本文主要是介绍这几个神秘参数,教你TDengine集群的正确使用方式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
小 T 导读:为什么我的集群数据分布得不均匀?这篇文章就是为了解决这个问题而写的。但即便是没有遇到“TDengine集群数据不均匀分布”这个现象的用户,我们也推荐一读。因为可能你目前只是在通用场景下使用集群,当一些特殊的场景出现时,深入地了解集群参数和数据库架构原理才会真正地让你做到游刃有余。至于集群如何搭建并不是本文主题,请严格根据官方文档指示操作即可。
官方文档地址:https://www.taosdata.com/cn/documentation/cluster
为了充分理解文章内容,首先大家一定要先了解vnode这个概念——每个 vnode 都是一个相对独立的工作单元,是存储时序数据(表)的基本单元,具有独立的运行线程,内存空间与持久化存储的路径。
如果觉得不够清晰的话,接着往下读,随着知识点的串联,或许您会豁然开朗起来。现在,我们来根据不同的场景给出具体分析:
通常来说,数据分配不均匀有两种。
场景一:表分布不均匀
需要测试表数量很少的数据库性能时比较容易发生这个现象:你建了1200张表,但是却发现有1000张表都在同一个vnode里面,只有200张表在另一个vnode里面。这种场景的坏处是,大部分表都进入了同一个vnode数据分布不均匀。此外还会导致只有两个线程在为TDengine工作,因此无法利用计算机的多核(假设你的服务器CPU是双核以上),从而浪费了TDengine的横向扩展性。
我先来简单说说导致上述情况的原因——在TDengine中有这样三个参数:
- maxVgroupsPerDb: 每个数据库中能够使用的最大vnode个数(单个副本),默认为0;
- minTablesPerVnode: 每个vnode中必须创建的最小表数,即是说这是第一轮建表用的步长(就是满多少表写下一个vnode),默认1000;
- tablelncStepPerVnode:每个vnode中超过最小表数后的递增步长(即是后续满多少表写下一个vnode),默认1000。
在持续的建表过程中,TDengine就是靠这三个参数来控制表的分布的。大家可以在使用taosdemo批量建表的时候观察一下:打开另一个taos窗口,在建表的时候一直输入show vgroups命令,就能看到上述参数所控制的建表过程了:在第一个vnode中,表数量从0开始逐渐递增,随着数量达到minTablesPerVnode后,开始创建下一个vnode并继续在其中建表。之后,重复该过程直到vnode数量达到maxVgroupsPerDb。之后,TDengine将回到第一个vnode继续创建新表,在补充每个vnode的表数达到tablelncStepPerVnode数量后,后续以tablelncStepPerVnode为步长继续在vnode中依次创建表,直到建完全部表。(描述看着繁琐,自己动手跑一遍会很直观)
明白了这个逻辑后,我们可以再来回头看为什么会出现场景一的情况。答案已经很简单了,因为minTablesPerVnode这个参数的值默认是1000,所以前1000个表肯定会只出现在第一个vnode里,这就给用户造成了数据分配并不平均的错觉。
那么要如何调整成我们预期的效果呢。
别急——在此之前我们还需要再多了解一下这个参数:maxVgroupsPerDb。
大家可能在taos.cfg中留意过maxVgroupsPerDb这个参数的值默认是0,根据参数描述,0代表的是自动配置。但是关于这个自动配置的详情在官网上是有解释的:“每个 Database 可以创建固定数目的 vgroup,默认与 CPU 核数相同,可通过 maxVgroupsPerDb 配置”。
如果不了解vgroup概念,建议到官网查看:
https://www.taosdata.com/cn/documentation/architecture

结合文章开头说过的vnode概念——每个vnode都是具有独立的运行线程的,这样就一目了然了——如此设计默认值的原因就是希望vnode数等于cpu核数,从而充分地利用CPU资源,达到最大化服务器性能的目的。
好,现在我们终于可以回到场景一并提出我们的解决方案了。
假设我们是4核服务器,那么默认的最大vgroups就是为4个。进入场景一当中,每个vnode只要存储300个表就好了。这时候只需要调整minTablesPerVnode值为300,这样就可以做到表均匀分布在数据节点中了。
场景一属于相对特殊的情况,而默认配置却只能针对最通用的一个场景。对于大部分用户来说,只要你的测试场景是创建万表级别,都是可以看到表在vnode中按序且平均分配的。比如你有一台4核CPU的机器,计划创建4万个表。那么使用默认配置就会生成4个vnode,最终的结果就是每个vnode存储1万张表,就不会出现数据不均的现象了。
这里我们可以多讨论一下,既然默认配置的maxVgroupsPerDb是可以充分利用CPU的话。那么这个参数还有什么修改价值呢?如果没有修改价值的话它为什么还会是一个对外公开的参数呢?
别急,我们接下来进入下一个场景。
假设你的CPU核数为4,但是我们把maxVgroupsPerDb设成8。其中只有前4个vnode的数据会比较热,后续4个vnode中的数据的使用频率则比较低。看似多开了很多vnode,但是这样的设置和使用默认配置比起来,反而会降低前四个vnode的负担从而增加性能。所以,默认参数虽然通用,但是有时候适当的修改会让数据库变得更好,这就需要使用者结合实际业务场景做评估了。目前,该参数仍是一个全局变量,未来或许会变成数据库级别的变量以方便不同数据库之间业务的差异。
而minTablesPerVnode,tablelncStepPerVnode这两个变量由于使用相对复杂,所以目前并没有出现在taos.cfg当中,属于标题中提到的“神秘参数”。虽然它们设置了适当的默认值(1000)来应对大多数场景,但是当业务场景发生变动出现不适配的时候,就需要我们自己手动修改这些参数了。具体修改方式如下:打开taos.cfg后在空白区域添加如下内容,重启数据库服务进程即可。如果是集群环境,那么需要在每一个节点的taos.cfg中都做一样的配置后重启数据库服务进程。

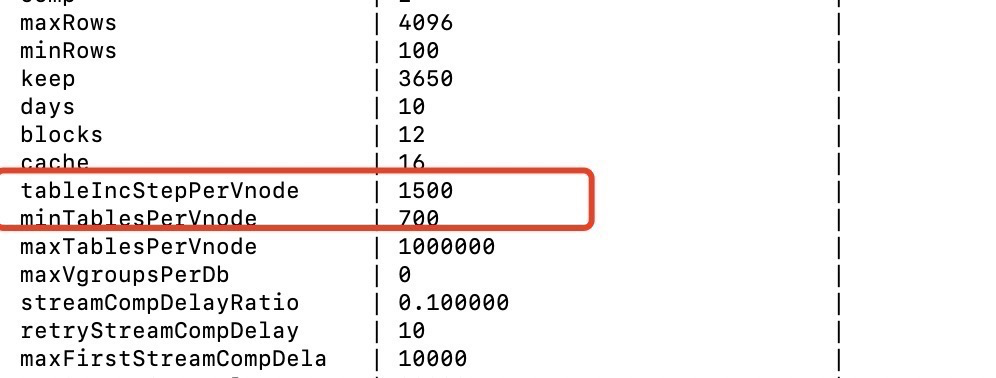
场景二:vnode分布不均匀
这种情况就比较简单了,在批量创建完很多表后,有时候你可能会发现:“咦?为什么这个数据节点上有6个vnode,另外一个节点只有2个vnode。”
在解释这种情况之前,我们需要知道另一个TDengine相当重要的概念——mnode(管理节点)。
关于mnode,官方文档的描述十分清晰:
“管理节点(mnode): 一个虚拟的逻辑单元,负责所有数据节点运行状态的监控和维护,以及节点之间的负载均衡。同时,管理节点也负责元数据(包括用户、数据库、表、静态标签等)的存储和管理,因此也称为 Meta Node。在集群中,为了保证mnode的高可用,可以配置多个mnode副本,副本数由系统配置参数numOfMnodes决定,有效范围为1-3。”
可以看出,mnode和vnode一样,都是以master-slave的模式分布在节点中的。因此,在做数据的负载均衡的时候,mnode也会是被计算在内的,而具体的计算方式就是,一个mnode等价于n个vnode,这个n就是由下面这个参数控制的。

而查看mnode的分配情况的命令如下:

这回我们就知道为什么会出现场景二的情况了——只有2个vnode分布的数据节点上一定是有mnode在工作的。
正是它,顶替了原本应该出现在这的vnode名额。
尾记
写到这里就差不多了,但作为作者很想和大家闲聊几句。
TDengine虽然使用简单方便,但是想要最大化它的价值还是需要一番研究的。而官方文档是作为TDengine的百科全书而存在的,某种程度上,它可能并不适合串联实际应用场景。所以,为了填补这块空白,所以我们在推送的文章中会很注意产品与实际场景的结合以及串联。最终的目标,是让我们的文章能够形成在很多实际使用场景下的闭环说明书。这样,就可以让TDengine用户的使用体验大幅上升。
空口无凭,我们如何做到串联不同实际的应用场景呢。很简单,读完本篇文章可能您已经了解了如何正确的配置集群的数据分布了。结合文章《TDengine 的用户如何优化数据的写入速度?》,想必您又已经对写入数据的性能调试有了一定的认知。再文章《【社区精选】在Docker环境下,TDengine的客户端为什么连不上集群?》,您又对在docker环境下搭建TDengine集群搭建有了一定的了解。
搭建TDengine的知识体系,就和搭建TDengine的集群一样,需要一步一步慢慢积累起来。
开源文化的本质就是互相帮助,社区用户为我们贡献了很多。因此,我们也希望可以用同样的方式回报大家。
这篇关于这几个神秘参数,教你TDengine集群的正确使用方式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


