本文主要是介绍自动微分运算TORCH.AUTOGRAD,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Tensor、函数和计算图
反向传播算法中,模型参数根据相对于每个给定参数的损失函数的梯度来调整。
为了计算这些梯度,PyTorch 有一个内置的微分运算引擎叫 torch.autograd。它支持对任何计算图自动计算梯度。
考虑一个最简单的单层神经网络,它有输入值 x、参数 w 和 b、和一些损失函数。它可以在 PyTorch 中这么定义:
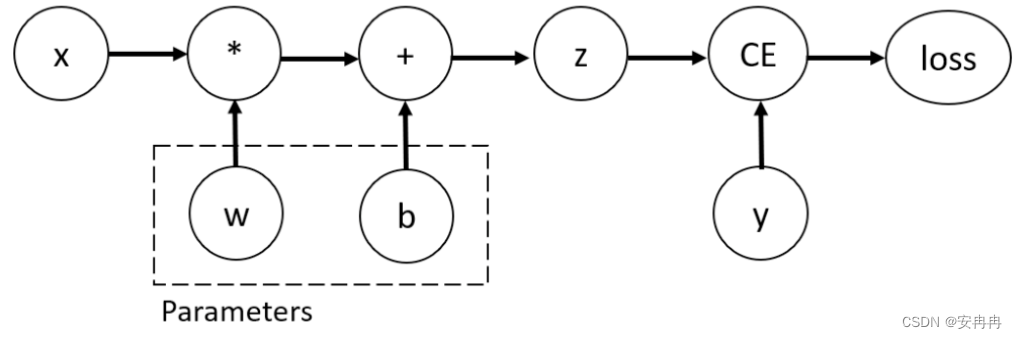
import torchx = torch.ones(5) # input tensor
y = torch.zeros(3) # expected output
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w)+b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)print(f"Gradient function for z = {z.grad_fn}")
print(f"Gradient function for loss = {loss.grad_fn}")
#反向传播函数的一个引用保存在tensor的 grad_fn 的属性中。
为了优化神经网络中的参数,我们需要对参数计算损失函数的导数。要计算这些导数,我们调用loss.backward(),然后从 w.grad 和 b.grad 中获取值。
loss.backward()
print(w.grad)
print(b.grad)
注意:
- 我们只能从计算图中将
require_grad设置为True的叶子结点获取 grad 属性。对于计算图中的其他节点,梯度不可获取。 - 在给定的计算图中,出于性能原因我们只能用
backward进行一次梯度计算。如果我们想要对同一张计算图做几次backward调用,我们需要在backward调用时传递retain_graph=True参数。
禁用梯度追踪
默认情况下,所有设置 requires_grad=True 的tensor会追踪它的计算历史并支持梯度计算。但是也有我们并不需要这么做的场景,比如,当我们已经训练了模型且只想对一些输入数据应用的时候,比如我们只想做沿着网络的前向计算。我们可以通过用 torch.no_grad 包裹我们的计算代码块来停止追踪计算。
z = torch.matmul(x, w)+b
print(z.requires_grad)with torch.no_grad():z = torch.matmul(x, w)+bprint(z.requires_grad)
另一种取得同样效果的方法是在tensor上使用 detach() 方法。
z = torch.matmul(x, w)+b
z_det = z.detach()
print(z_det.requires_grad)
你想要禁用梯度追踪的原因可能是:
- 为了把你神经网络中的某些参数标记为冻结参数(frozen parameters)
- 为了在你只做前向传递的时候加快计算速度,因为在不追踪梯度的tensor上进行的运算会更加高效。
计算图的更多内容
从概念上来说,autograd 在一个由函数(Function)对象构成的有向无环图中保持一份数据(tensor)以及全部执行的操作(以及产生的新tensor)的记录。在这个有向无环图(DAG)中,叶子节点是输入tensor,根节点是输出tensor。通过从根节点到叶子节点地追踪这个图,你可以用链式法则自动计算梯度。
在前向传递中,autograd 同时做两件事:
- 运行指定的操作来计算、生成一个tensor
- 维持这次运算在有向无环图中的梯度函数
当对有向无环图的根节点调用 .backward() 方法时,反向传递就开始了。然后 autograd 会:
- 从每个 .grad_fn 中计算梯度
- 在对应tensor的 .grad 属性中累计它们
- 应用链式法则,一路传播到叶子tensor。
注意: PyTorch 中的有向无环图是动态的: 一个重要的观察是这个图是从零重建的;每次 .backward() 调用之后,autograd 都会开始构建一张新图。这一点允许你在模型中使用流控制语句;如果需要的话,你可以在每次迭代中改变结构、大小和和运算。
这篇关于自动微分运算TORCH.AUTOGRAD的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





