本文主要是介绍Transformer的前世今生 day03(Word2Vec、如何使用在下游任务中),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前情回顾
- 由上一节,我们可以得到:
- 任何一个独热编码的词都可以通过Q矩阵得到一个词向量,而词向量有两个优点:
- 可以改变输入的维度(原来是很大的独热编码,但是我们经过一个Q矩阵后,维度就可以控制了)
- 相似词之间的词向量有了关系
- 任何一个独热编码的词都可以通过Q矩阵得到一个词向量,而词向量有两个优点:
- 但是,在NNLM(神经网络语言模型的一种)中,词向量是一个副产品,即主要目的并不是生成词向量,而是去预测下一个词是什么,所以它对预测的精度要求很高,模型就会很复杂,也就不容易去计算Q矩阵和词向量
- 模型图如下:
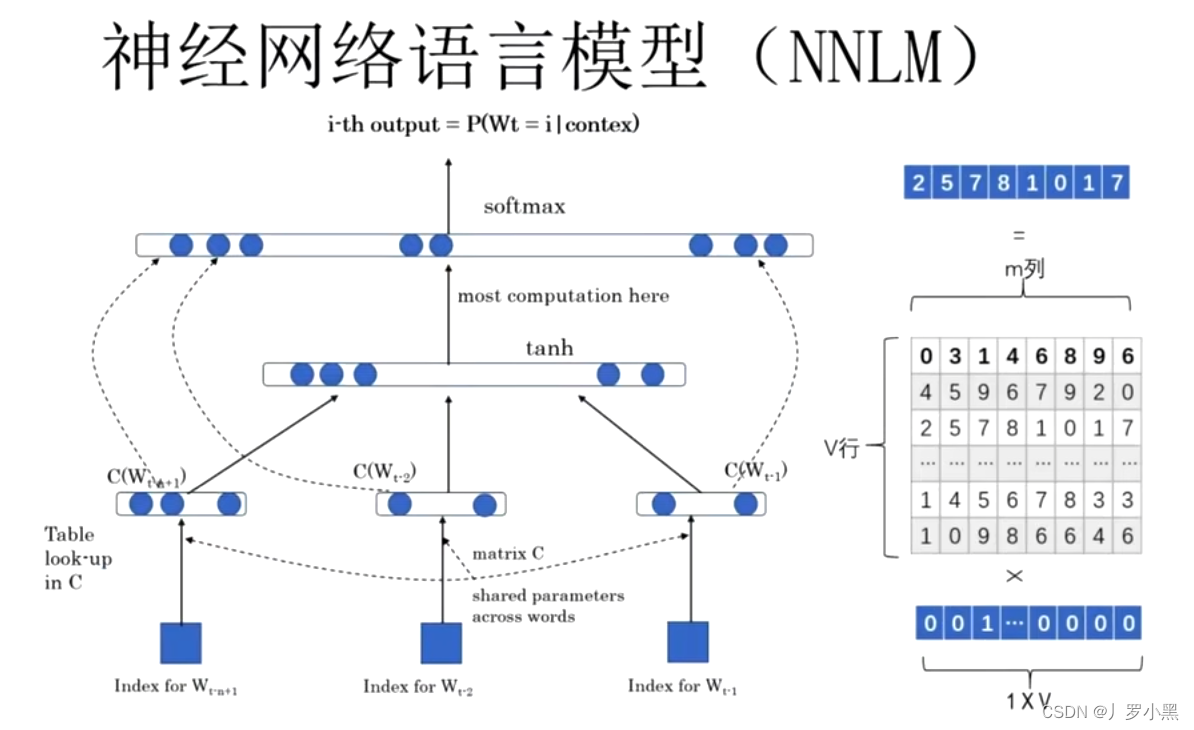
- 因此提出了一个专门生成词向量的神经网络语言模型----Word2Vec
Word2Vec
- 主要目的是生成词向量,模型图如下:
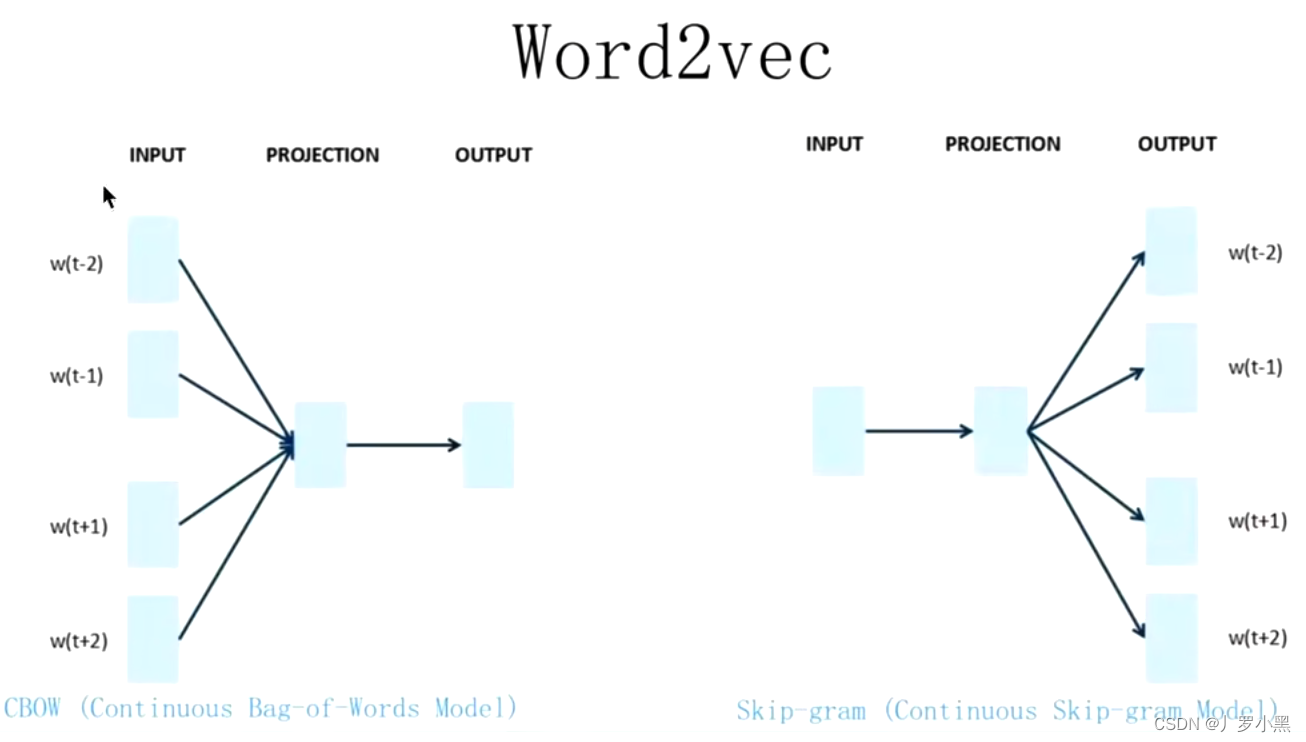
- 虽然NNLM和Word2Vec基本一致,不考虑细节,网络架构基本一致
- 但是由于Word2Vec的主要目的是生成词向量,那么对预测精度的要求可以放低,甚至只要合理,就算有多个结果也可以,因此模型不会很复杂,也就是可以更容易的计算出Q矩阵和词向量
- 所以对比NNLM,Word2Vec不用预测更准确,只需要可以正常的进行一个反向传播,可以去掉激活函数,加快计算速度,如下:

- Word2Vec的缺点:
- 词向量不能表示一词多义,如果我们在训练中给某一个词选择了一个词向量,但是在测试中,同样的词可能会有其他意思,那模型仍然不知道这个位置应该填入什么词,如下:

- 词向量不能表示一词多义,如果我们在训练中给某一个词选择了一个词向量,但是在测试中,同样的词可能会有其他意思,那模型仍然不知道这个位置应该填入什么词,如下:
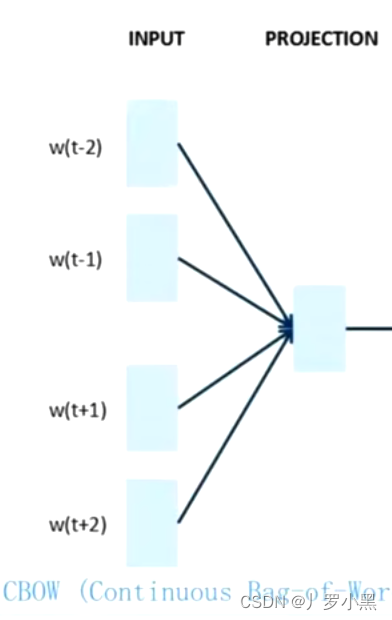
CBOW
- 给出一个词的上下文,预测这个词,如下:

- 由于Q矩阵和词向量的产生在INPUT到PROJECTION的过程中,且CBOW会有更多的Q矩阵和词向量,也就意味着它生成词向量的效率更高,如下:
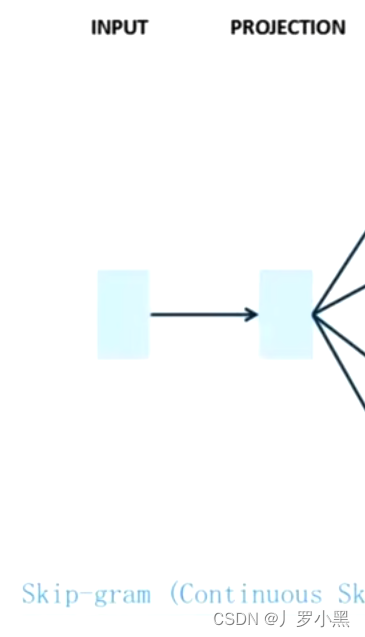
Skip-gram
- 给出一个词,得到这个词的上下文,如下:

- 相反,在Skip-gram中,我们得到Q矩阵和词向量的效率会低一些
如何将词向量使用在下游任务中
- Word2Vec是预训练模型,而预训练模型分为两种:假设给出任务A和任务B,其中对于任务A我们已经得出了一个良好的模型A,而任务B由于数据集太小或训练太复杂等其他原因,无法解决,即无法得出模型B
- 我们可以使用模型A,来辅助解决任务B
- 或者使用模型A,来加快模型B的生成
- 词向量大多数用在第二种,加快模型B的生成
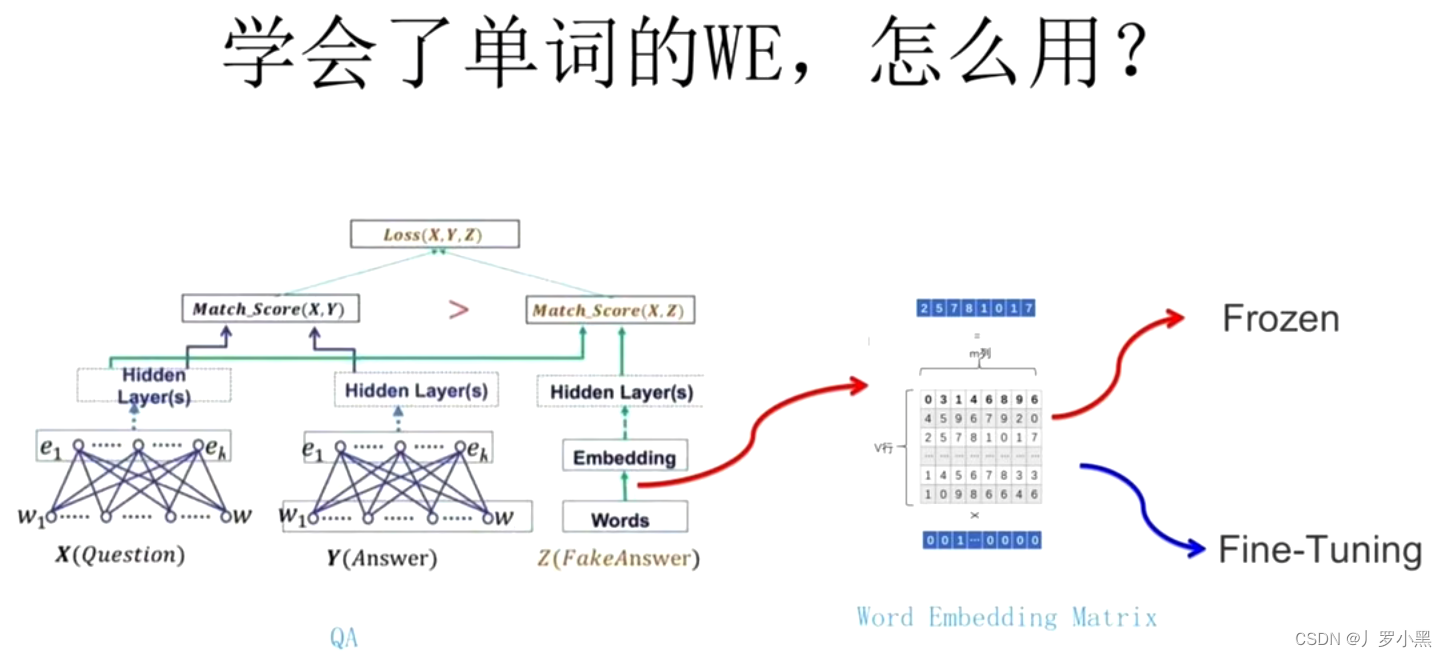
- 在经典的NLP领域中:在将输入X、Y传入网络后,从W(独热编码,是一种一一对应的表查询,不是预训练)到隐藏层需要经过一个Q矩阵,而这个Q矩阵可以使用Word2Vec预训练好的Q矩阵,并直接得到词向量,然后进行接下来的具体任务
- 在我们使用Word2Vec的Q矩阵也有两种方式
- 冻结:不改变Q矩阵
- 微调:随着任务的改变,在模型的训练过程中,改变Q矩阵
- 以后的transformer和BERT都是用在预训练这一块,而其他的网络结构是根据任务的不同进行改变的,也就意味着在相同的任务下,我们可以通过改变预训练来找到创新点。
参考文献
- 06 Word2Vec模型(第一个专门做词向量的模型,CBOW和Skip-gram)
这篇关于Transformer的前世今生 day03(Word2Vec、如何使用在下游任务中)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





