本文主要是介绍服务器数量从 21 台降至 3 台,TDengine 在跨越速运集团的落地实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者: 叶秋,李海峰,周美华 —— 跨越新科技 vms 车管技术团队
小 T 导读:跨越速运集团有限公司创建于 2007 年。拥有“国家 AAAAA 级物流企业”、“国家级高新技术企业”、“中国物流行业 30 强优秀品牌”、“中国电商物流行业知名品牌”、“广东省诚信物流企业”等荣誉称号。在胡润研究院发布的《2018 Q3 胡润大中华区独角兽指数》《2019 一季度胡润大中华区独角兽指数》榜单中,跨越速运两次上榜,估值约 200 亿元,与菜鸟网络、京东物流、达达-京东到家等企业入选中国物流服务行业独角兽企业。
作为一家物流企业,如何高效地记录和处理车辆的轨迹信息,对于整体的交付效率至关重要。
一. 项目背景
数年前车辆轨迹定位存储引擎项目成立,跨越速运集团购置的数万台车辆经过车载定位设备上报信息到 GPS-AGENT 网关,服务解析报文下发到 Apache Kafka 消息中间件,再通过应用将历史位置定位信息写入 Apache HBase,最新车辆位置信息写入 Redis,以此提供给业务服务进行对车辆的实时监控与分析。
原来的业务架构如下图所示:
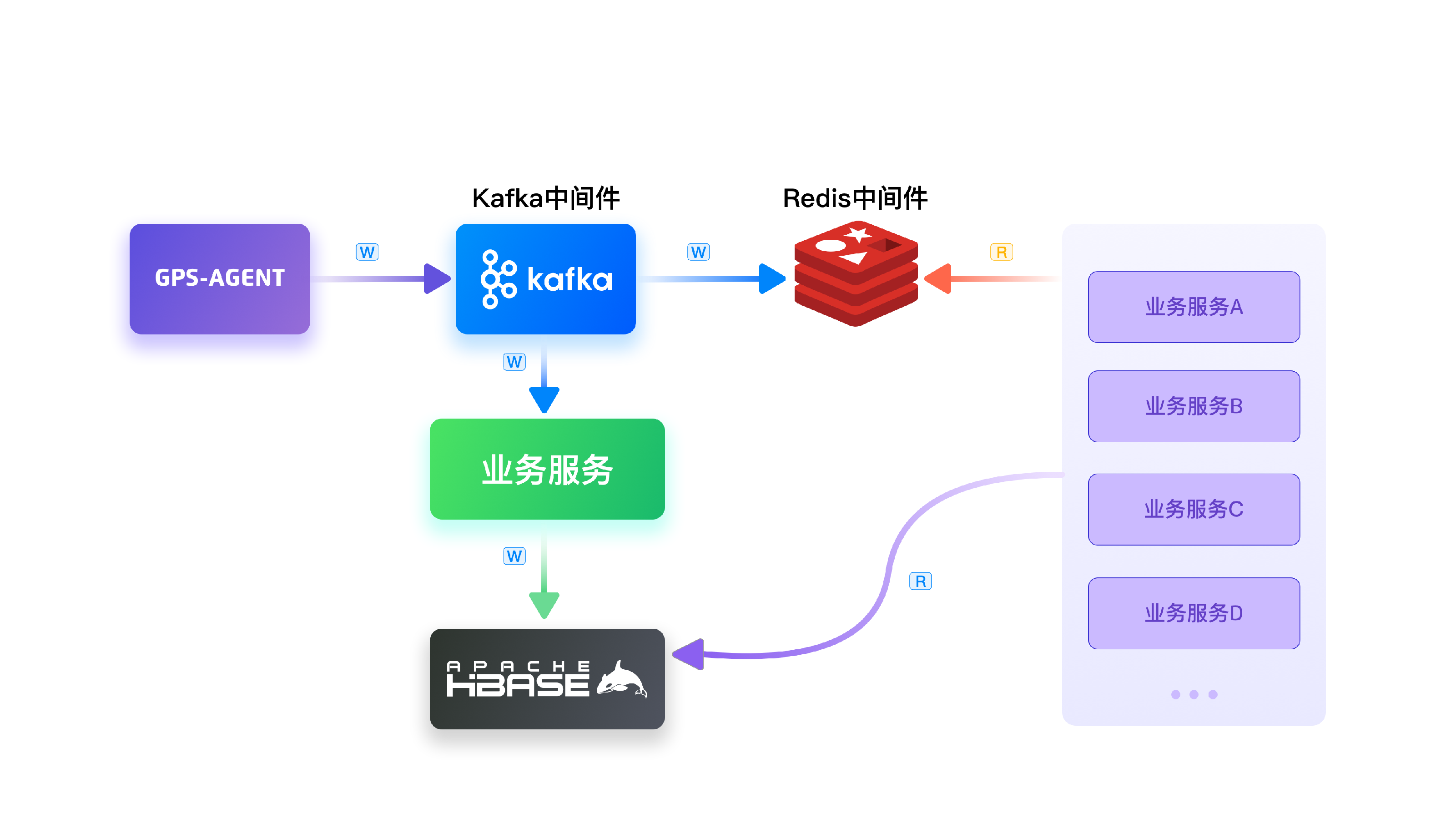
在原有系统的实际运行过程中,我们也遇到了很多痛点。比如说,因为数据保存在 HBase 中,当我们需要查询较大跨度的时间内的数据时,系统的性能会显著下降。
具体可以总结如下:
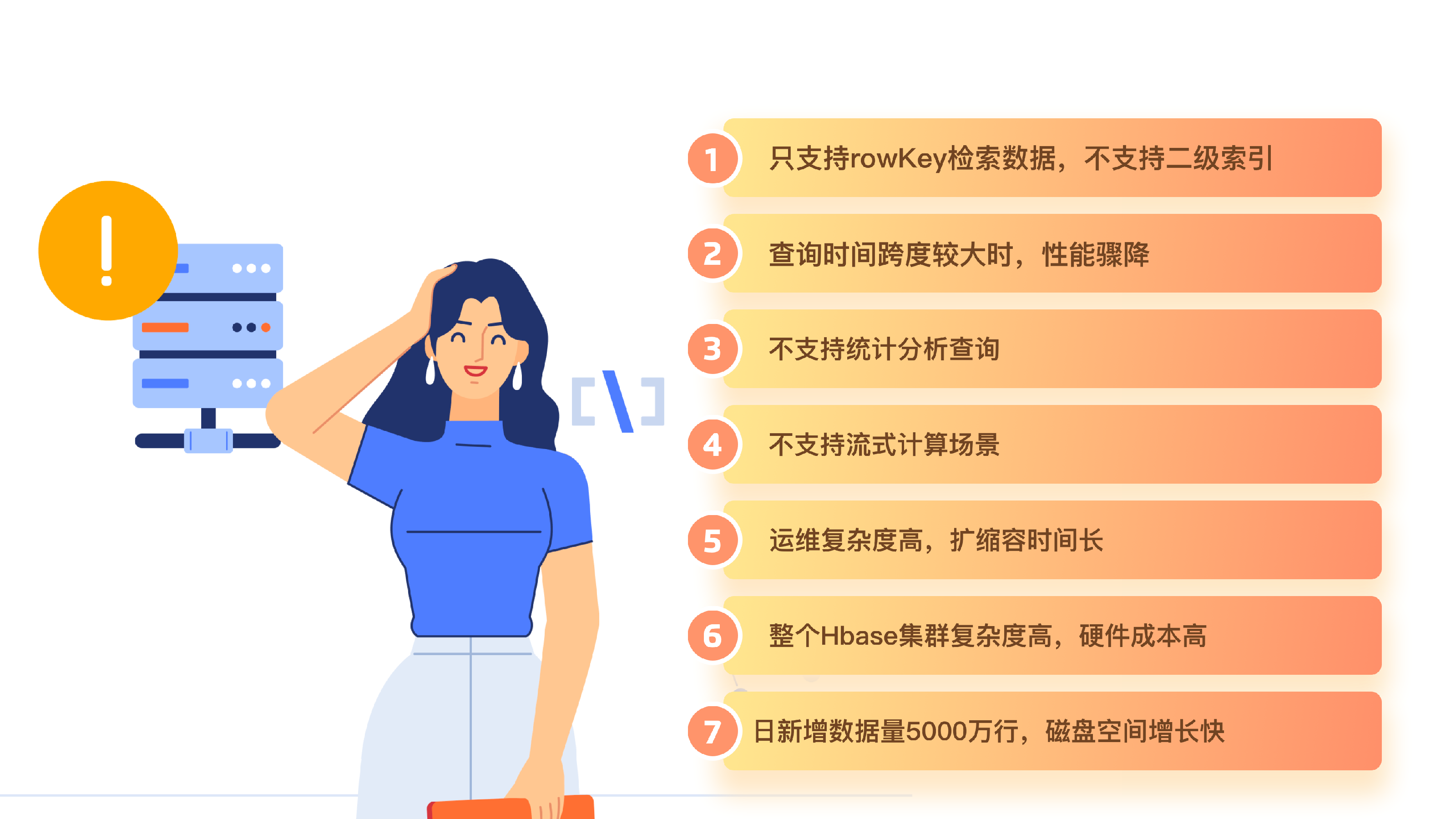
于是我们开始思考,该如何改进系统来解决这些痛点呢?
二. 项目演化
在开始新的技术选型之前,我们重新对业务场景进行了梳理,可以用下面这张图来概括。

我们依次来看一下:
(1)数据不更新不删除:轨迹信息是按照车辆实际信息的时间戳上报,不存在更新和删除的需求。只需要按照某个时限来保存。
(2)无需传统数据库的事务处理:因为数据不需要更新,也就不需要像传统数据库那样用事务来保证更新安全。
(3)流量平稳,一段时间内车辆的数量和上报的频率都可以确定。
(4)数据的查询分析基于时间段和空间区域,这跟业务需求有关。
(5)除存储、查询操作外,还需要根据业务的实际需求进行各种统计和实时计算等操作。
(6)数据量巨大,一天采集的数据超过 5000 万条,并且会随业务规模的不断增长而增长。
技术选型
通过以上分析可以看到,车辆轨迹是典型的时间序列数据,所以用专门的时序数据库来处理会比较高效。在调研阶段,我们对比了几款比较有代表性的时序数据库产品。
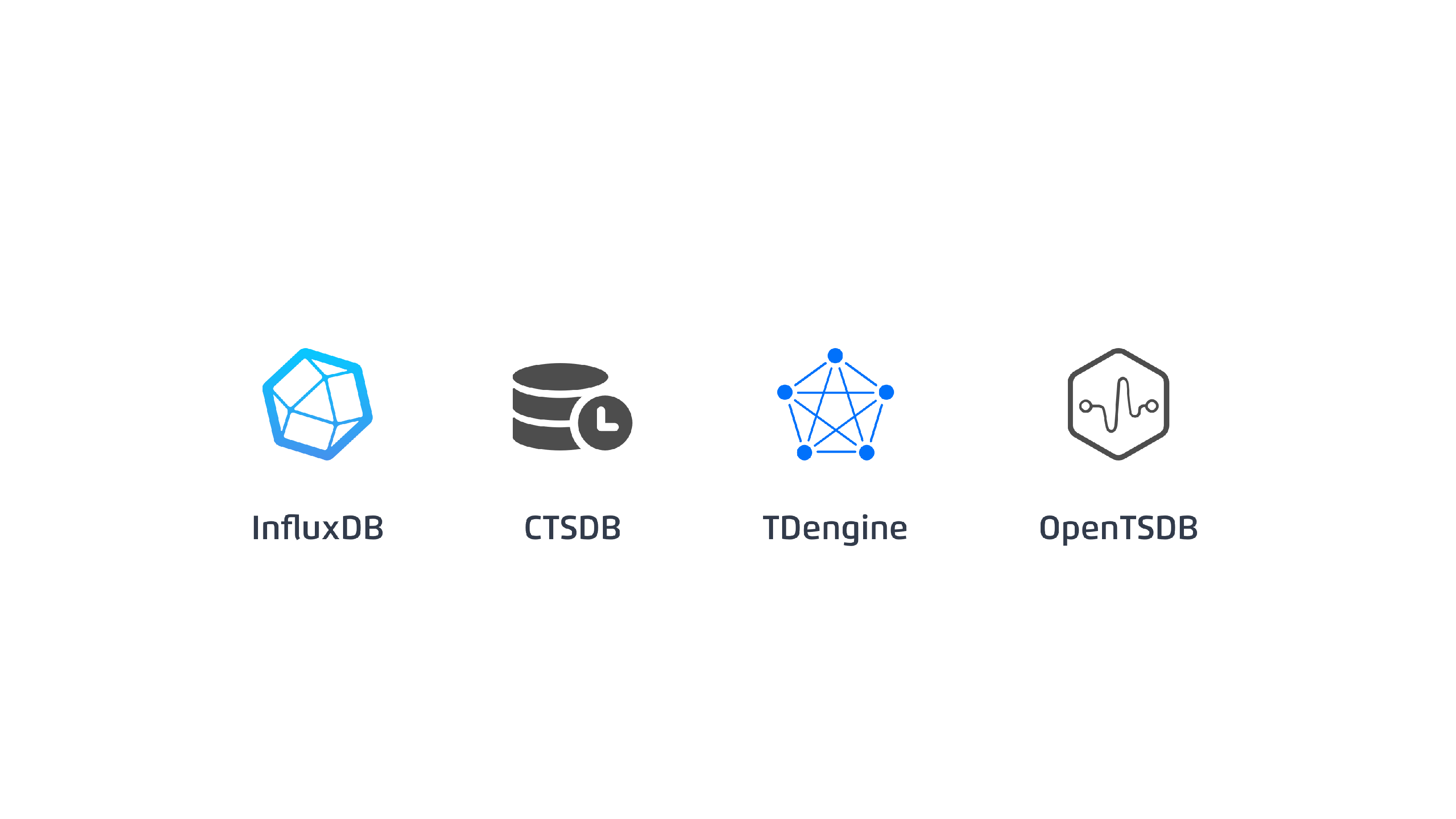
综合对比后的结果如下:
-
InfluxDB 集群版本收费,硬件成本也相对较高;
-
CTSDB 腾讯云时序数据库,内存用量高,费用成本相对较高;
-
OpenTSDB 底层基座还是 HBase ,引入并不能使架构变得简单;
-
TDengine 集群功能开源,具有典型的分布式数据库特征,压缩比例也非常高。
通过对比,我们认为 TDengine 的很多优秀特性能够满足我们的业务场景。
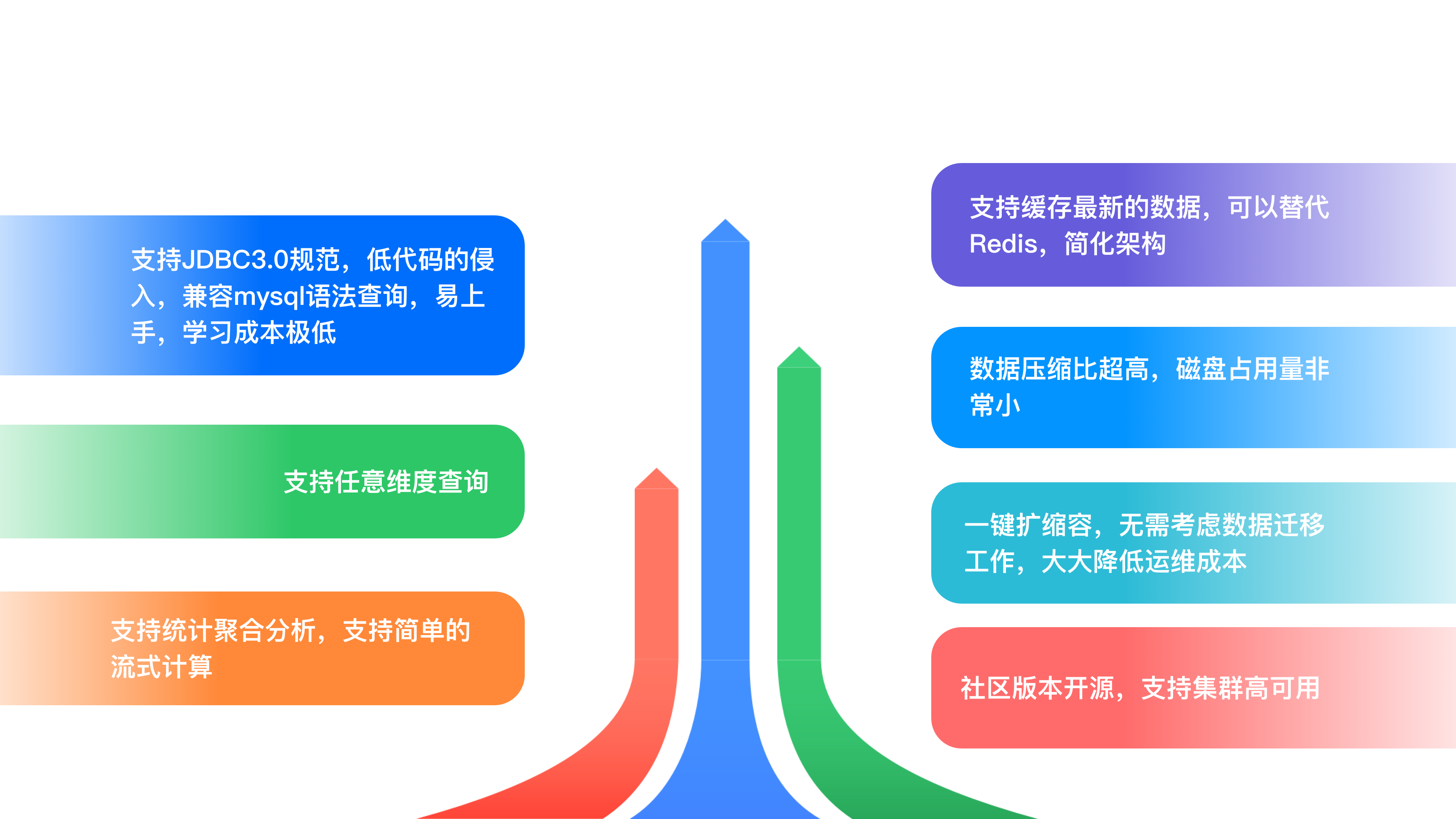
于是我们基于 TDengine 进行了前期调研和演练。具体包括如下几个方面:
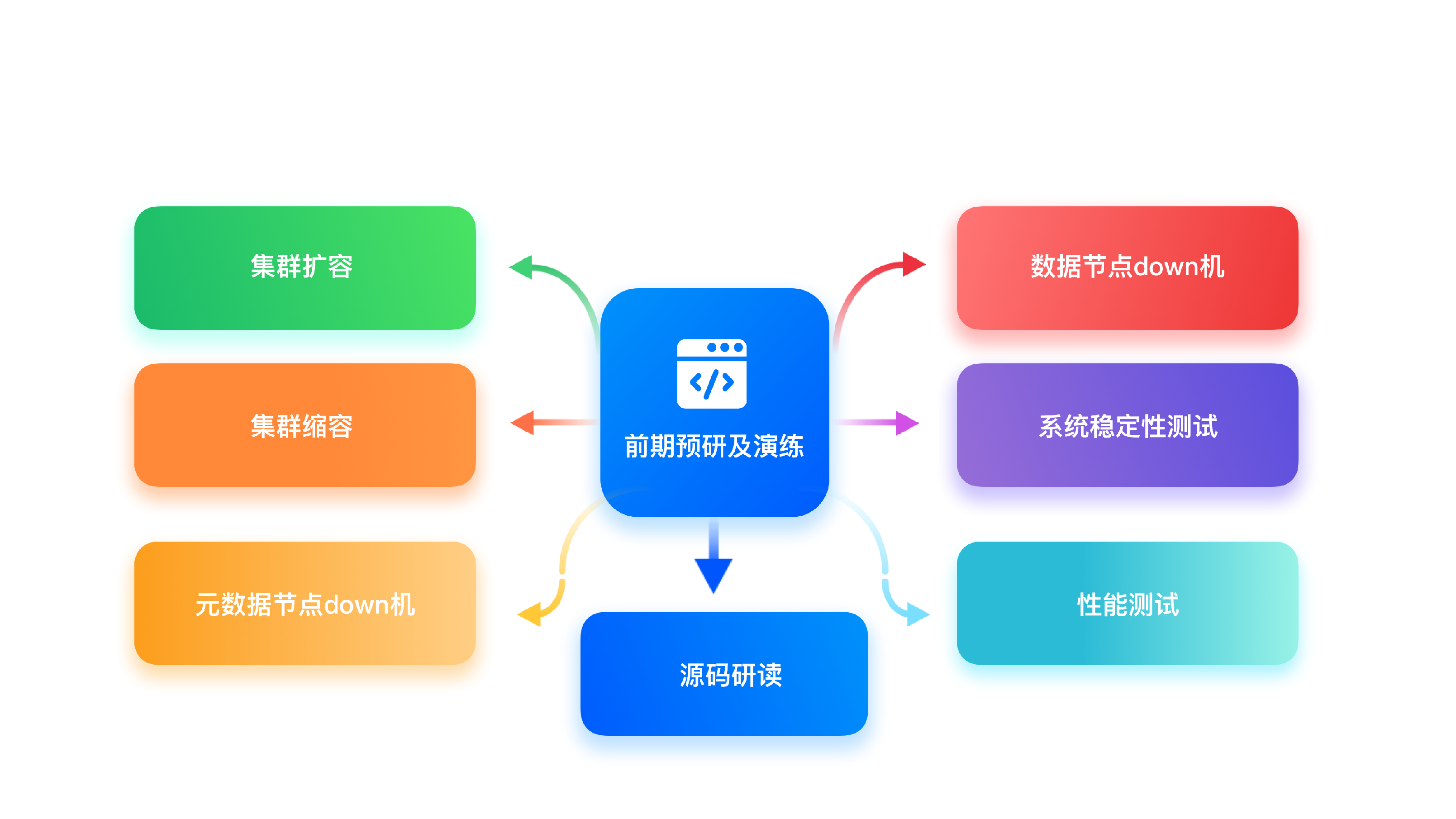
我们从多个方面对 TDengine 的功能和性能进行了全方位的测试,功能完全能够满足我们的需求,性能、压缩率给我们带来了很大的惊喜。
在完成基本的功能和性能测试之后,我们又结合业务进行了场景测试和演练,主要包含如下几方面的工作:
-
数据在写入时候对集群扩缩容
-
cacheLast 的应用是否有效
-
统计聚合分析 interval,interp 的一些业务场景应用
-
update 参数的覆盖场景
-
常用业务的查询语句,同等查询范围的数据对比
三.深入理解 TDengine
在实际落地 TDengine 之前,我们也深入研究了这个系统的架构、设计等各方面特性。这里也简单分享一下 TDengine 的核心概念。
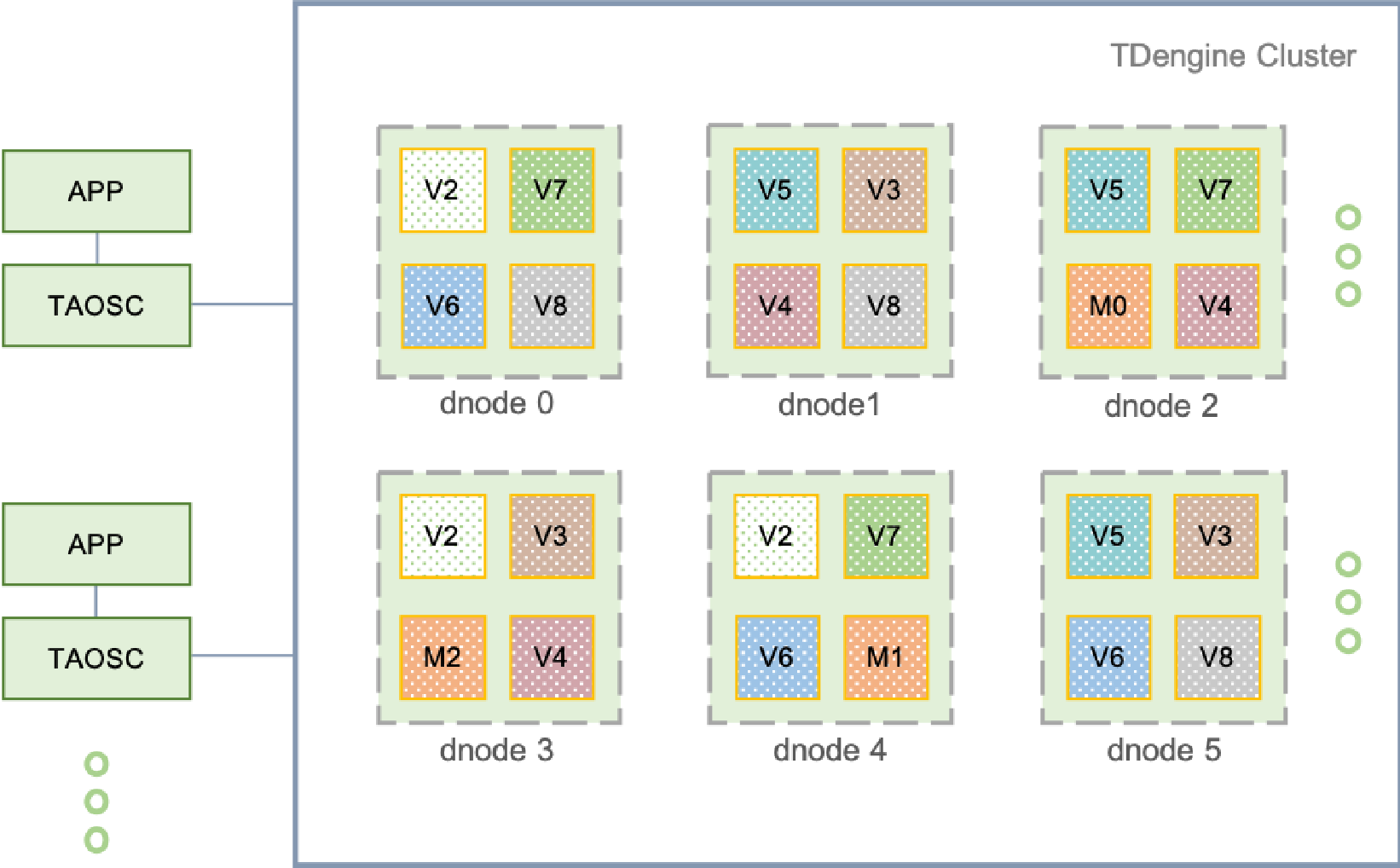
1. TDengine 架构
如果是第一次接触 TDengine,可以看一下如下这张图,其中的 dnode 就是实际存储数据的物理节点,dnode 框中的 V2、V7 等小框叫 vnode,也就是虚拟节点,m0、m1 就是元数据管理节点,存储一些集群信息与表信息,熟悉分布式中间件的朋友肯定能直观地感受到 TDengine 具有非常典型的分布式数据库特征。
2. 超级表
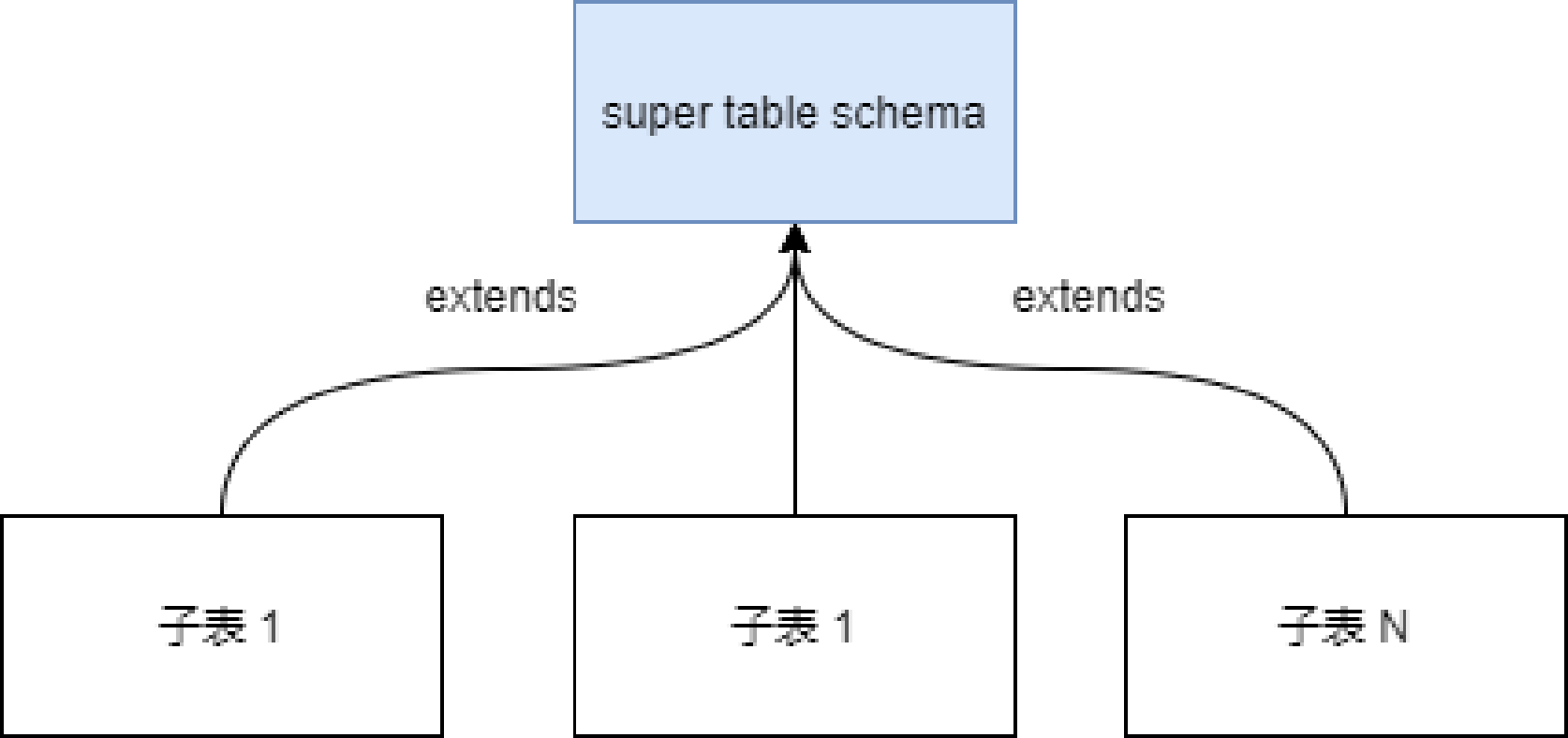
TDengine 有个超级表的概念,例如在跨越速运集团业务场景下,所有的车辆变成一张张子表,所有的子表会继承一张叫超级表的父表,超级表定义子表的结构规范,不存储实际物理数据,我们可以通过只查超级表做数据的统计分析查询,而不用一个个子表去汇总。
3. 高压缩特点
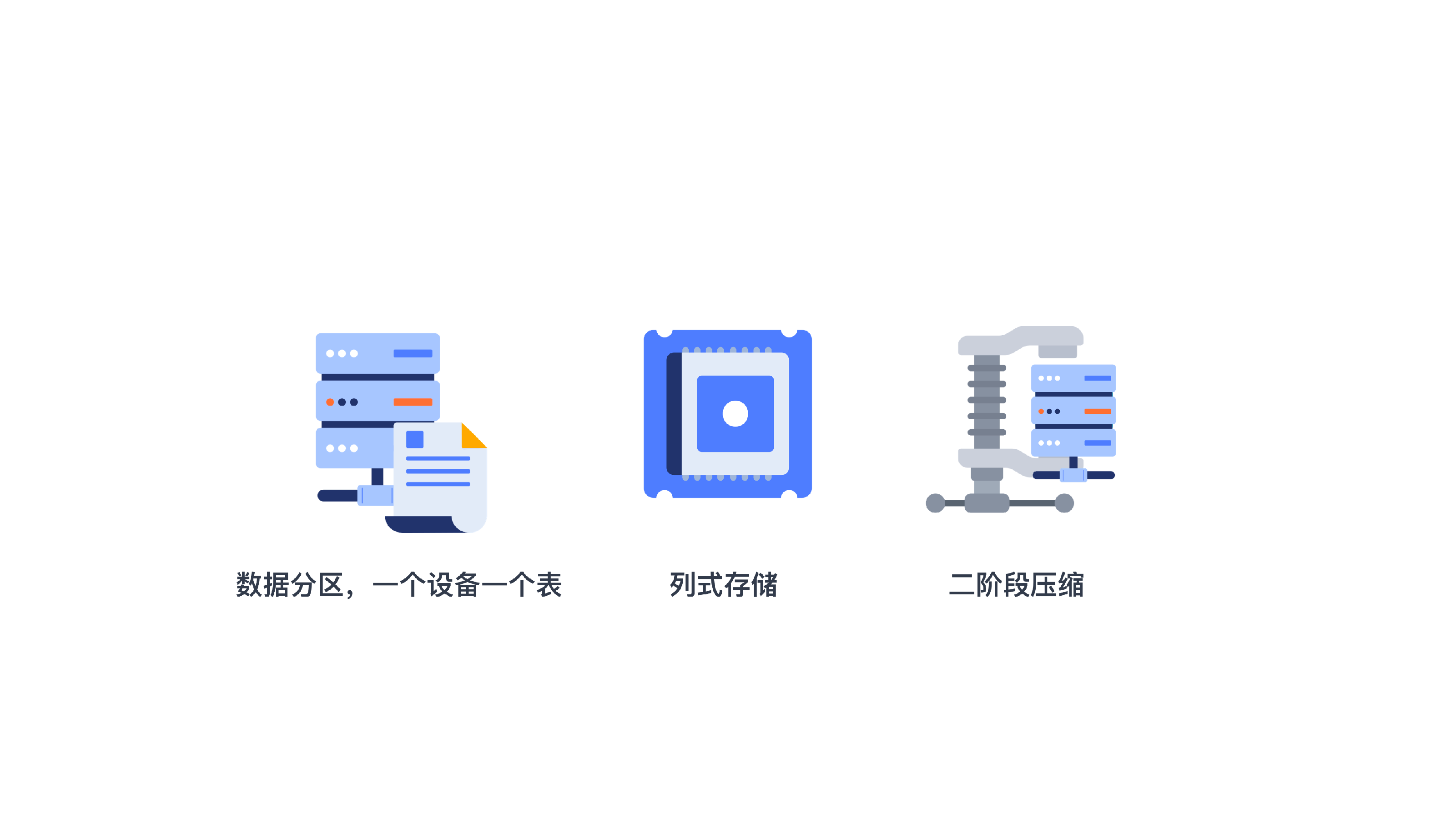
TDengine 采用了二阶段压缩策略,一阶段压缩会使用 delta-delta 编码、simple 8B 方法、zig-zag 编码、LZ4 等算法,二阶段压缩会采用 LZ4 算法。一阶段压缩会针对每个数据类型做特定的算法压缩,二阶段再做一次通用压缩,前提是在建库的时候将参数 comp 设置为 2 。
四.引入 TDengine 之后的架构
在进行了充分的测试和验证之后,我们将 TDengine 引入到了我们的系统之中。新的系统架构如下图所示:
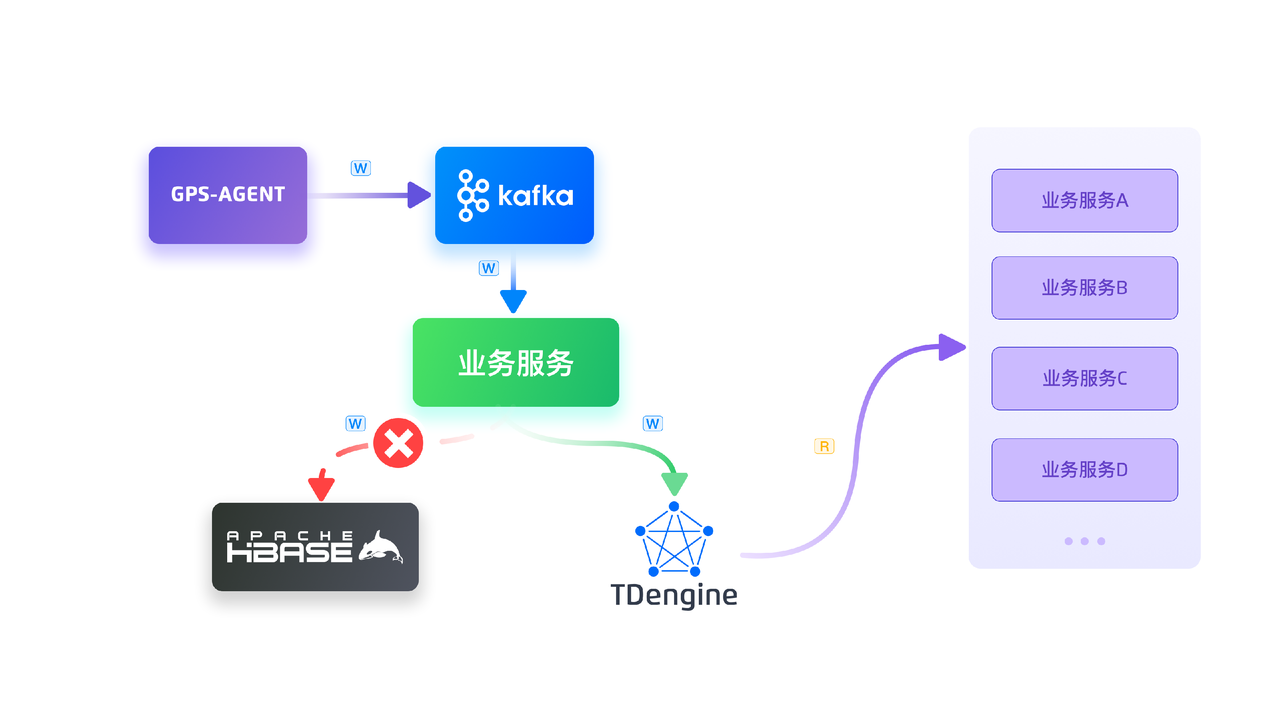
从架构图中可以看到,车载数据依然通过 GPS-AGENT 网关进行报文解析后发送到 Apache Kafka 中,再通过应用多开启一个 Kafka group 同时消费消息,以此达到两端数据的一致。
业务系统最新车辆位置信息不再通过 Redis 读取,这样就简化了架构。查询只读取 TDengine,HBase 在一定的时间后会下线。
五. 优化效果
引入 TDengine 之后,从各项指标来看,数据非常亮眼。
1. 压缩率

如图我们看到一个 5 万行的表,每行在 600 字节以上,压缩后的磁盘 size 是 1665KB,压缩率高达 1%。接下来我们看个百万行的子表。

它实际占用磁盘大小为 7839KB。我们的压缩效果比 TDengine 官方的各种测试还要好很多,这应该与我们业务数据重复度相对较高有一定关系。
2. 日增量
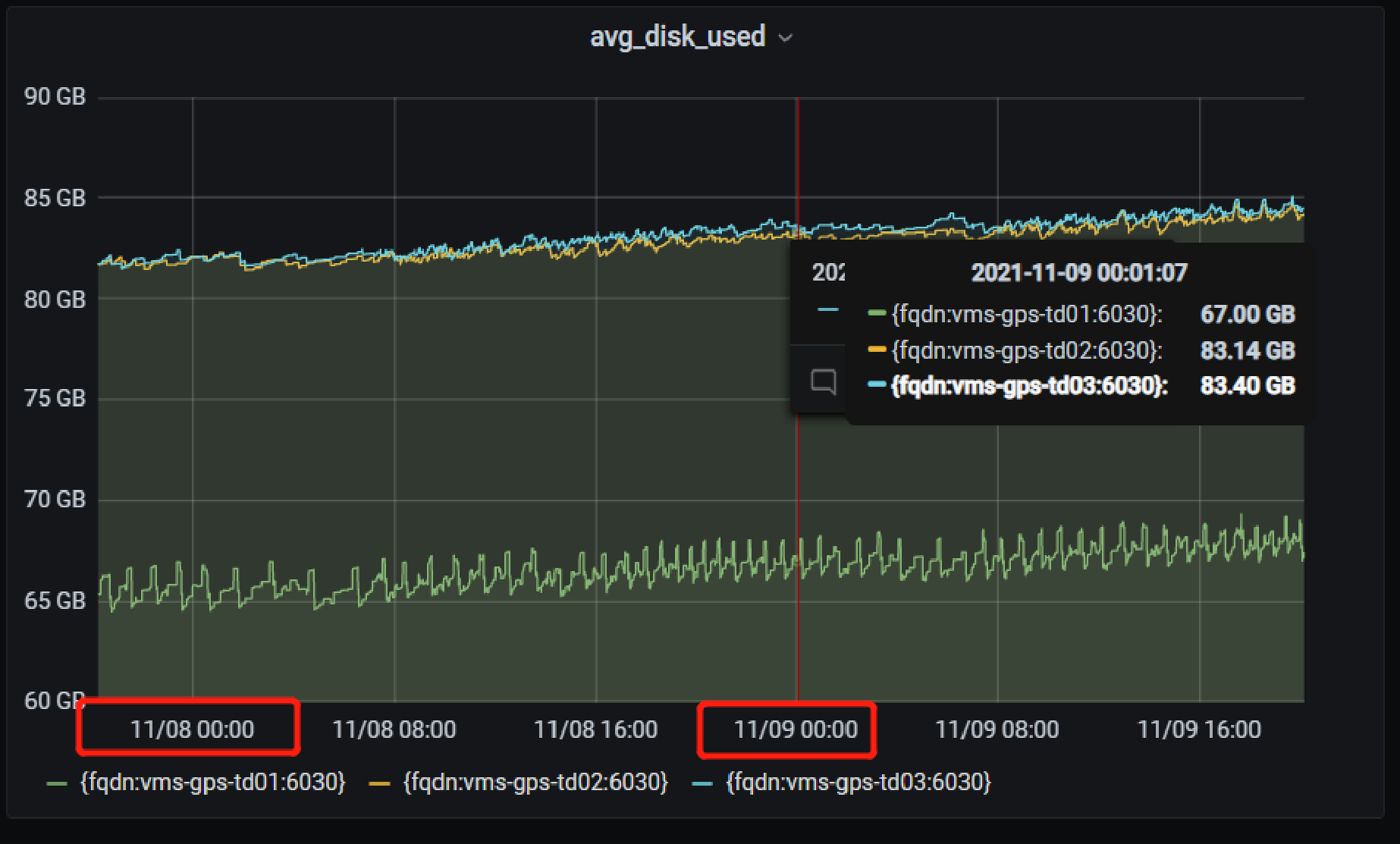
我们现在的业务日写入量超过 5000 万,对 TDengine 来说日增的磁盘大小基本维持在单台 1.4G 左右。
3. 各项指标的整体对比
下图是我们实际落地前后各项指标的对比。

下图是数据增量的对比。
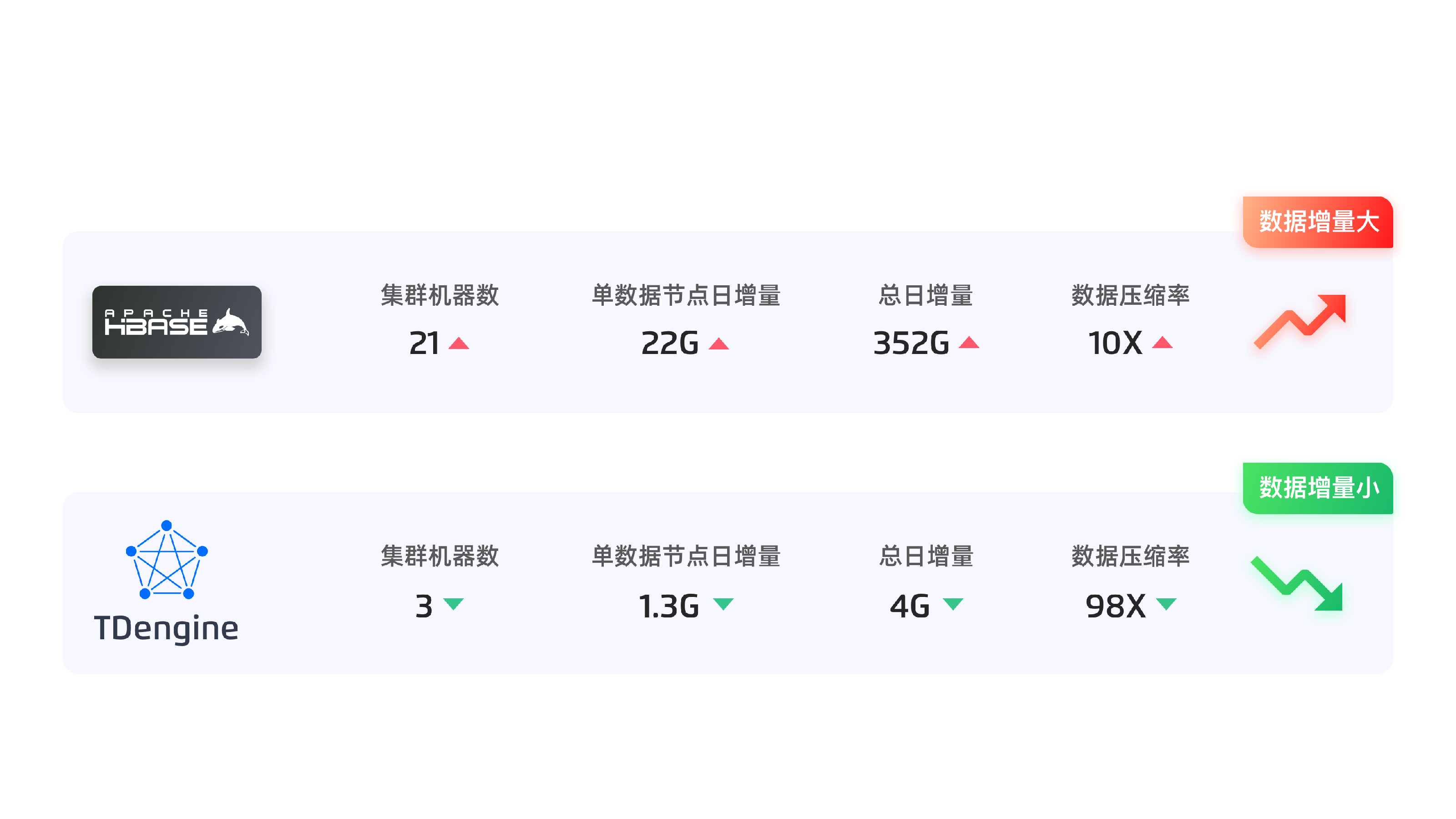
从对比可以看出,TDengine 确实极大降低了我们的各项成本。
六.问题和建议
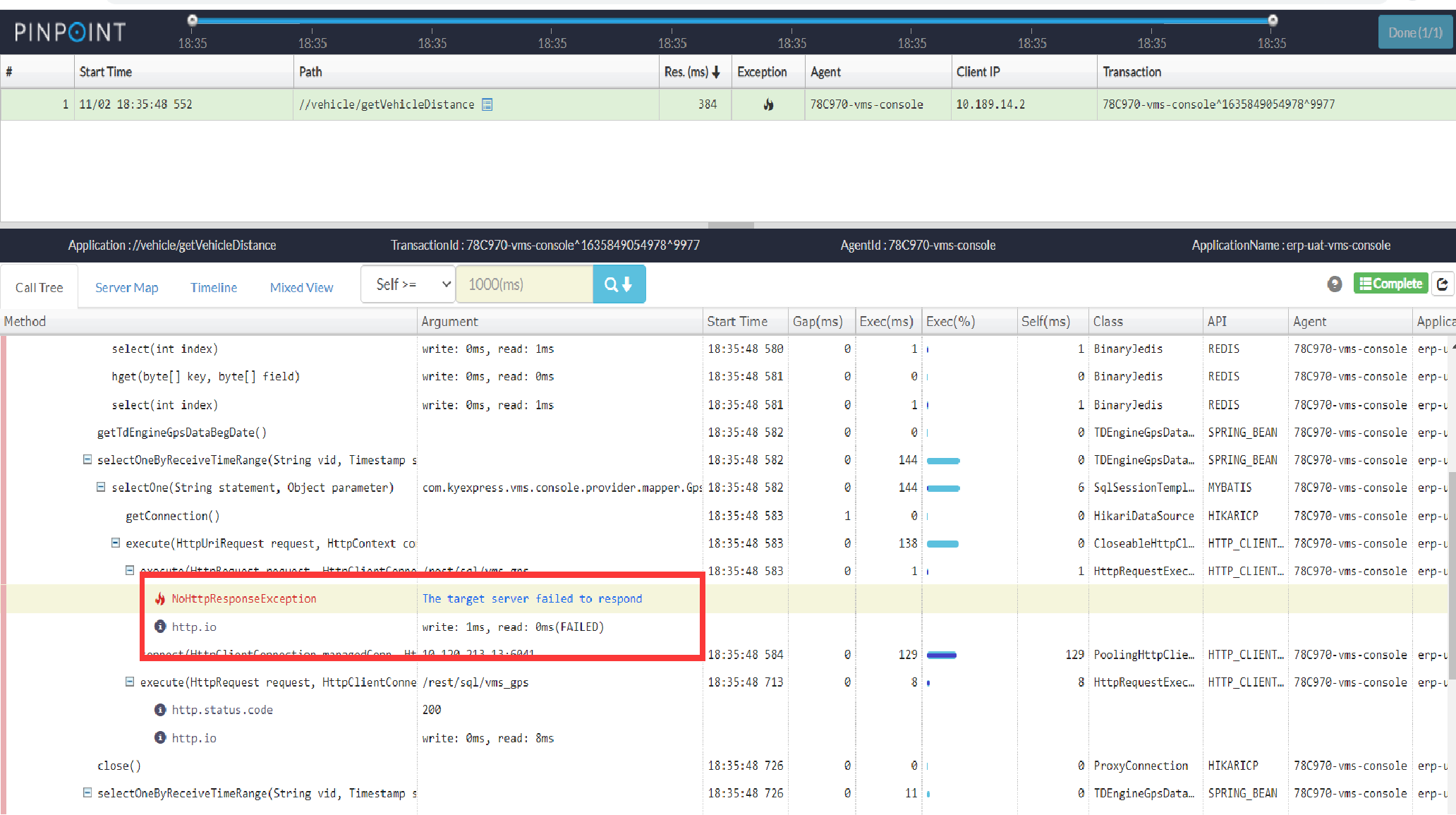
一个相对较新的系统,在使用过程中难免会遇到一些问题,我们也和 TDengine 的研发团队一起去定位、解决。
比如下面这个就是我们在使用 JDBC 过程中遇到的问题。我们也给官方提 PR 修复了。这就是开源的魅力吧,大家都可以参与进来。
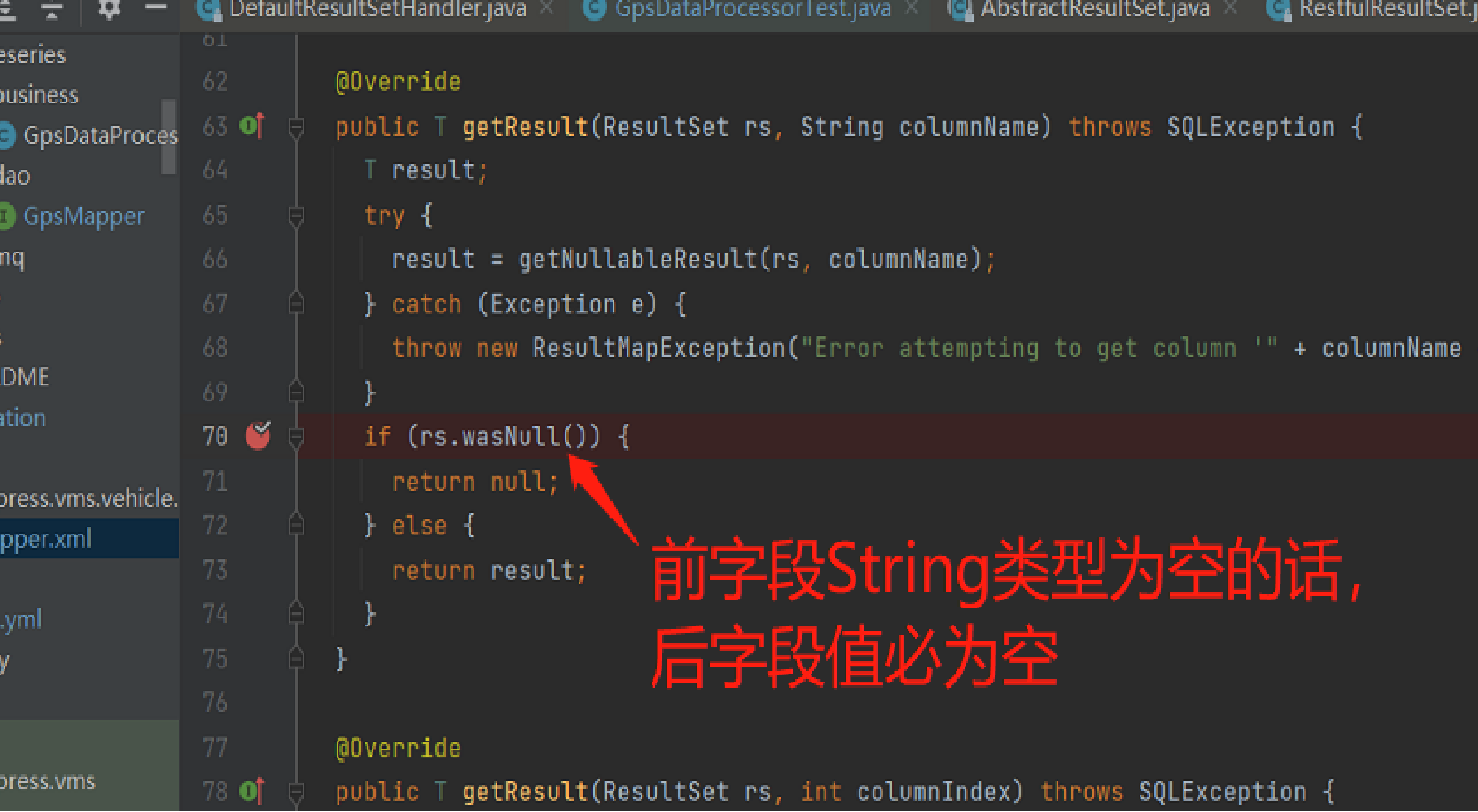
有两个地方我们也希望 TDengine 能进一步优化:
1. 2.3.0.x 以下的监控功能还比较简单,我们期待后期的版本能提供更强更细致的监控。我们注意到新发布的版本引入了一个叫 TDinsight 的监控工具,我们也会尽快尝试一下。
2. 目前的 interval 函数还不支持按业务列 group by 普通列,后续希望也能够得到支持。
最后,在尝试和落地 TDengine 的过程中,我们也得到了涛思数据多位同事的大力支持,在此一并表示感谢。
✨想了解更多TDengine的具体细节,欢迎大家在GitHub上查看相关源代码。✨
GitHub - taosdata/TDengine: An open-source big data platform designed and optimized for the Internet of Things (IoT).An open-source big data platform designed and optimized for the Internet of Things (IoT). - GitHub - taosdata/TDengine: An open-source big data platform designed and optimized for the Internet of Things (IoT). https://github.com/taosdata/TDengine
https://github.com/taosdata/TDengine
这篇关于服务器数量从 21 台降至 3 台,TDengine 在跨越速运集团的落地实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







