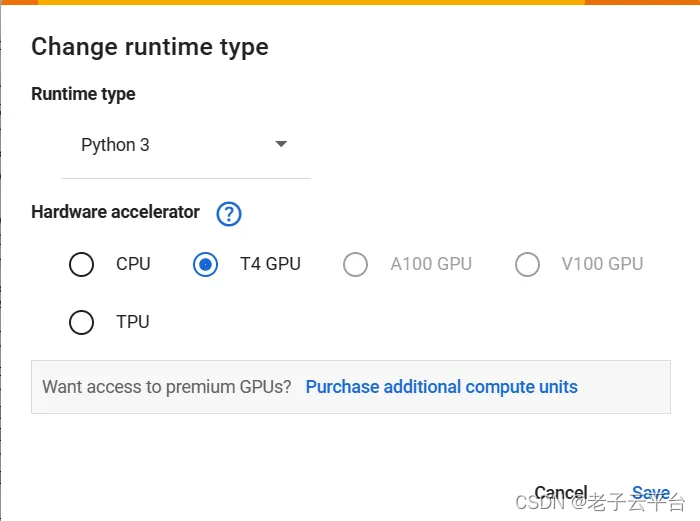
- 通过Runtime→更改运行时类型→T4 GPU→保存将Runtime更改为T4 GPU。
4.4 设置环境变量
要使用 Gemma,你必须提供 Kaggle 访问令牌。 在左侧窗格中选择 Secrets (🔑),然后添加你的 KAGGLE_USERNAME 和 KAGGLE_KEY。
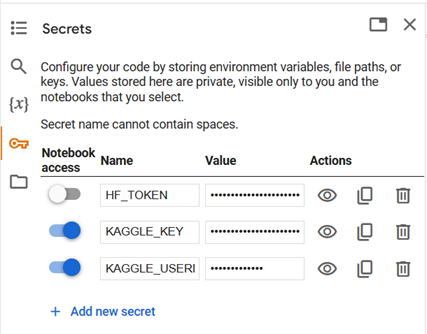
单击 + 新笔记本 按钮创建新的 Colab 笔记本。 设置 KAGGLE_USERNAME 和 KAGGLE_KEY 的环境变量。
import os
from google.colab import userdataos.environ["KAGGLE_USERNAME"] = userdata.get('KAGGLE_USERNAME')
os.environ["KAGGLE_KEY"] = userdata.get('KAGGLE_KEY')4.5 安装依赖项
使用以下命令安装访问 gemma 模型所需的 python 库。 单击播放图标以执行单元格。
!pip install -q -U keras-nlp
!pip install -q -U keras>=34.6 导入包
导入 Keras 和 KerasNLP。
import keras
import keras_nlp4.7 选择后端
Keras 适用于 TensorFlow、JAX 和 Torch。 选择 jax 作为本部分的后端。
import os
os.environ["KERAS_BACKEND"] = "jax"4.8 创建模型
在本教程中,我们将使用 GemmaCausalLM 创建一个模型,这是一个用于因果语言建模的端到端 Gemma 模型。 使用 from_preset 方法创建模型。 from_preset 根据预设的架构和权重实例化模型。
gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_2b_en")
使用 summary获取有关模型的更多信息:
gemma_lm.summary()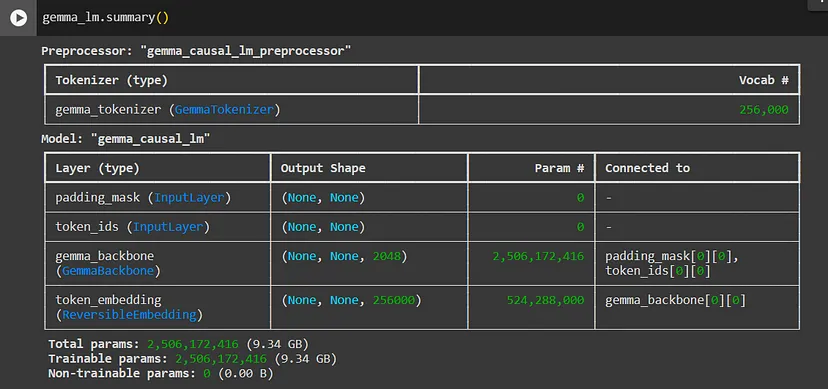
4.9 生成文本
gemma 模型有一个生成方法,可以根据提示生成文本。 可选的 max_length 参数指定生成序列的最大长度。
gemma_lm.generate("What is the meaning of life?", max_length=64)
gemma_lm.generate("How does the brain work?", max_length=64)

还可以使用列表作为输入来提供批量提示:
gemma_lm.generate(["What is the meaning of life?","How does the brain work?"],max_length=64)
5、实验2:使用HuggingFace的Gemma模型
通过 Hugging Face 平台可以方便地访问和使用 Gemma 模型。 该模型易于探索,使研究人员和实践者能够发挥其潜力。
5.1 启用 Gemma-7b 访问
Gemma-7b 是一个受控模型,需要用户请求访问。

按照步骤启用模型访问:
- 登录你的 Hugging Face 帐户或注册一个新帐户(如果还没有帐户)。
- 可以访问这里请求访问权限。

访问链接后,请确认许可协议。 然后,你将被定向到一个页面,可以在其中授权 Kaggle 分享你的 HuggingFace 详细信息。
确认许可后,继续授权 Kaggle 分享你的 Hugging Face 详细信息。 为了进一步访问,此步骤是必需的。
授权 Kaggle 后,将被重定向到显示许可协议的页面。 单击“接受”按钮即同意条款和条件。
接受许可协议后,现在可以访问 Gemma-7b 模型。
要确认你的访问权限,请前往这个链接 ,如果成功访问 Gemma-7b 模型,将收到有关它的相关信息。
5.2 Hugginface访问令牌生成
要访问该模型,还需要 HuggingFace 访问令牌。 可以通过转到“设置”,然后转到左侧边栏中的“访问令牌”,然后单击“新令牌”按钮来创建新的访问令牌来生成一个。

5.3 用 HuggingFace 与 Gemma 创建一个脚本
为了运行该模型,Gemma 需要一个具有 16GB RAM 的系统。 在本节中,我们将使用 Google Colab 而不是个人机器。 如果符合要求的规格,可以尝试在你的计算机上运行相同的代码。
- 打开链接“欢迎来到 Colaboratory — Colaboratory”,然后单击“登录”以登录到你的 Colab 帐户;如果没有帐户,则创建一个新帐户。
- 通过Runtime→更改运行时类型→T4 GPU→保存将Runtime更改为T4 GPU。
- 要使用 Gemma,你必须提供 Hugging Face 访问令牌。 在左侧窗格中选择 Secrets (🔑) 并添加你的
HF_TOKEN密钥。 - 单击
+ 新笔记本按钮创建新的 Colab 笔记本。
5.4 安装依赖项
使用以下命令安装访问 gemma 模型所需的 python 库。 单击播放图标以执行单元格。
!pip install transformers torch accelerate5.5 Huggingface登录
要使用 Gemma 模型,你需要验证 Hugging Face 帐户。 将提供的代码添加到新单元格以进行 Hugging Face 登录。 单击播放图标以执行单元格。 在指定单元格中输入你的 Hugging Face 访问令牌以完成身份验证过程。

5.6 选择模型
使用以下命令访问 gemma-2b-it 模型。 你还可以尝试使用任何一种 Gemma 模型。 请访问 这个链接以了解有关其他 Gemma 模型的更多信息。
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("google/gemma-2b-it")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b-it")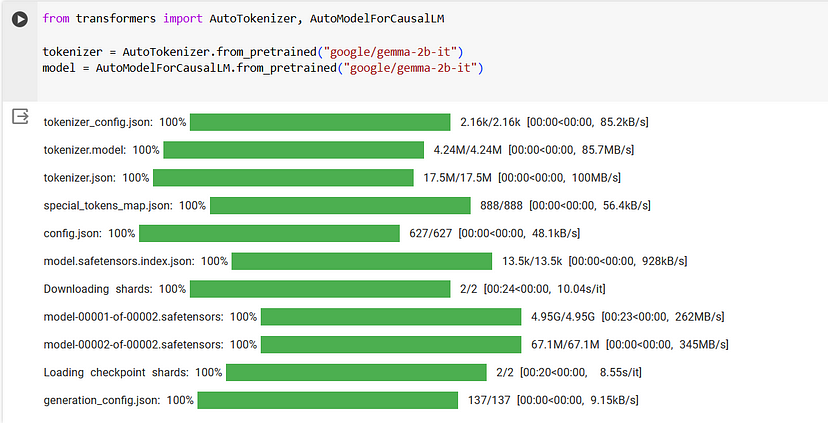
5.7 生成文本
通过执行以下代码片段来测试模型。
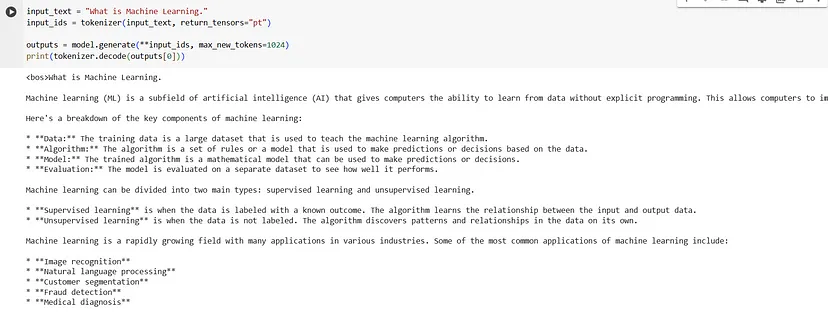
input_text = "What is Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt")outputs = model.generate(**input_ids, max_new_tokens=1024)
print(tokenizer.decode(outputs[0]))你将得到如下输出:


这篇关于Gemma开源AI指南的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




