本文主要是介绍在Ubuntu16.04上配置环境并运行Neural Baby Talk库的NOC部分代码的具体步骤,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 前言
笔者最近需要做Novel image Captioning(NOC)的任务,在github上找了找发现了Neural-Baby-Talk这个库。在代码库的README中,只有怎么用dockerfile配置的步骤,由于笔者没有弄懂怎么在课程服务器上使用dockerfile,服务器也没有开放使用dockerfile配置镜像的功能,所以干脆照着dockerfile和README手动配置。
接下来笔者会分享在 Ubuntu16.04+python3.6+torch0.4 上配置Neural-Baby-Talk库的Novel image Captioning任务的具体步骤。 由于课程任务只要求实现NOC,所以笔者并没有配置这个库运行Standard Image Captioning任务或Robust Image Captioning任务的相关环境。 不过按照笔者配置环境时的经验,其余两个任务的配置过程应该与NOC很相似,感兴趣的朋友可以参照我这篇博文进行尝试。
2. 提示
2.1 关于服务器操作
笔者是在vscode上连接了远程服务器来进行服务器操作的,优点是方便进行文件查看和代码修改,感兴趣的朋友可以搜索相关教程,配置过程很简单。
不过在新拉取的实例上,使用远程服务器需要先安装ssh,指令如下
apt-get install openssh-server
如果出现无法连接ssh的情况,可以参考这篇博文(11条消息) SSH登陆报错解决方案:Permission denied, please try again._Python少年班的博客-CSDN博客
2.2 关于文件下载
该代码库需要下载很多大文件到服务器才能运行,笔者列出三种使用过的方式,大家可以自行选择下载速度较快的一种:
- 服务器上直接使用
wget(如果该方法下载速度可观,那就不需要考虑其他下载方式) - 本地下载/本地迅雷下载(COCO数据集等大文件使用迅雷下载会很快),然后
scp指令上传到服务器上(比较慢) - 服务器上使用
mwget(需要自行安装,下载某些文件时综合时间比2还要快)
3. 配置步骤
3.1 基于Dockerfile文件配置环境
如果能够直接使用Dockerfile文件配置环境,请跳过该步骤。
环境的配置主要基于代码库中的Dockerfile文件,所以需要先查看一下里面的内容。
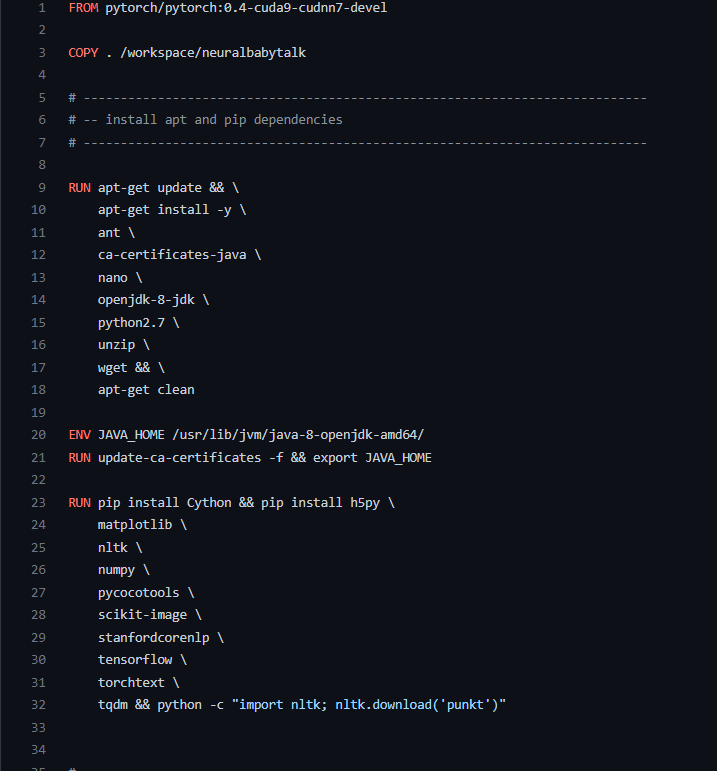
以上为Dockerfile文件的前34行,第一行的From命令是拉取dockerhub里的镜像,第二行的Copy命令是复制相关文件到指定目录,后面的Run命令是创建实例后需要输入的bash指令,ENV命令是需要配置的环境变量。Dockerfile文件后面还有其他内容,留在后面再讲解。
3.1.1 拉取实例
根据Dockerfile文件第一行,在dockerhub中拉取相关镜像。docker指令如下(这是笔者的课程服务器可选的功能,如果无法拉取实例的读者只能考虑自行解决):
docker pull docker.io/pytorch/pytorch:0.4-cuda9-cudnn7-devel
3.1.2 运行配置代码
第9-18行
打开实例后,在bash命令行照着Dockerfile的第9-18行运行指令。直接复制粘贴运行即可。
需要注意的是,虽然原作者是在python2.7上运行的代码,但是笔者是在python3.6上复现的代码,因为如果在python2.7上复现,由于python2和python3的差异,在后续安装相关库时比较麻烦,所以笔者没有使用python2.7复现。也就是说其实不需要再下载python2.7,直接使用实例自带的python3.6即可:)
第20行
首先安装vim编辑器,因为之后需要修改系统文件,命令如下
apt-get install vim
打开 /etc/profile
vim /etc/profile
在文件末尾添加一行代码
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
保存并退出后,在命令行source一下
source /etc/profile
第21行
复制粘贴运行即可
第23-32行
在使用pip指令前,先为pip指令配置清华源,命令如下
#先更新pip版本
pip install pip -U
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
如果无法更新版本,且报错如下

可以先用临时源更新pip
pip install pip -U -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
然后再设置清华源或其他源
第23-29行的代码可以直接复制粘贴运行
需要注意的是 tensorflow和torchtext需要下载指定版本,否则不兼容当前torch版本,命令如下:
pip install tensorflow-gpu==1.12
pip install torchtext==0.2.3
剩余代码直接复制粘贴运行。
Dockerfile内的其余代码基本都是下载一些训练或测试时需要使用的文件,在之后我会配合./data/README文件讲解,先不作考虑。
3.2 代码库下载
在完成上述步骤后,先将Neural-baby-talk的相关代码下载并上传到服务器上。
值得注意的是,下载后得到的文件路径中的NeuralBabyTalk/tools/coco-caption文件夹是空的,因为该文件夹是原作者fork的coco-caption,需要另行下载。将代码库上传到服务器后,解压Neural-baby-talk.zip。然后,先删除里面的./tools/coco-caption文件夹,然后再将coco-caption解压到./tools路径下,并将解压后得到的文件夹重命名为coco-caption。
3.3 下载NOC所需文件
注意:关于下载方式,看一下#2.2 关于文件下载
该步骤主要基于./data/README文件和Dockerfile文件,如果是做Standard Image Captioning任务或Robust Image Captioning任务的也可以参考该步骤并作出适当调整。
README文件或Dockerfile文件里已有的下载链接笔者不会重复贴出,请读者自行点击文件里已有的链接。如果有无法下载的可以联系笔者,笔者会考虑在后续贴上可用的下载链接。
首先查看./data/README文件。
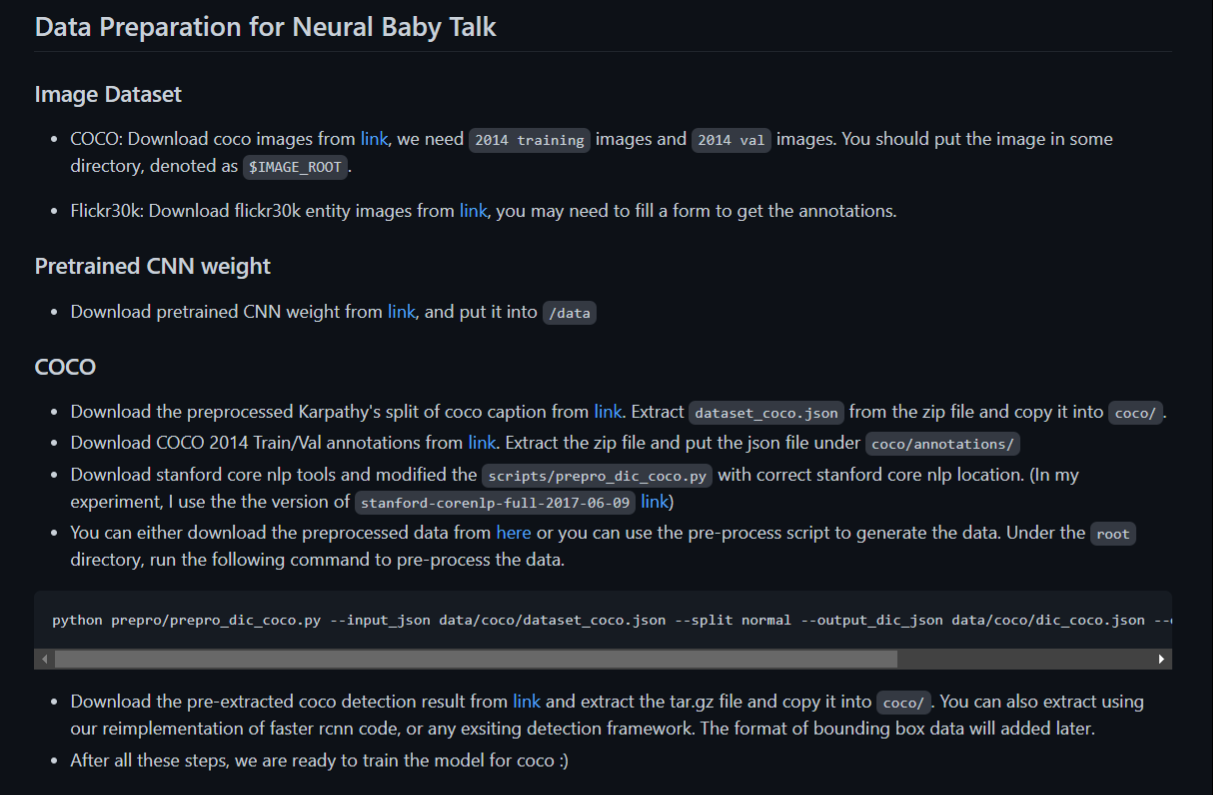
3.3.1 关于COCO数据集
先到官网下载COCO数据集,注意下载 train2014 和 val2014,不需要test2014。解压时,不需要解压到指定文件夹,自己选个合适的地方就行,注意要将解压后得到的train2014文件夹和val2014文件夹放到同一文件夹下。
3.3.2 预训练权重
这个文件的解压路径在Dockerfile里有说明,需要自己创建文件夹./data/imagenet_weights/,并解压到该路径下。
3.3.3 NOC-COCO的要求
查看./data/README文件,可以发现需要先完成COCO里的三个步骤
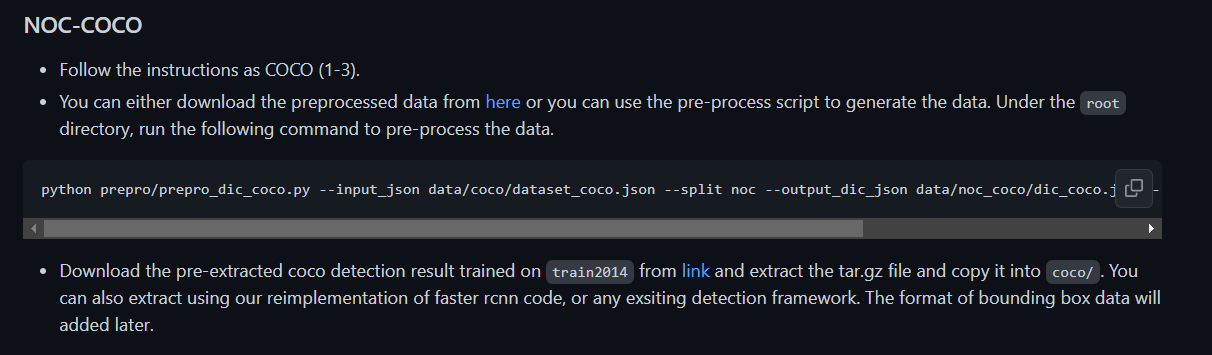
3.3.3.1 COCO
Karapathy’s split
- 下载caption_datasets.zip文件,并将解压后得到的dataset_coco.json复制到 ./data/coco中
annotations
- 下载annotations_trainval2014.zip,将它放到./data/coco/ 并进行解压
standford core nlp tools
-
该文件的解压路径在Dockerfile文件里有说明,需要下载stanford-corenlp-full-2017-06-09 文件到./prepro并解压。
-
按照Dockerfile里的指令,需要运行以下命令
cd /workspace/neuralbabytalk/tools/coco-caption && \ sh get_stanford_models.sh如果运行命令时,里面的
wget指令下载速度过慢,可以考虑复制sh文件里的下载链接到本机下载后再上传,并注释掉sh文件里的相关代码
3.3.3.2 NOC-COCO
完成COCO的三个步骤后,可以做NOC-COCO步骤了
预处理数据
在Neural-baby-talk路径,用./data/README里提供的命令来预处理数据
python prepro/prepro_dic_coco.py --input_json data/coco/dataset_coco.json --split noc --output_dic_json data/noc_coco/dic_coco.json --output_cap_json data/noc_coco/cap_coco.json
下载coco_detection.h5.tar.gz
下载coco_detection.h5.tar.gz文件,并解压到./data/coco
3.3.4 预训练模型
在README文件(不是./data/README)里可以下载NOC的预训练模型来检测test过程的代码是否可以运行。
文件的解压路径在Dockerfile里有说明,下载后将文件解压到./save里
值得一提的是,这个预训练模型在测试集上的的效果很差。
3.3.5 下载NOC split文件
该步骤没有写在./data/README文件和Dockerfile文件里!!!
需要先下载 Lisa Anne 等人提供的 NOC 数据集的划分annotation_DCC.zip文件,官方下载地址如下DCC - Google 云端硬盘,如果有下载慢的,可以考虑在我提供的百度网盘下载。
下载好文件后,在./data/中创建文件夹 coco_noc,并将annotation_DCC.zip解压到该文件夹下,将解压后得到的文件夹重命名为 annotations
3.4 代码调整
需要注意的是,由于源代码是在python2.7运行而笔者是在python3.6上运行,因此需要修改少量代码
3.4.1 main.py文件里的代码
284行
将
infos = pickle.load(f)
改为
infos = pickle.load(f,encoding='iso-8859-1')
293行
将
with open(os.path.join(opt.start_from, 'histories_'+opt.id+'.pkl')) as f:
改为
with open(os.path.join(opt.start_from, 'histories_'+opt.id+'.pkl'),'rb') as f:
294行
将
histories = pickle.load(f)
改为
histories = pickle.load(f,encoding='iso-8859-1')
3.4.2 ./tools/coco-caption/pycocoevalcap/cider/cider_scorer.py文件里的代码
197行-200行
取消以下代码的注释(这个改动不是由于python版本问题,后面会讲)
docFreq = {}
docFreq['df'] = self.document_frequency
docFreq['ref_len'] = len(self.crefs)
pickle.dump(docFreq, open('noc_test_freq.p', 'w'))
并将200行的代码改为如下
pickle.dump(docFreq, open('noc_test_freq.p', 'wb'))
205行
将以下代码
docFreq = pickle.load(open(os.path.join('tools/coco-caption/data', \ df_mode + '.p'), 'r'))
改为
docFreq = pickle.load(open(os.path.join('/root/NeuralBabyTalk-master', \ df_mode + '.p'), 'rb'),encoding='iso-8859-1')
3.5 测试评估
接下来先进行测试评估,来检验代码是否可运行,以下为README文件里NOC任务用于训练和测试的样例代码。
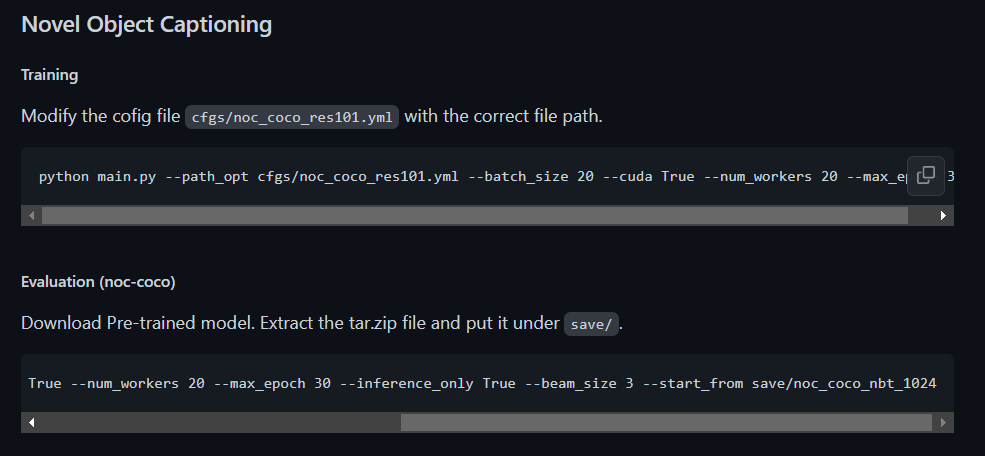
修改./cfgs/noc_coco_res101.yml的内容
首先更改 ./cfgs/noc_coco_res101.yml 的内容,将以下路径修改为你的实际路径
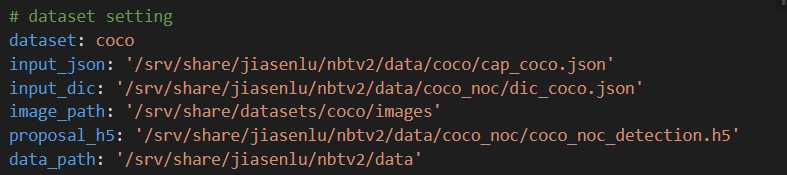
input-json和input_dic是 #3.3.3.2 预处理数据 步骤所得到的文件,存放在./data/noc_coco/里面
image_path是COCO数据集中的train2014和val2014的解压路径
proposal_h5是之前下载得到的h5文件的解压路径
data_path是代码库中的./data文件夹的路径
例如笔者的实际路径如下
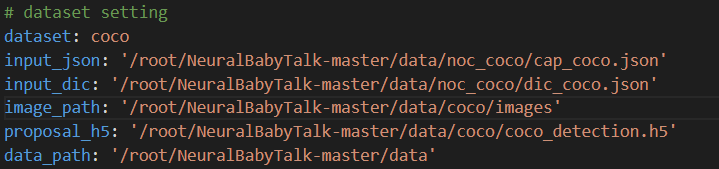
其次(划重点!!!),更改./tools/sentence_gen_tools/coco_eval.py内代码
在第一次运行代码时,需要先将第52行的df的值从“noc_test_freq”修改为 “corpus”。这是为了得到Cider的评分,如果读者不需要这个评分,可以直接将该行注释掉,并跳过该步骤。
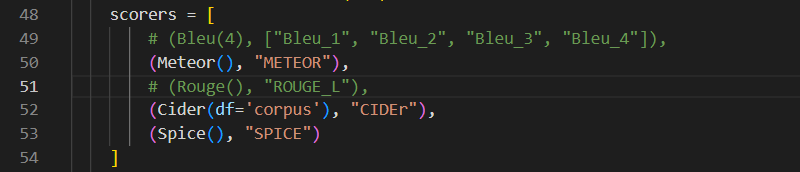
在./tools/pycider/README(如下)里有说明,当该值设置为 “corpus” 以外的值时,需要先提供存储文档频率的文件。而笔者在之前的步骤中取消了一部分代码的注释,就是为了在将该值设置为corpus时,能够自动生成一个存储文档频率的文件,该文件可用于 “noc_test_freq”。通过这一次运行,可以生成这个存储文档频率的文件,在之后的代码运行中,就可以将 df的值重新设置为 “noc_test_freq”。

值得注意的是,笔者将第49行和51行注释掉了,因为在笔者做课程任务时并不需要Bleu和Rouge这两种评价指标,所以也没有测试相关代码能否实际运行。
然后运行测试评估代码
python main.py --path_opt cfgs/noc_coco_res101.yml --batch_size 20 --cuda True --num_workers 20 --max_epoch 30 --inference_only True --beam_size 3 --start_from save/noc_coco_nbt_1024
第一次运行时,会下载一个 glove.6B.zip 文件到 ./.vector_cache中,如果在之后运行代码的过程中,出现类似zipfile.BadZipFile: File is not a zip file的报错,可能是该文件损坏,将该文件删除,重新下载即可。(实际上笔者在训练的过程中多次遇到这个报错,可能是因为服务器断连等原因造成了该文件的频繁损坏,可以考虑在第一次下载后就将该文件备份,毕竟下载速度确实有点慢)
成功把结果跑出来了(如下图),可以看到四个指标的得分都很低。

注意在代码可以成功运行后,将上面的提到的df的值改回“noc_test_freq”
3.6 训练
尝试训练,运行代码
python main.py --path_opt cfgs/noc_coco_res101.yml --batch_size 20 --cuda True --num_workers 20 --max_epoch 30
在经过第18个epoch后,模型的评估效果如下,效果还不错

更改模型的部分超参数和结构,可以通过修改以上训练代码以及./cfgs/noc_coco_res101.yml内的相关内容来实现
这篇关于在Ubuntu16.04上配置环境并运行Neural Baby Talk库的NOC部分代码的具体步骤的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







