本文主要是介绍【PINet车道线检测】代码复现过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
《Key Points Estimation and Point Instance Segmentation Approach for Lane Detection》
论文:https://arxiv.org/abs/2002.06604
代码:GitHub - koyeongmin/PINet
论文解读:http://t.csdnimg.cn/AOV91
这是篇关于自动驾驶中车道检测技术的研究论文,标题为“Key Points Estimation and Point Instance Segmentation Approach for Lane Detection”,作者包括Yeongmin Ko、Younkwan Lee、Shoaib Azam、Farzeen Munir、Moongu Jeon和Witold Pedrycz。论文提出了一种名为Point Instance Network (PINet)的车道检测方法,该方法基于关键点估计和实例分割方法。

摘要:
基于关键点检测和实例分割技术提出一个Point Instance Network(PINet)来检测车道线。网络中包含几个同时训练的stacked hourglass networks,可裁切后不用再训练直接使用来减小模型运算量。自动驾驶的感知技术需要适应各种环境,车道检测是自动驾驶中的一个重要感知模块,需要考虑交通线的数量和目标系统的计算能力,PINet通过堆叠的沙漏网络(hourglass networks)进行训练,可以根据目标环境的计算能力选择模型大小,PINet将预测关键点的聚类问题视为实例分割问题,可以处理不同数量的交通线,网络可适应不同数量的车道线,在公共车道检测数据集TuSimple和Culane上,PINet实现了竞争性的准确性和低误报率。
复现过程
下载代码
首先详细阅读改论文的Github源码,在Code中下载代码压缩包。
将代码使用Pycharm打开,
下载数据集
使用TuSimple数据集:https://pan.baidu.com/s/19xbtMDtznqHOjS9kp30Acw?pwd=a5DA
提取码:a5DA
注意:下载的TuSimple数据集中仅使用了test_set和train_set,并且在test_set中缺少test_label.json文件需要从官方网站https://www.kaggle.com/datasets/manideep1108/tusimple?resource=download中下载,
下载之后将其解压进test_set文件夹中。
在代码的根目录下新建文件夹命名为:TuSimple
目录结构如下:
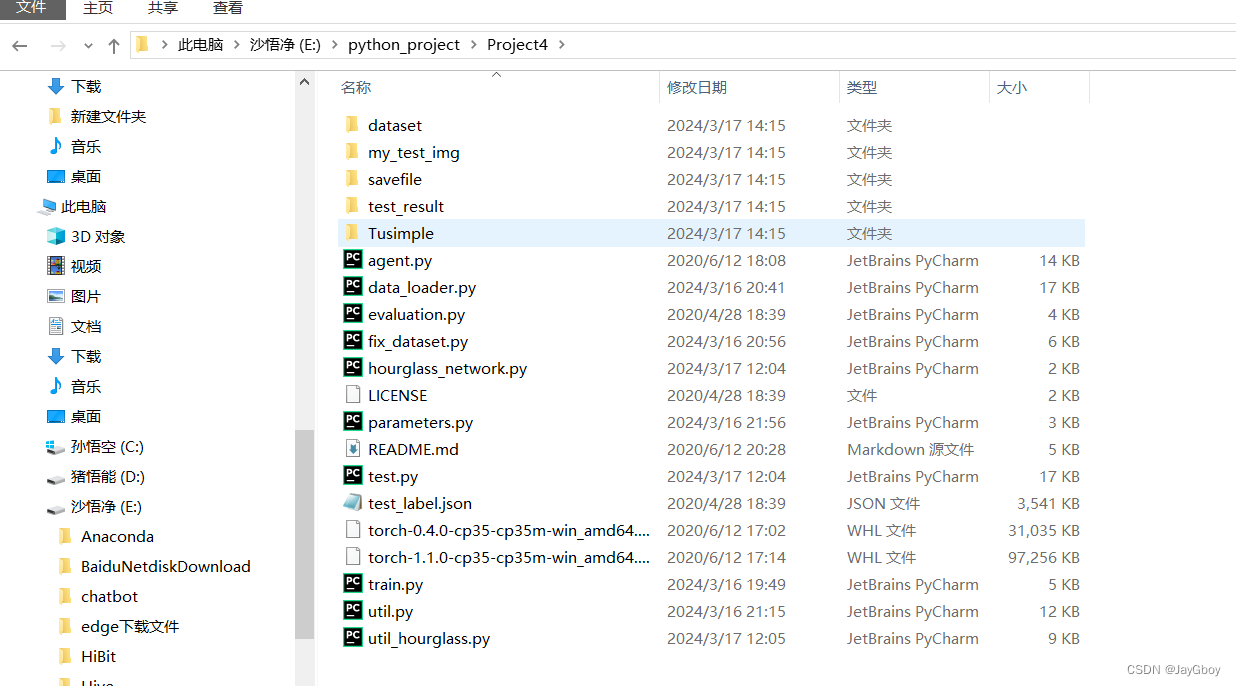
TuSimple文件目录要按照以下结构:
Tusimple||----train_set/ |------||------|----clips/ |------|------||------|------|----some_clip/|------|------|----...||------|----label_data_0313.json |------|----label_data_0531.json |------|----label_data_0601.json ||----test_set/ |------||------|----clips/|------|------||------|------|----some_clip/|------|------|----...||------|----test_label.json |------|----test_tasks_0627.json Test测试
在一切准备就绪时,我们先进行测试代码,作者已提供经过训练的模型640_tensor(0.2298)_lane_detection_network.pkl,它保存在“savefile”目录中。可以运行“test.py”进行测试。
在进行测试之前,我们需要根据自己想要测试的文件类型来选择测试模式:
模式0:在测试集上可视化结果
模式1:在给定的视频上运行模型。如果要使用此模式,在“test.py”的第 63 行输入视频路径
模式2:在给定图像上运行模型。如果要使用此模式,在“test.py”的第 82 行输入图像路径
模式3:在整个测试集上测试模型,并将结果保存为json文件。
在“parameters.py”文件中的第 22 行mode更改模式。
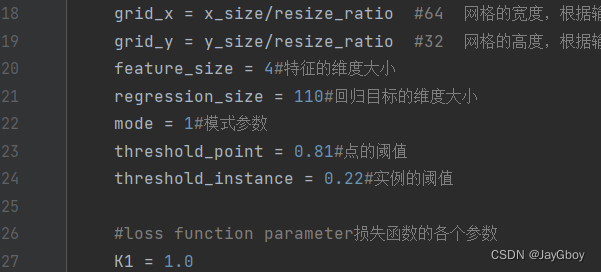
代码如下:
if p.mode == 0 : # 使用测试数据集对模型进行测试for _, _, _, test_image in loader.Generate():_, _, ti = test(lane_agent, np.array([test_image]))cv2.imshow("test", ti[0])cv2.waitKey(0) elif p.mode == 1: # 使用视频文件对模型进行测试cap = cv2.VideoCapture("C:\\Users\\25055\Desktop\\1.mp4")#通过cv2.VideoCapture打开视频文件while(cap.isOpened()):ret, frame = cap.read()prevTime = time.time()frame = cv2.resize(frame, (512,256))/255.0frame = np.rollaxis(frame, axis=2, start=0)_, _, ti = test(lane_agent, np.array([frame])) ##循环读取每一帧图像,将图像进行预处理后传递给test函数进行测试,并显示测试结果。curTime = time.time()sec = curTime - prevTimefps = 1/(sec)s = "FPS : "+ str(fps)##同时,计算帧率并在图像上显示。cv2.putText(ti[0], s, (0, 100), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0))cv2.imshow('frame',ti[0])if cv2.waitKey(1) & 0xFF == ord('q'):breakcap.release()cv2.destroyAllWindows()elif p.mode == 2: # 使用单张图片对模型进行测试test_image = cv2.imread(p.test_root_url+"clips/0530/1492626047222176976_0/23.jpg")test_image = cv2.resize(test_image, (512,256))/255.0test_image = np.rollaxis(test_image, axis=2, start=0)_, _, ti = test(lane_agent, np.array([test_image]))cv2.imshow("test", ti[0])cv2.waitKey(0) elif p.mode == 3: #进行评估操作print("evaluate")evaluation(loader, lane_agent)#evaluation函数对数据集进行评估如果要使用其他经过训练的模型,只需更改以下 2 行:
# In "parameters.py"
line 13 : model_path = "<你自己训练好的网络模型>/"
# In "test.py"
line 42 : lane_agent.load_weights(<>, "tensor(<>)")由于数据集过大,本次测试先使用作者已经提供好的网络模型。在选择好测试模式和视频路径后,开始进行测试:
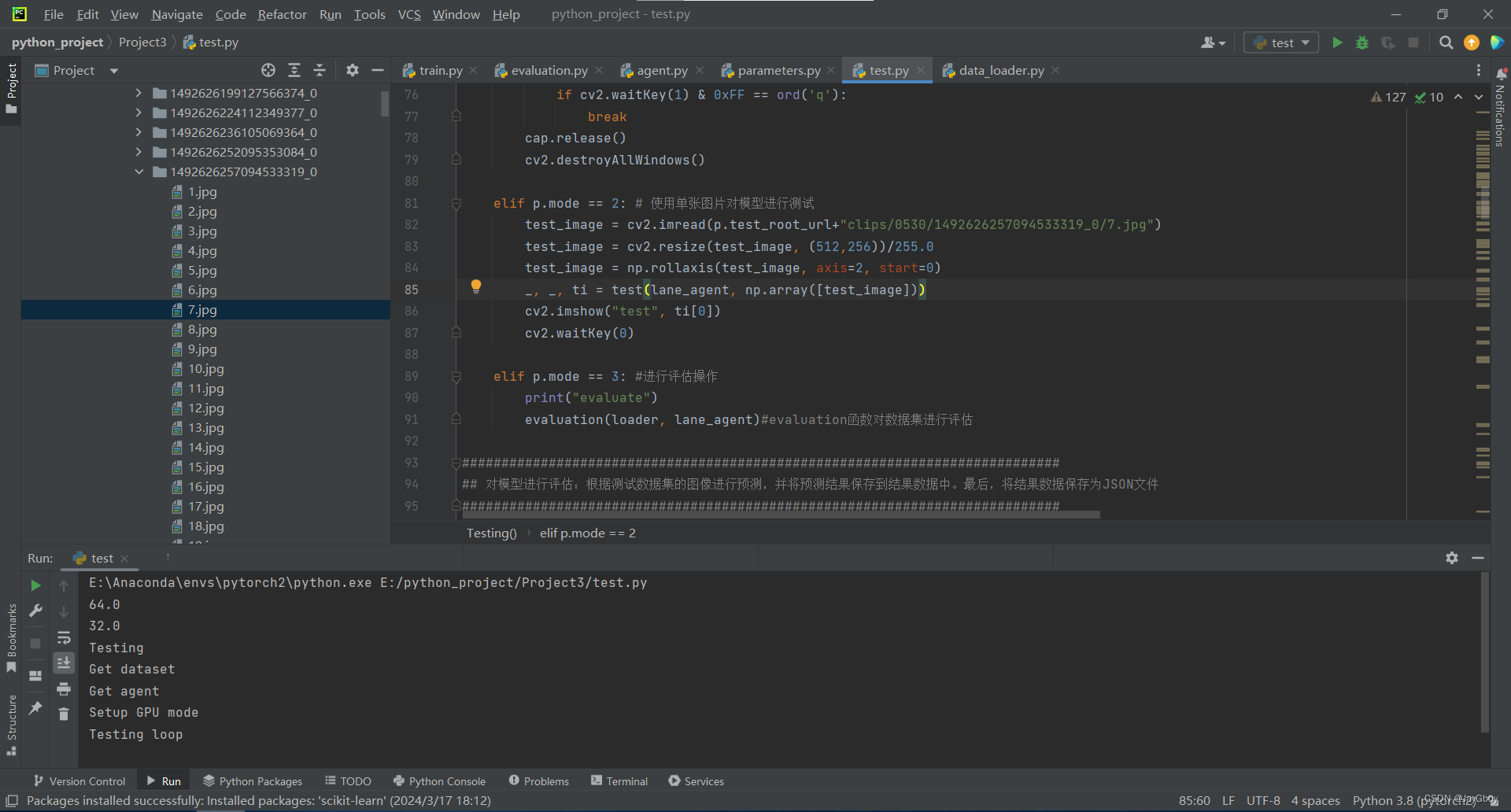
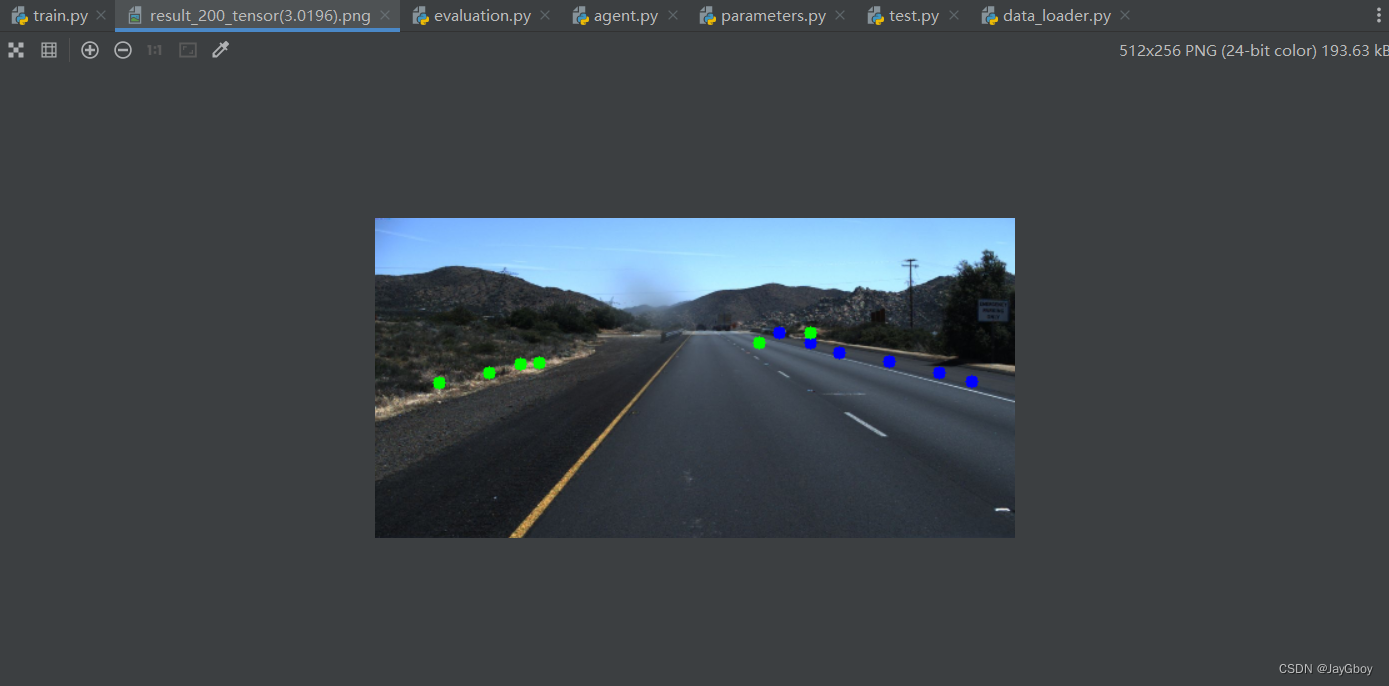
测试结果:
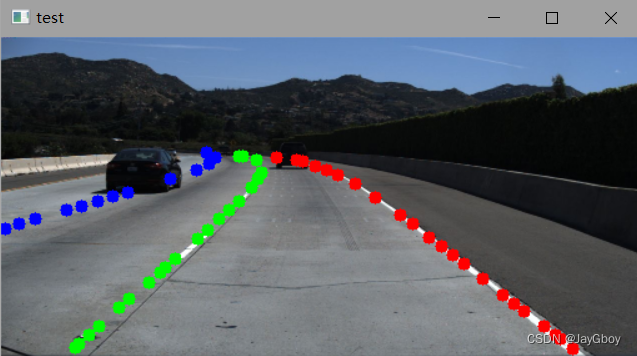
作者训练好的网络模型效果还是比较好的。
由于视频测试效果在本平台展示不出,故不做展示。
训练自己的网络模型
如果要从头开始训练,在“parameters.py”中将第 13 行设为空白,然后运行“train.py”即可;
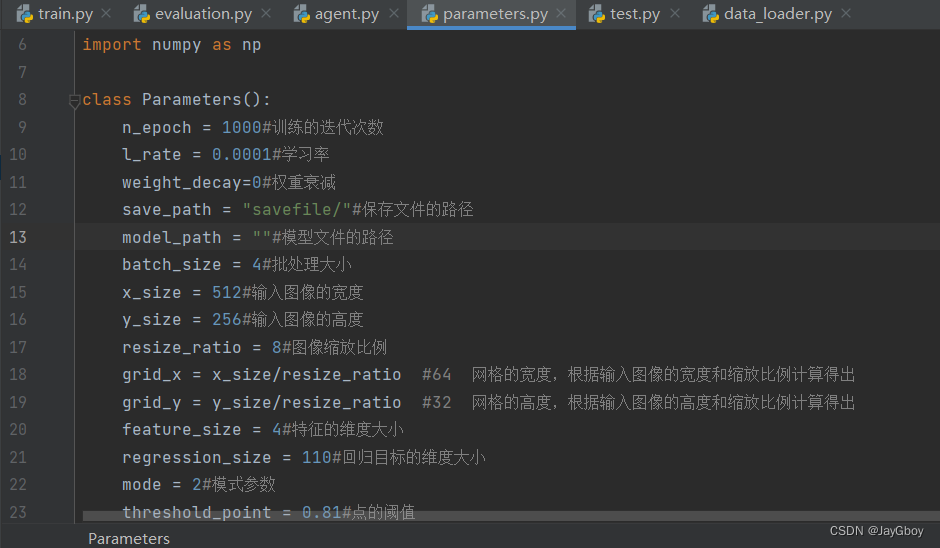
“train.py”将保存样本结果图像(在“test_result/”中)、训练模型(在“savefile/”中)和某些阈值(0.3、0.5、0.7)的评估结果。
首先展示一下训练模型的过程:
在运行代码之前,需要在终端运行
python -m visdom.server目的是进入 python 终端,激活服务器,下载相关脚本文件。
当出现:
即代表激活成功,此时点击网络端口进入网页,查看在训练网络模型时损失函数的曲线。
运行train.py
此时,运行窗口不断输出信息。
在 http://localhost:8097端口事实展示训练时损失值曲线:
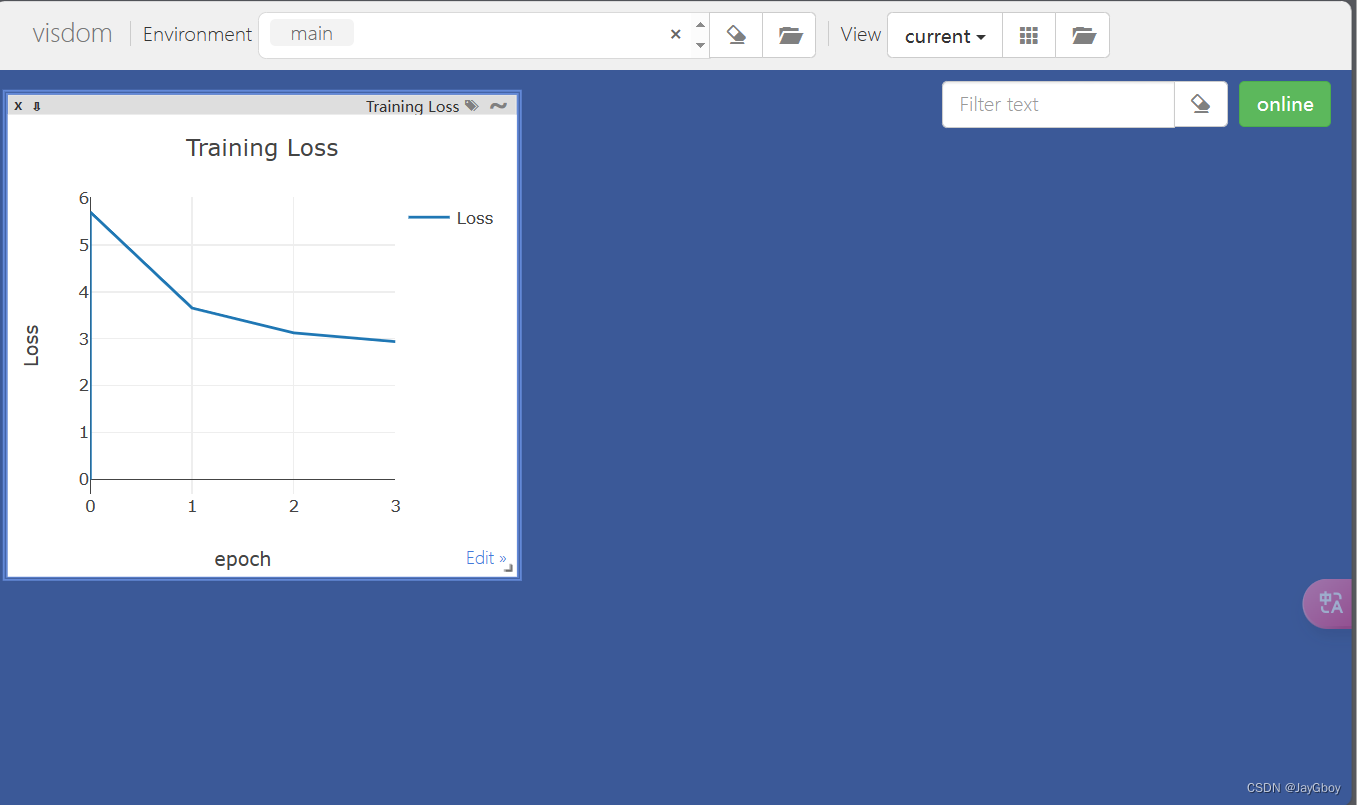
与此同时,在目录端savefile会自动保存好训练好的模型(每100step保存一次),test_result文件中会自动保存训练时用来测试的图片结果。
(前几轮的效果并不明显)
由于数据集过大,训练过程复杂,需要的时间过长,所以不建议完全跑完整个数据集,使用作者已提供的训练好的模型即可。
代码详解
- 导入所需的库:
import cv2 import torch import visdom import agent import numpy as np from data_loader import Generator from parameters import Parameters import test import evaluation - 创建一个名为
Parameters的对象实例p,该对象包含一些模型训练的超参数:p = Parameters() - 定义一个名为
Training的函数,用于执行训练过程:def Training(): - 创建一个
visdom对象用于可视化训练过程中的损失值,并设置一个窗口用于显示损失曲线:vis = visdom.Visdom()loss_window = vis.line(X=torch.zeros((1,)).cpu(),Y=torch.zeros((1)).cpu(),opts=dict(xlabel='epoch',ylabel='Loss',title='Training Loss',legend=['Loss'])) - 创建一个
Generator对象实例loader,用于生成训练数据:loader = Generator() - 根据模型路径是否为空,创建一个代理模型实例
lane_agent,并加载权重(如果有):if p.model_path == "":lane_agent = agent.Agent()else:lane_agent = agent.Agent()lane_agent.load_weights(4235, "tensor(0.2127)") - 打印设置GPU模式的提示信息(如果可用):
print('Setup GPU mode')if torch.cuda.is_available():lane_agent.cuda() - 初始化步数
step为0,并开始迭代训练过程的每个周期epoch:step = 0for epoch in range(p.n_epoch): - 设置代理模型为训练模式:
lane_agent.training_mode() - 使用数据生成器
loader.Generate()获取输入、目标车道、目标高度和测试图像,并进行训练:for inputs, target_lanes, target_h, test_image in loader.Generate():# trainingprint("epoch : " + str(epoch))print("step : " + str(step))loss_p = lane_agent.train(inputs, target_lanes, target_h, epoch, lane_agent)loss_p = loss_p.cpu().data - 如果步数
step是50的倍数,将损失值添加到可视化窗口中:if step%50 == 0:vis.line(X=torch.ones((1, 1)).cpu() * int(step/50),Y=torch.Tensor([loss_p]).unsqueeze(0).cpu(),win=loss_window,update='append') - 如果步数
step是100的倍数,保存模型,并进行测试:if step%100 == 0:lane_agent.save_model(int(step/100), loss_p)testing(lane_agent, test_image, step, loss_p) - 如果当前步数大于700,000,则跳出训练循环:
if int(step)>700000:break - 定义一个名为
testing的函数,用于执行测试过程:def testing(lane_agent, test_image, step, loss): - 将代理模型设置为评估模式:
lane_agent.evaluate_mode() - 使用测试图像进行测试,并保存测试结果图像:
_, _, ti = test.test(lane_agent, np.array([test_image]))cv2.imwrite('test_result/result_'+str(step)+'_'+str(loss)+'.png', ti[0]) - 将代理模型设置回训练模式:
lane_agent.training_mode()train.py代码主要是一个训练循环,其中包含了模型的初始化、数据加载、训练和测试等步骤。训练过程中使用了可视化工具
visdom来实时显示训练损失,并保存模型和测试结果图像。同时,还包含了评估模型性能的步骤。具体的模型结构、数据生成器和评估函数等实现细节在其他py文件中。
遇到的问题
在遇到报错时一定要保证该代码所需的包和模块已下载。
一、在进行Test测试时,出现以下错误:

出现以下错误的原因有以下几种:
1.opencv和opencv-contrib-python 两者的版本不匹配
2.opencv和opencv-contrib-python 的版本过高或者过低
3.python的版本过高,一般使用python3.8版本,本人一开始使用的3.10版本会一直出现报错
4.图片的路径不正确,也是一种常见的错误
二、在进行Train训练时,出现以下错误:
1.当出现ConnectionRefusedError: [WinError 10061] 由于目标计算机积极拒绝,无法连接的错误时,可能是因为环境并没有安装visdom模块,所以导致计算机拒绝连接。

在python终端输入:
pip install visdom安装之后会显示:
Successfully built visdom torchfile
Installing collected packages: jsonpointer, websocket-client, torchfile, jsonpatch, visdom
Successfully installed jsonpatch-1.32 jsonpointer-2.1 torchfile-0.1.0 visdom-0.1.8.9 websocket-client-0.58.0
每次运行时都要进行激活操作:
python -m visdom.server
2.出现类型输入错误
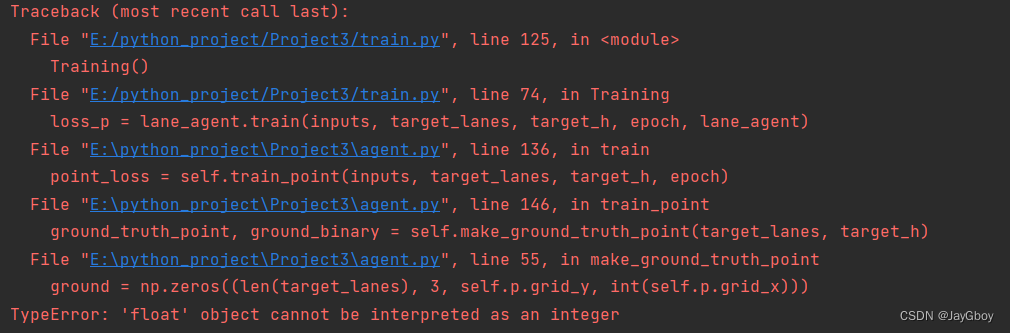
通过解读错误这个错误TypeError: 'float' object cannot be interpreted as an integer,
发现是类型错误。
具体纠正如下:
test.py:192行——两个p.grid_y加上int,强制转换,int(p.grid_y)。agent.py:245、246、247行:缩进有问题,调整跟244行一样即可。parameters.py:58、59、60行:grid_y、grid_x前加int。agent.py在所有出现self.p.grid_y和self.p.grid_x的地方全都加上int
具体是什么原因导致的还不清楚。
这篇关于【PINet车道线检测】代码复现过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







