本文主要是介绍基因家族分析(2)鉴定,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基因家族成员鉴定的主要方法为序列相似性比对和功能结构域预测。以苦荞的MAPK基因家族的鉴定为例。
苦荞基因组数据处理
#下载基因组数据
wget http://mbkbase.org/Pinku1/FtChromosomeV2.fasta.gz
wget http://mbkbase.org/Pinku1/FtChromosomeV2.IGDBv2.Coreset.tar.gz
下载并解压后需要使用文件如下:
基因组:FtChromosomeV2.fasta
基因结构:FtChromosomeV2.IGDBv2.Coreset.gff
蛋白质序列:FtChromosomeV2.IGDBv2.Coreset.pros.long.fasta
cds 序列:FtChromosomeV2.IGDBv2.Coreset.cds.long.fasta
苦荞基因组数据中已经提供了最长 cds 文件和蛋白质序列文件,因此我们只需要过滤处理 gff 文件用于后续分析。
# 提取最长转录本基因ID
awk '$1 ~ /^>/ {print $1}' FtChromosomeV2.IGDBv2.Coreset.cds.long.fasta |\
sed 's/^>//' > Ft_mRNA.id
# 基于mRNA id对gff3文件进行过滤
perl gff_filter_bymRNAID.pl \
FtChromosomeV2.IGDBv2.Coreset.gff \ #输入的gff3文件
Ft_mRNA.id\ #需要保留的mRNA id列表
geneID_mrnaID.table \ #输出的gene ID 和 mRNA id 对应文件
Ft_final.gff3 # 过滤后的gff3文件
# 重命名蛋白序列和cds序列文件及基因组名称,方便后续使用
mv FtChromosomeV2.IGDBv2.Coreset.cds.long.fasta Ft.cds.fasta
mv FtChromosomeV2.IGDBv2.Coreset.pros.long.fasta Ft.pep.fasta
mv FtChromosomeV2.fasta Ft.genome.fasta
• 处理后基因组文件
基因组序列:Ft.genome.fasta
gff 文件:Ft_final.gff3
cds 序列文件:Ft.cds.fasta
蛋白序列文件:Ft.pep.fasta
#MAPK hmm 模型准备
MAPK 的 pfam family 编号为 PF03110,登录 Pfam 网站 https://pfam.xfam.org/进行关键字搜索:
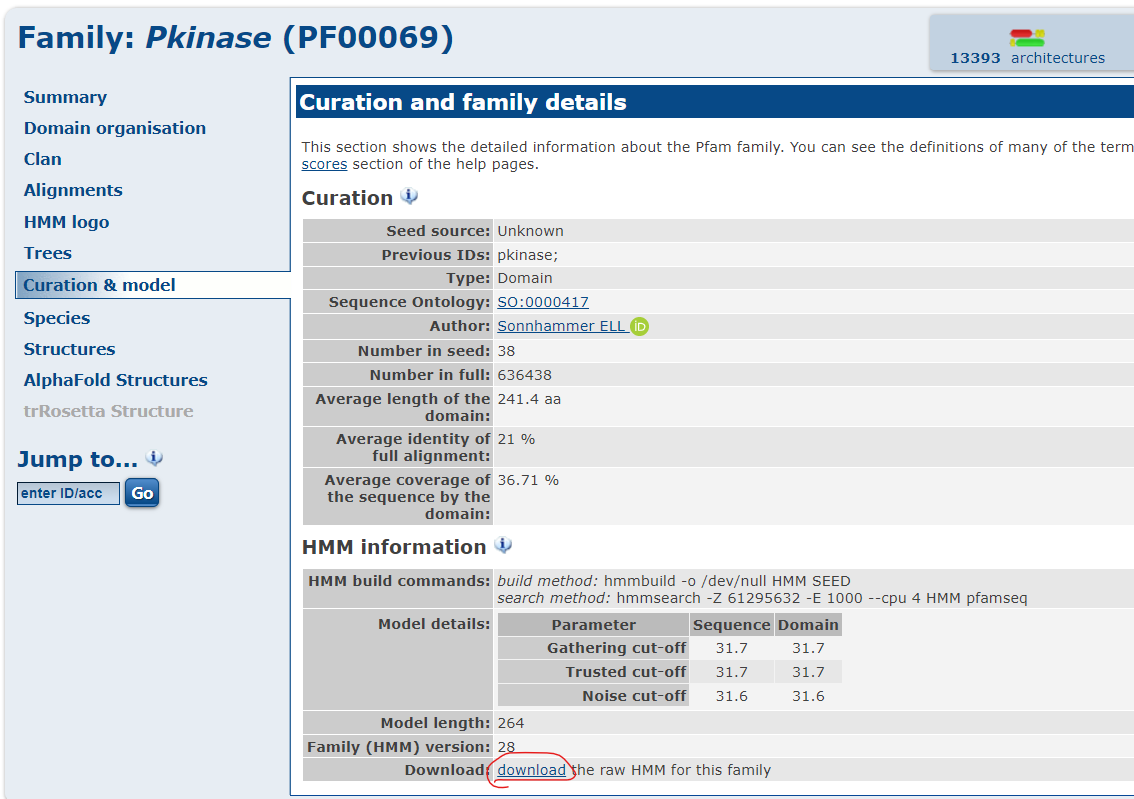
进入 MAPK family 页面后,点击左侧 Curation&model 下载 hmm 模型文件。
拟南芥MAPK蛋白数据的准备
拟南芥 MAPK 基因下载自 TAIR 数据库 https://www.arabidopsis.org/
在 tair 的 genefamily 页面搜索关键字 MAPK,可以找到拟南MAPK 基因家族成员列表信息。得到基因 ID 后,从拟南芥蛋白质数据中提取对应序列。

hmm鉴定苦荞MAPK基因
使用 hmmer 软件中的 hmmsearch 程序,鉴定苦荞蛋白质序列中的 MAPK基因。hmmsearch 软件常用阈值参数如下:
-E :E 值,默认为 10, 表示每个搜索报告大约 10 个错误结果。
–cut_ga : GA (gathering cutoff) pfam 建模时生成,所有已知序列的最低得分
–cut nc :NC (noise cutoff) 已知假阳性结果的最高得分
–cut_tc : TC (trusted cutoff) 高于所有假阳性结果的真阳性结果的最低得分。
阈值顺序为:TC > GA > NC ,因此 TC 是最严格的。
hmmsearch \
--cut_tc \ # 输出结果阈值设置
--domtblout Ft.MAPK.domtblout \ # 结构域预测结果文件
-o Ft.MAPK.hmmout \ # 相似预测结果文件
./Pkinase.hmm \ # hmm模型文件
./Ft.pep.fasta # 蛋白质序列文件#基于E值进一步进行过滤
awk '$7<1e-5 && $1 !~ /^#/ {print $0 }' Ft.MAPK.domtblout > Ft.MAPK.domtblout.filter# 提取预测的MAPK基因ID列表
awk '{print $1}' Ft.MAPK.domtblout.filter | sort -u > Ft.MAPK.domtblout.filter.id
blast比对鉴定苦荞MAPK基因
使用 blastp 软件,将苦荞的蛋白质序列比对到拟南芥 MAPK 基因,确定候选苦荞 SPL 基因。
blast 比对一般考虑如下过滤标准:
-evalue :E 值,在随机情况下,获得比当前得分相等或更高的可能比对条数。
identity :比对区域一致性,一般为 30%
# 构建blast比对数据库
makeblastdb -in MAPK_Ath.fasta -dbtype prot# blastp比对
blastp -query Ft.pep.fasta -db MAPK_Ath.fasta -evalue 1e-5 -outfmt '6 std qlen slen' -out Ft.MAPK.blastout# blast结果基于identity 30% 过滤
awk ' $3 > 50 {print $1} ' Ft.MAPK.blastout | sort -u > Ft.MAPK.blastout.filter.id
合并hmm和blast结果
# hmm 和blast结果取交集
cat Ft.MAPK.domtblout.filter.id Ft.MAPK.blastout.filter.id | sort |uniq -c |awk '$1 == 2{print $2}' > Ft.MAPK.geneID# 提取苦荞SPL基因的cds和蛋白质序列
seqtk subseq Ft.pep.fasta Ft.MAPK.geneID_CD_filter > Ft.MAPK.pep.fasta
seqtk subseq Ft.cds.fasta Ft.MAPK.geneID_CD_filter > Ft.MAPK.cds.fasta# 计算SPL基因的分子量和等电点
Rscript fasta_pI_mw.R Ft.MAPK.pep.fasta Ft.MAPK.pep.fasta.pI_mw# 生成SPL基因汇总统计表格
perl GeneFamily_stat.pl Ft_final.gff3 Ft.MAPK.pep.fasta.pI_mw > Ft.MAPK.stat
查看统计表

关注Bioinfor 生信云微信公众号即可获取对应脚本
这篇关于基因家族分析(2)鉴定的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







