本文主要是介绍系统设计面试题 之 如何设计Pastebin.com,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文链接:https://github.com/donnemartin/system-design-primer/blob/master/solutions/system_design/pastebin/README.md
第一步:搜集用例和约束
在面试过程中,我们需要向面试官询问需求以设计用例,但是在本文中我们自己设计用例因为没有面试官。
1.用例
本文只解决以下用例:
1)用户输入一个文本块,获得一个随机生成的链接;
过期:
a.默认设置是不过期(译者注:但这样数据库会越来越大,所以我觉得应该有一个默认的过期时间)
b.能够可选的设置一个过期时间
2)用户输入一个粘贴板url,就能查看对应的内容
3)用户可以是匿名的
4)我们需要有一个服务来跟踪页面的使用状况
5)我们需要有一个服务来删除过期的粘贴板
6)我们的服务要有高可靠性
本文不解决以下用例:
1)用户注册一个账号以及邮箱确认
2)用户登入一个注册账号以及修改粘贴板
3)用户能设置可见性
4)用户能设置短链接
2.约束和假设
状态假设:
1)流量是不均匀分布的
2)Following a short link should be fast(译者注:没看明白啥意思)
3)只能粘帖纯文本
4)页面使用状况的分析不需要实时
5)1000万用户
6)每个月有1000万用户写操作
7)每个月有1亿用户读操作
8)读写比率是10:1
计算使用率
如果你被要求估计使用率的话,请和面试官先讨论。
1)每个剪贴板的size
a.每个剪贴板1kb的size
b.shortlink - 7字节
c.一分钟为单位的过期时间 - 4字节
d.创建时间 - 5字节
e.粘贴板路径 - 255字节
f.总计 =~ 1.27kb
2)每个月新增12.7GB的粘贴板内容
a.每个粘贴板1.27kb的size乘以每个月1000万用户
b.3年内需要大约450GB空间
c.3年内3600万短链接
d.假设大部分粘贴板都是新建的,而不是对旧粘贴板的修改
3)平均每秒4个写操作
4)平均每秒40个读操作
一些方便计算的提示:
1)每个月有250万秒
2)每秒1个请求 = 每个月250万个请求
3)每秒40个请求 = 每个月1亿个请求
4)每秒400个请求 = 每个月10亿个请求
第二步:本文的顶层设计如下图

第三步:设计核心组件
1. 用户输入一个文本块,获得一个随机生成的链接
我们可以把关系数据库当作一个巨大的哈希表来使用,这个哈希表可以把生成的url映射到文件服务器以及粘贴板文件的路径上。
相对于使用文件服务器,我们也可以使用例如Amazon S3或者NoSql document之类的面向对象存储。
另外,我们也可以使用NoSql key-value来取代关系数据库作为哈希表的方法。以下讨论基于关系数据的方法:
1)客户发送一个创建粘贴板的请求给web服务器,该web服务器实际上是一个反向代理
2)web服务器把请求转发给Write API服务器;
3)Write API服务器做以下操作:
a.通过查询sql数据库检查url是否唯一
b.如果url不唯一,就会生成另一个url
c.如果我们支持自定义url的话,那么我们可以使用用户提供的url
4)保存数据到sql数据库的pastes表
5)保存粘贴板数据到面向对象存储
6)返回url
pastes表如下:
shortlink char(7) NOT NULL
expiration_length_in_minutes int NOT NULL
created_at datetime NOT NULL
paste_path varchar(255) NOT NULL
PRIMARY KEY(shortlink)我们将会为shortlink和created_at创建索引以加速查询(log-time instead of scanning the entire table)(译者注:没看明白这句话)并且把数据保存在内存中。
为了生成唯一的url,我们可以:
1)使用md5算法对用户ip和时间戳计算hash:
md5是一个使用广泛地128位哈希算法。md5均匀分布。我们可以用md5算法生成随机url。
2)使用base62编码hash
base62对哈希值的编码是确定唯一的。base62使用[a-zA-Z0-9]编码适用于url;base64多了两个字符+和/,所以不适用于url生成。以下是base62伪码:
def base_encode(num, base=62):digits = []while num > 0remainder = modulo(num, base)digits.push(remainder)num = divide(num, base)digits = digits.reverse3)我们只取输出结果的前7个字符,这样就有种可能的值;应该足够处理我们三年中的3.6亿个短链接:
url = base_encode(md5(ip_address+timestamp))[:URL_LENGTH]我们还需要一个公有的REST API:
$ curl -X POST --data '{ "expiration_length_in_minutes": "60", \"paste_contents": "Hello World!" }' https://pastebin.com/api/v1/paste返回结果:
{"shortlink": "foobar"
}2.用户输入一个粘贴板url,就能查看对应的内容
1)用户发送一个获取粘贴板的请求给web服务器;
2)web服务器转发请求给Read API服务器;
3)Read API服务器做以下操作:
检查sql数据库是否存在对应于url的数据。如果url已经存在于数据库中的话,就从面向对象存储中获取粘贴板的内容;否则的话,返回错误。
REST API:
$ curl https://pastebin.com/api/v1/paste?shortlink=foobar响应值:
{"paste_contents": "Hello World""created_at": "YYYY-MM-DD HH:MM:SS""expiration_length_in_minutes": "60"
}3.我们需要有一个服务来跟踪页面的使用状况由于我们不需要实时分析页面使用情况,所以我们可以简单地使用mapreduce来分析页面使用情况。
class HitCounts(MRJob):def extract_url(self, line):"""Extract the generated url from the log line."""...def extract_year_month(self, line):"""Return the year and month portions of the timestamp."""...def mapper(self, _, line):"""Parse each log line, extract and transform relevant lines.Emit key value pairs of the form:(2016-01, url0), 1(2016-01, url0), 1(2016-01, url1), 1"""url = self.extract_url(line)period = self.extract_year_month(line)yield (period, url), 1def reducer(self, key, values):"""Sum values for each key.(2016-01, url0), 2(2016-01, url1), 1"""yield key, sum(values)
4)我们需要有一个服务来删除过期的粘贴板
为了删除过期的粘贴板,我们可以扫描sql数据库:只要过期时间戳比当前时间旧,我们就可以直接删除。
第四步:扩展我们的设计
先找到瓶颈再解决问题。以下是我们的扩展设计图。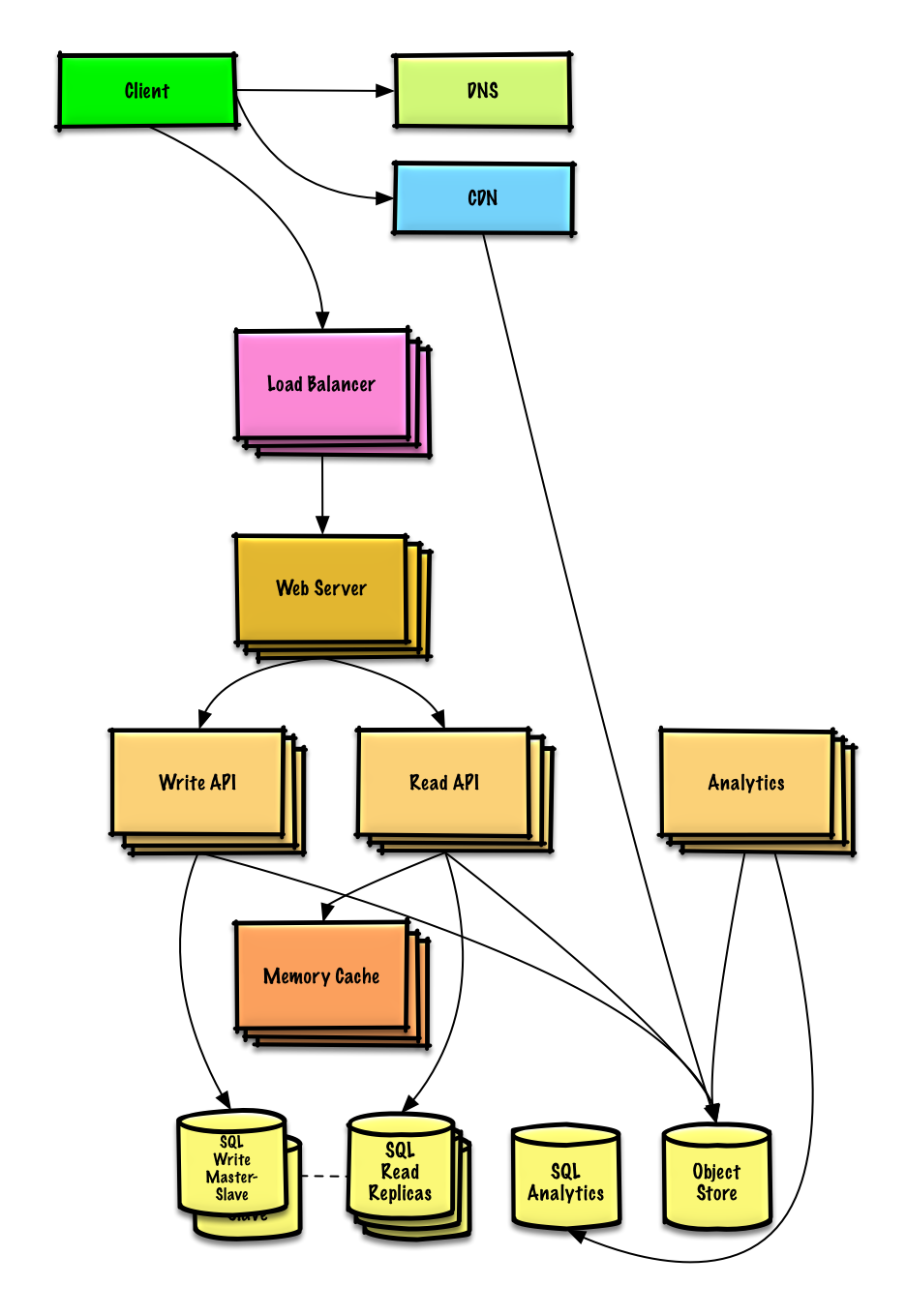
分析数据库可以使用例如Amazon Redshift或者Google BigQuery之类的数据仓库。
Amazon S3之类的面向对象存储可以轻松处理每个月12.7 GB的新增内容。
为了处理每秒40个读请求(峰值可能会略高),流行内容的读请求应该由内存缓存来处理而非数据库。内存缓存在处理不均匀的流量时也很有效。 The SQL Read Replicas should be able to handle the cache misses, as long as the replicas are not bogged down with replicating writes.(译者注:没看明白)
平均每秒的写操作对于 SQL Write Master-Slave是能够应付的。
(译者注:第四部分包含大量的链接以及面试技巧,此处不翻译,有需要的请看原文)
这篇关于系统设计面试题 之 如何设计Pastebin.com的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






