本文主要是介绍ch6文件操作和异常处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
os.listdir(path) 函数详解
功能:
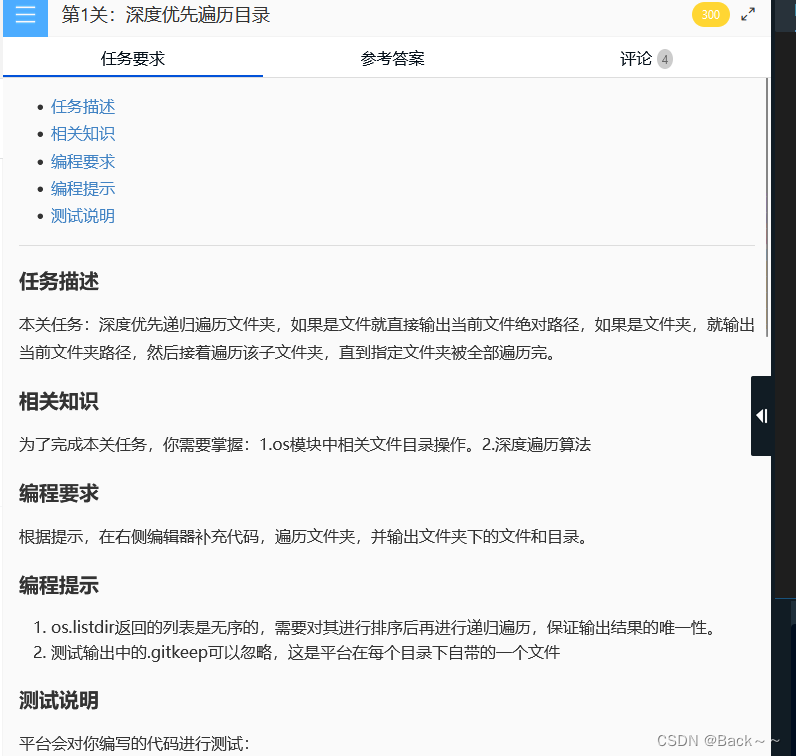
os.listdir(path) 函数用于返回指定目录下的所有文件和文件夹的名字列表,但不包括 . 和 ..。
参数:
path: 要列出的目录的路径。
返回值:
一个包含目录下所有文件和文件夹名字的列表。
示例:
import ospath = "/home/user/Desktop/my_folder"# 列出指定目录下的所有文件和文件夹
files = os.listdir(path)# 打印文件和文件夹名字
for file in files:print(file)
输出:
file1.txt
file2.txt
folder1
folder2
注意事项:
os.listdir(path)函数只返回指定目录下的直接子项,不会递归遍历子目录。- 如果目录不存在,
os.listdir(path)函数会抛出OSError异常。 os.listdir(path)函数返回的列表顺序是随机的,并非按照文件名排序。
扩展:
- 可以使用
os.walk(path)函数递归遍历目录及其子目录。 - 可以使用
os.path.isfile(path)和os.path.isdir(path)函数判断文件或文件夹是否存在。 - 可以使用
os.path.join(path, file)函数拼接文件路径。
参考资料:
- os.listdir() 函数: https://www.runoob.com/python/os-listdir.html
- os 模块: https://docs.python.org/3/library/os.html
总结:
os.listdir(path) 函数是 Python 中一个常用的函数,用于列出指定目录下的所有文件和文件夹。
collections.deque() 函数详解
功能:
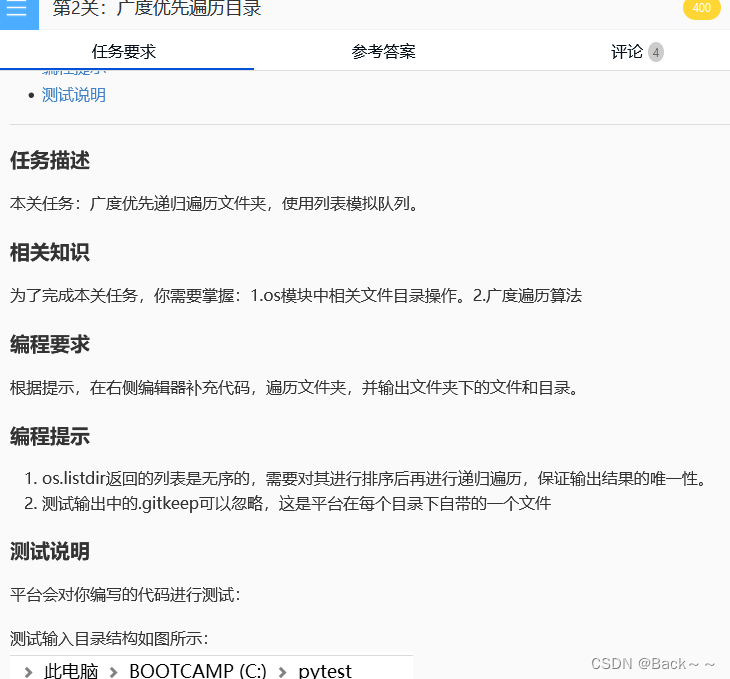
collections.deque() 函数用于创建一个双端队列,也称为双向队列。双端队列是一种特殊的队列,允许从两端插入和删除元素。
参数:
iterable: 可选参数,用于初始化队列。如果指定,则将 iterable 中的元素添加到队列中。
返回值:
一个新的双端队列对象。
示例:
from collections import deque# 创建一个空队列
queue = deque()# 从队列尾部添加元素
queue.append(1)
queue.append(2)
queue.append(3)# 从队列头部删除元素
queue.popleft()# 查看队列中元素
print(queue)
输出:
[2, 3]
deque 对象的常用方法:
append(): 将元素添加到队列尾部。appendleft(): 将元素添加到队列头部。pop(): 从队列尾部删除元素。popleft(): 从队列头部删除元素。extend(): 将 iterable 中的元素添加到队列尾部。extendleft(): 将 iterable 中的元素添加到队列头部。rotate(): 旋转队列。index(): 查找元素在队列中的位置。count(): 统计元素在队列中出现的次数。
deque 对象的优势:
- 双端队列支持从两端插入和删除元素,比列表更灵活。
- 双端队列在插入和删除元素时效率较高,特别是当队列长度较大时。
deque 对象的应用场景:
- 实现队列:双端队列可以用来实现队列数据结构,例如先进先出 (FIFO) 队列或后进先出 (LIFO) 队列。
- 实现缓存:双端队列可以用来实现缓存,例如最近最少使用 (LRU) 缓存或最近最先使用 (LFU) 缓存。
- 实现滑动窗口:双端队列可以用来实现滑动窗口,例如用于文本分析或数据流分析。
总结:
collections.deque() 函数是 Python 中一个常用的函数,用于创建双端队列。双端队列是一种特殊的队列,允许从两端插入和删除元素,具有较高的效率和灵活性,可以用于实现队列、缓存、滑动窗口等数据结构。
os.walk详解
os.walk 是 Python 的 os 模块中用于遍历目录树的函数。它可以帮助您轻松地访问目录及其所有子目录中的文件和文件夹。
功能:
- 遍历指定目录及其所有子目录。
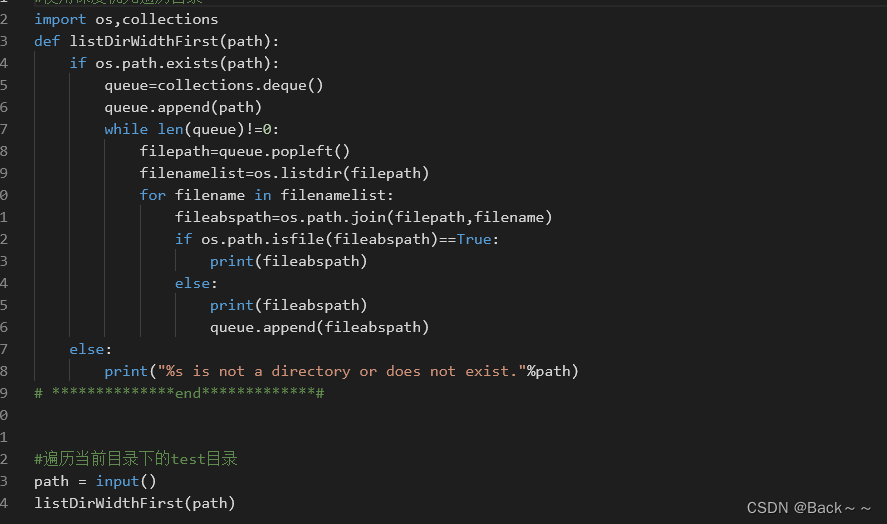
- 返回一个生成器,每次迭代都会生成一个包含三个元素的元组:
root: 当前正在遍历的目录的绝对路径。dirs: 一个包含当前目录中所有子目录名称的列表(不包含点(.)和双点(…))。files: 一个包含当前目录中所有文件名称的列表。
参数:
top: 要遍历的目录的绝对路径(字符串)。
返回值:
一个生成器,每次迭代都会生成一个包含 root、dirs 和 files 的元组。
示例:
import os# 指定要遍历的目录
top_dir = "/home/user/documents"# 遍历目录树
for root, dirs, files in os.walk(top_dir):# 打印当前目录print(f"Current Directory: {root}")# 遍历子目录for dir in dirs:print(f"\tSubdirectory: {dir}")# 遍历文件for file in files:print(f"\tFile: {file}")
输出 (示例):
Current Directory: /home/user/documentsSubdirectory: workSubdirectory: personalFile: budget.txt
Current Directory: /home/user/documents/workFile: report.docxFile: presentation.pptx
Current Directory: /home/user/documents/personalFile: journal.txtFile: photos.zip
注意事项:
os.walk函数不会对符号链接进行递归遍历。- 如果目录不存在,
os.walk函数不会抛出异常,而是会跳过该目录。 - 遍历过程是深度优先的,即会优先遍历当前目录的所有子目录,然后再返回到父目录遍历其它的子目录。
扩展:
- 可以通过修改循环逻辑来定制遍历行为,例如只遍历文件、只遍历特定类型的文件等。
- 可以结合
os.path.join函数拼接文件路径。 - 可以使用异常处理来捕获访问权限等错误。
参考资料:
- os.walk() 方法: https://www.runoob.com/python/os-walk.html
- os 模块: https://docs.python.org/3/library/os.html
总结:
os.walk 是一个功能强大的函数,可以帮助您高效地遍历目录树并访问文件和文件夹。通过理解其功能和用法,您可以轻松地编写脚本来管理文件系统中的资源。
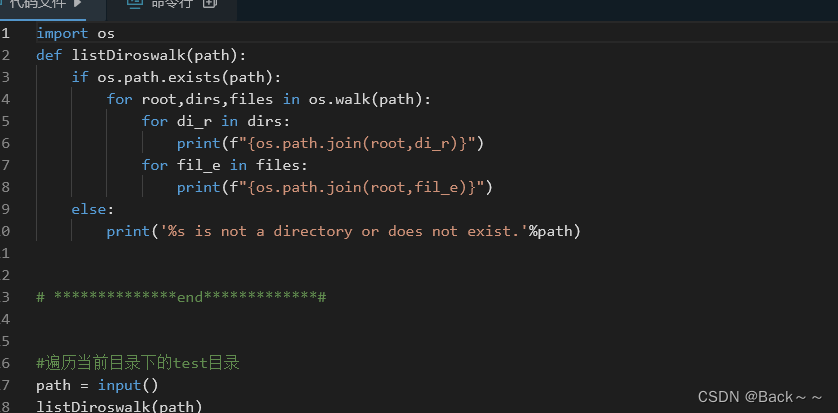
readlines () 和 readline() 函数详解
在写第四道关卡,少了一个s,差距好大
功能:
readlines()和readline()函数都是 Python 中用于读取文件内容的函数。- 两者都以字符串形式返回文件内容,但它们在读取方式和返回结果上存在一些差异。
readlines():
- 一次性读取文件所有行,并返回一个包含所有行内容的列表。
- 适用于需要一次性处理所有文件内容的情况,例如统计文件行数、搜索文件中的关键字等。
readline():
- 每次读取文件的一行,并返回该行内容。
- 适用于需要逐行处理文件内容的情况,例如读取文件并逐行输出、分析文件内容等。
示例:
# 使用 readlines() 函数读取文件
with open("my_file.txt", "r") as f:lines = f.readlines()# 统计文件行数
print(len(lines))# 使用 readline() 函数读取文件
with open("my_file.txt", "r") as f:line = f.readline()while line:# 处理文件内容print(line)line = f.readline()
输出 (示例):
5
This is the first line.
This is the second line.
This is the third line.
This is the fourth line.
This is the fifth line.
比较:
| 函数 | 读取方式 | 返回结果 | 适用场景 |
|---|---|---|---|
| readlines() | 一次性读取所有行 | 包含所有行内容的列表 | 一次性处理所有文件内容 |
| readline() | 每次读取一行 | 该行内容 | 逐行处理文件内容 |
注意事项:
readlines()函数会将文件所有内容读入内存,因此对于大型文件可能会造成内存压力。readline()函数每次只读取一行,因此对内存的压力较小,但需要循环读取文件内容,可能会降低效率。
扩展:
- 可以使用
for循环逐行读取文件内容,避免一次性读取所有内容。 - 可以使用
os.path.getsize()函数获取文件大小,以便根据文件大小选择合适的读取方式。
总结:
readlines() 和 readline() 函数是 Python 中常用的读取文件内容的函数。根据您的具体需求,可以选择合适的函数进行读取操作。

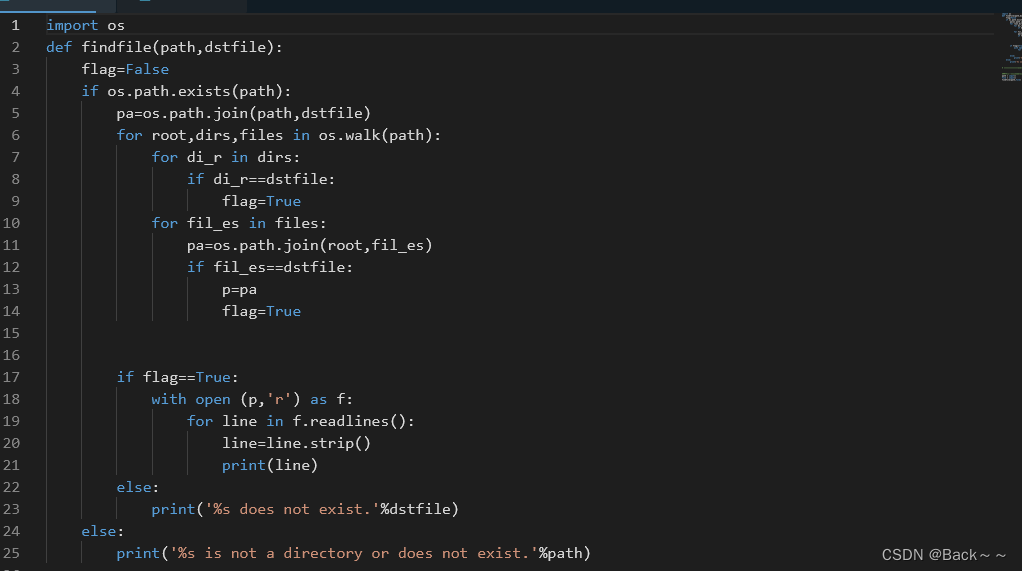
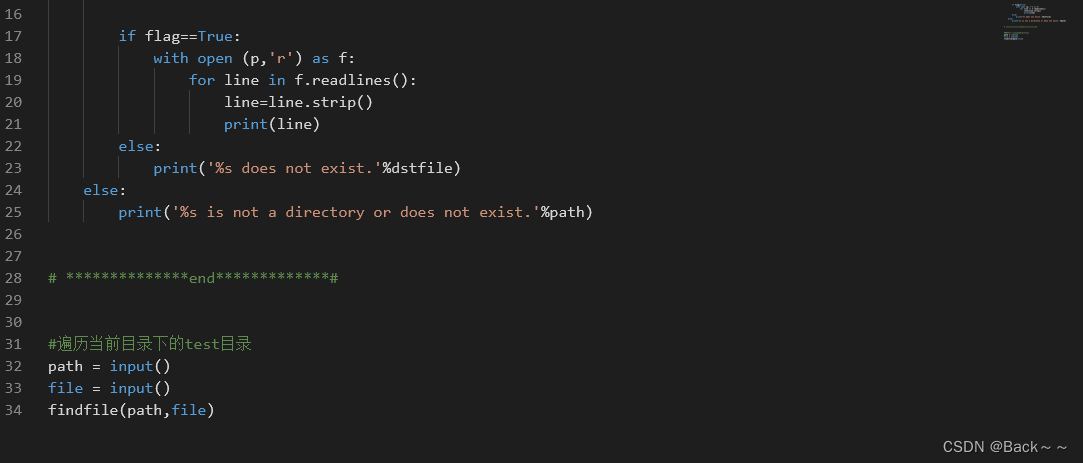
这篇关于ch6文件操作和异常处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







