本文主要是介绍用python爬取CSDN博客的总字数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、下载pycahrm
此处推荐博客:PyCharm安装教程,图文教程(超详细)-CSDN博客
二、安装相应的库
pycharm安装库的步骤:
1、打开pycharm;
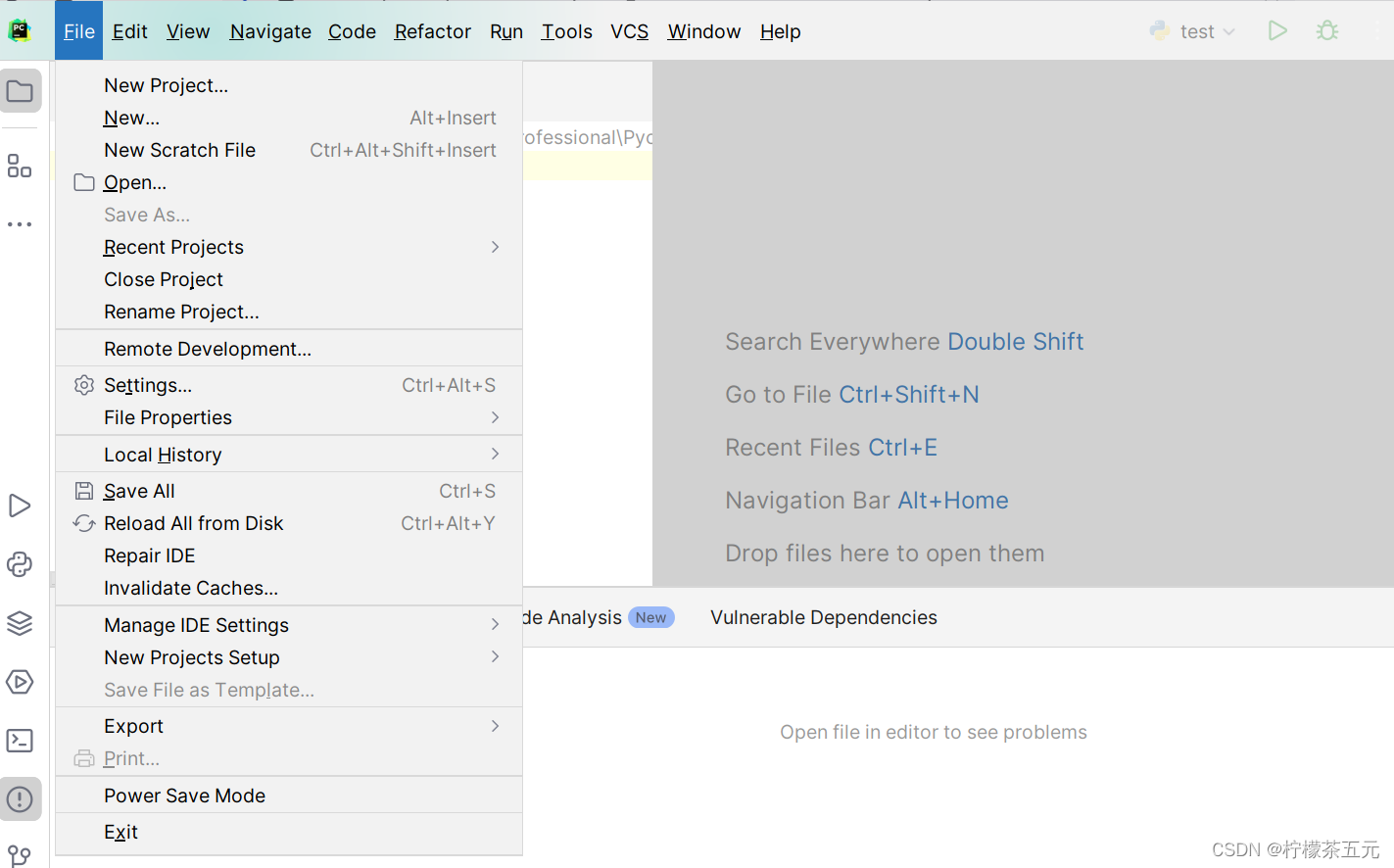
2、在菜单栏中,选择 "file">"settings";
3、左侧选择 "project: ">"python interpreter";
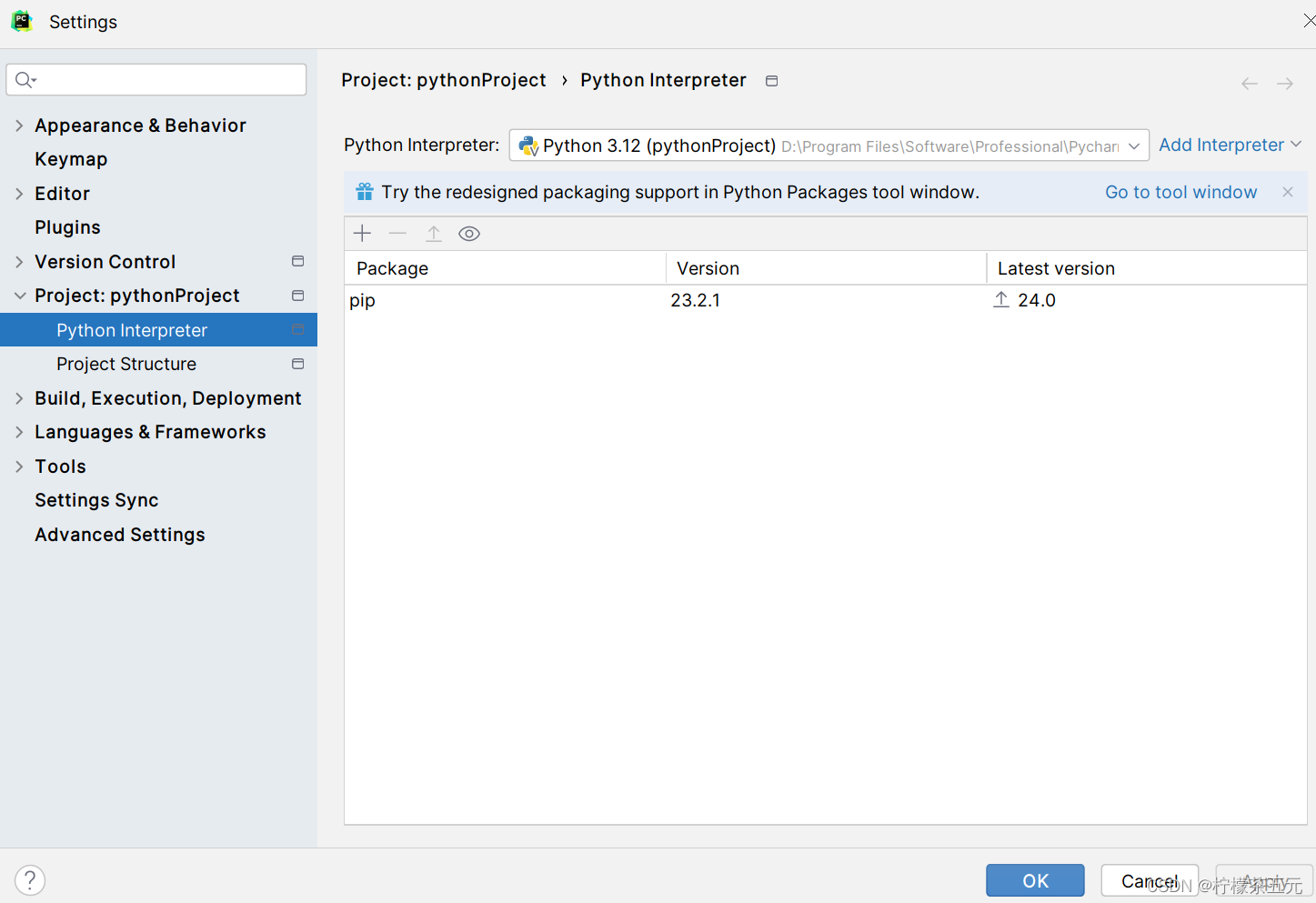
4、点击右上角的 "+" 按钮;
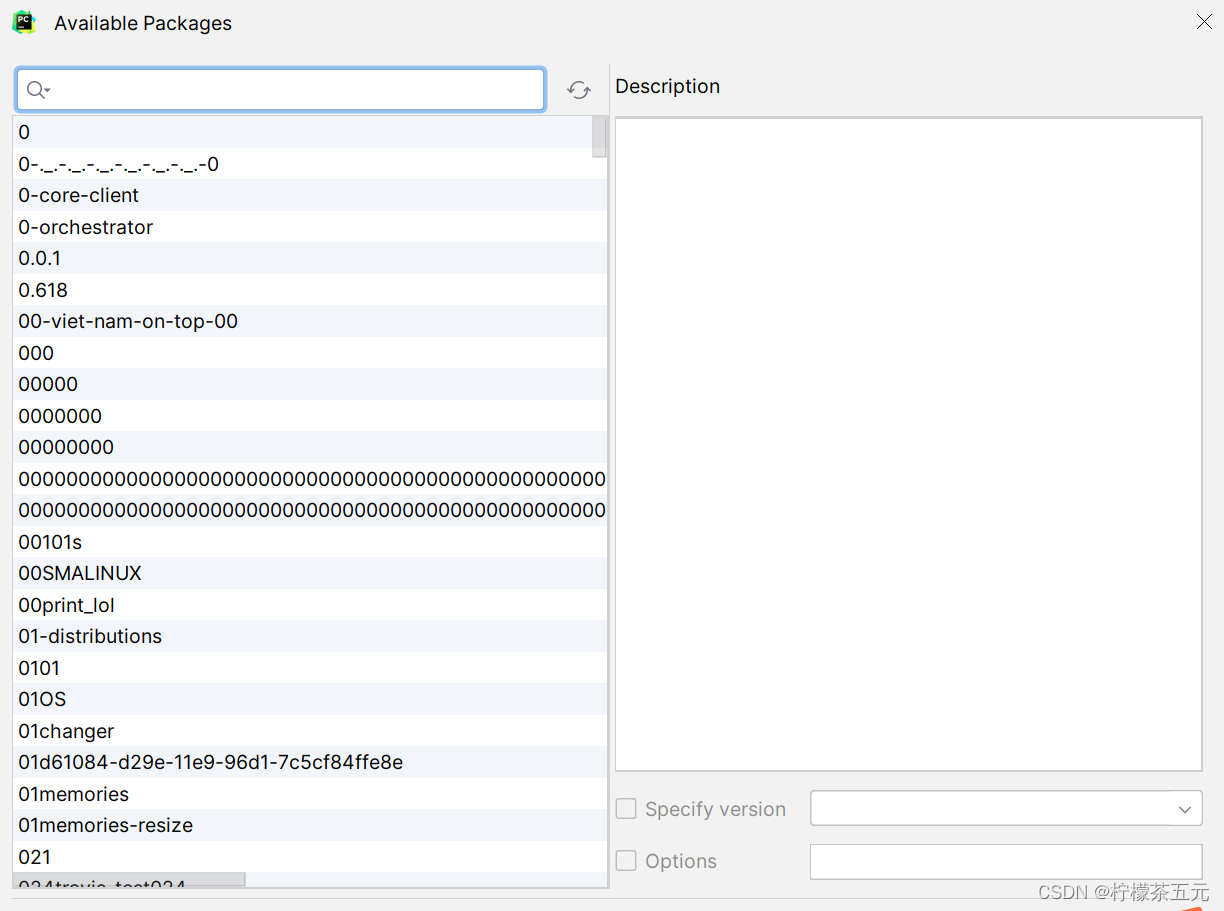
5、搜索需要的库,然后点击 "install package";【加快下载速度——option处添加镜像:-i https://pypi.tuna.tsinghua.edu.cn/simple】
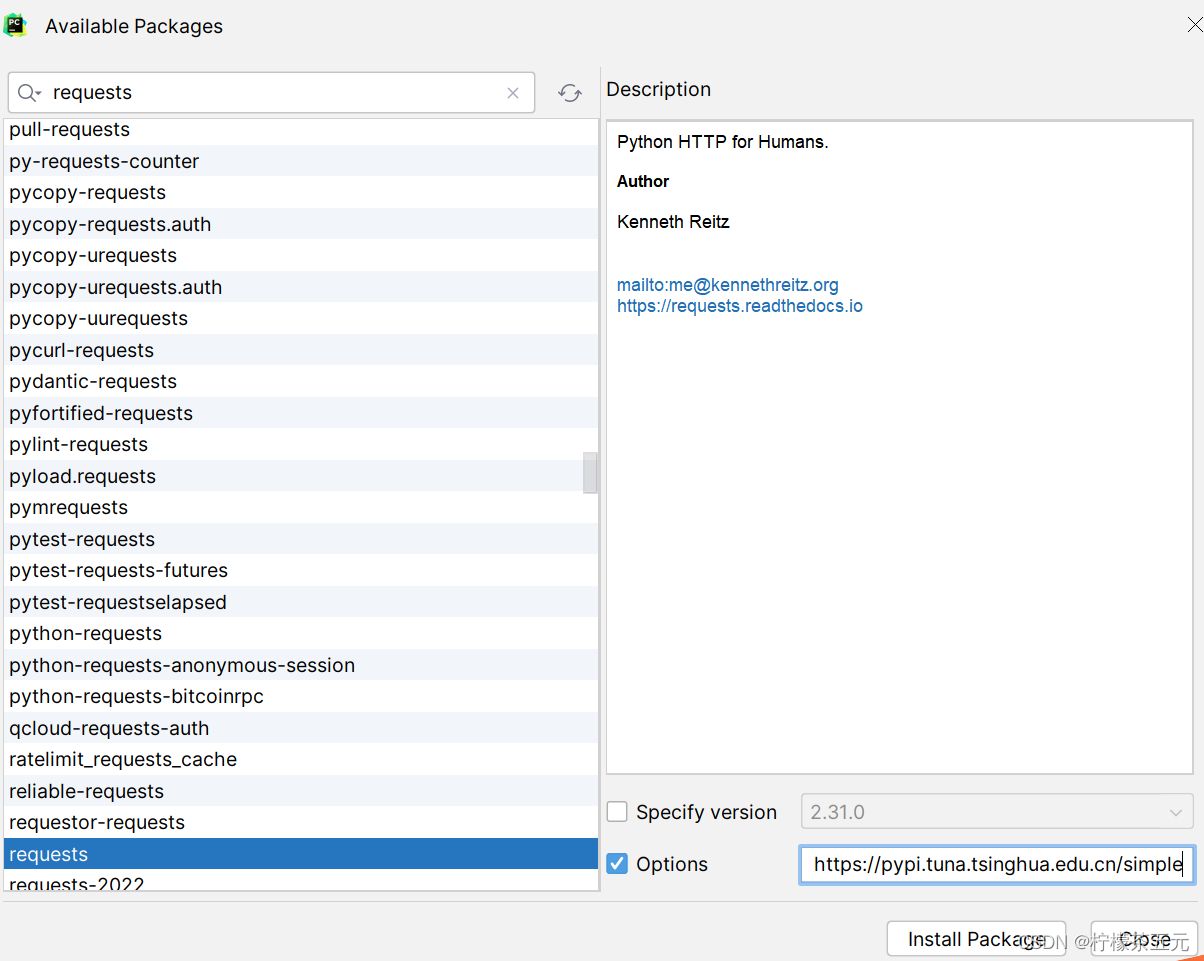
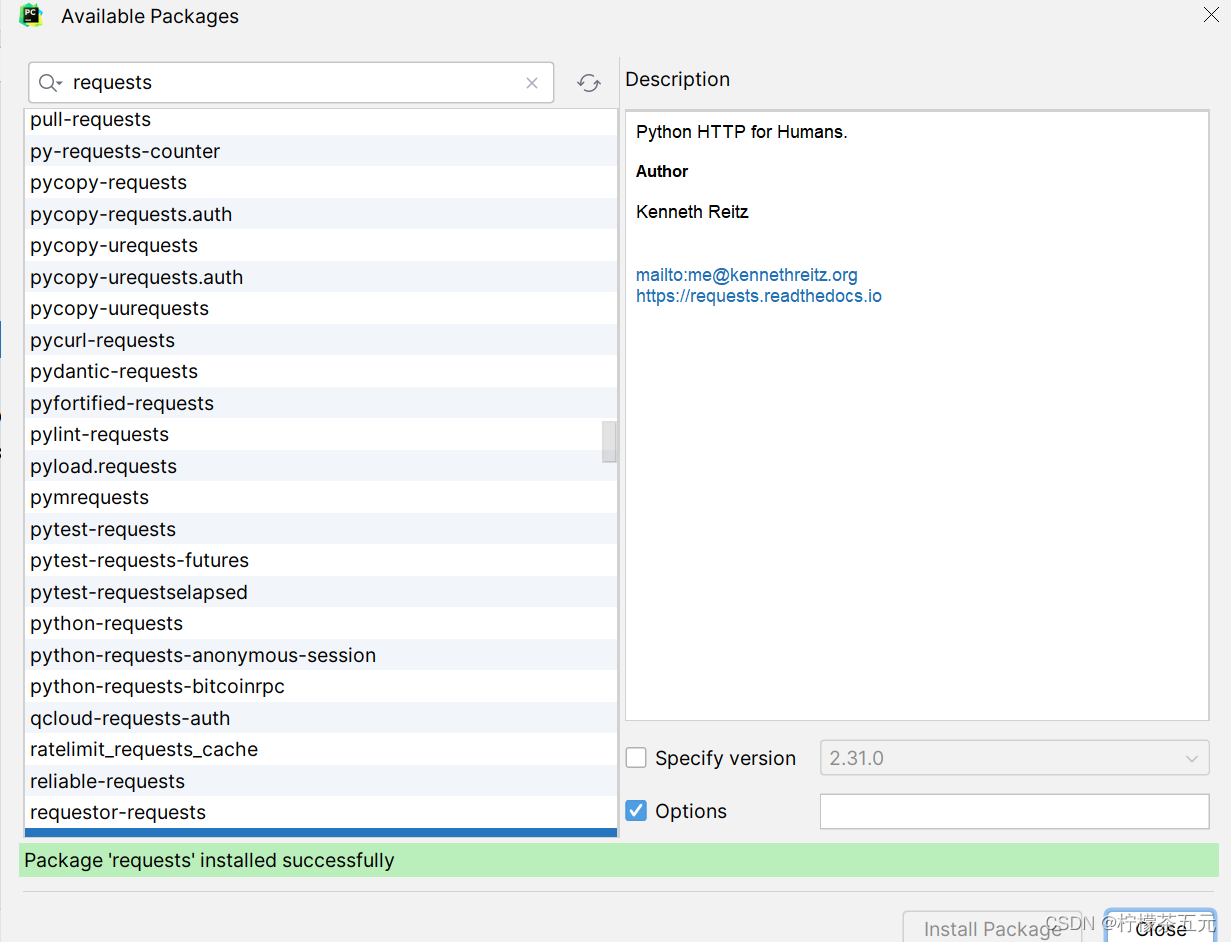
6、安装完成后,关闭对话框,点击 "ok" 保存设置即可。
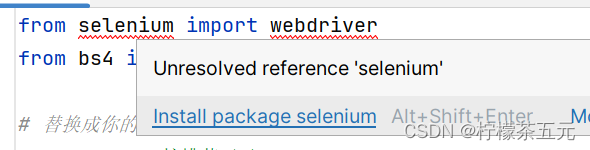
除上述操作外,还可以将鼠标放在代码中的红色波浪线下,会弹出 install 的指令点击即可。
三、建立python文件输入代码
import requests
from bs4 import BeautifulSoup
def get_csdn_blog_word_count(url):
# 发送请求获取网页内容
response = requests.get(url)
# 使用BeautifulSoup解析网页
soup = BeautifulSoup(response.text, 'html.parser')
# 查找存放文章内容的标签
content = soup.find('div', class_='markdown_views').text
# 计算字数
word_count = len(content)
return word_count
# 测试
url = 'https://blog.csdn.net/example/article/details/12345678'
print(f'博客字数:{get_csdn_blog_word_count(url)}')
四、可能出现的问题
1. File "D:\Program Files\Software\Professional\Pycharm\pyproject\pythonProject\.venv\Lib\site-packages\pip\_vendor\urllib3\response.py", line 443, in _error_catcher
raise ReadTimeoutError(self._pool, None, "Read timed out.")
pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host='files.pythonhosted.org', port=443): Read timed out.
[notice] A new release of pip is available: 23.2.1 -> 24.0
[notice] To update, run: python.exe -m pip install --upgrade pip

解决办法:更换镜像源:-i http://mirros.aliyun.com/pypi/simple/
2.ERROR: Could not find a version that satisfies the requirement webdriver (from versions: none) ERROR: No matching distribution found for webdriver [notice] A new release of pip is available: 23.2.1 -> 24.0 [notice] To update, run: python.exe -m pip install --upgrade pip
首先,更新 pip 到最新版本。运行以下命令来升级 pip:
python -m pip install --upgrade pip
接下来,安装 Selenium 库。运行以下命令来安装 selenium:
python -m pip install selenium
这篇关于用python爬取CSDN博客的总字数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





