本文主要是介绍【C语言】函数栈帧---函数的创建于销毁过程剖析(一览无遗),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

目录
前言:
1.铺垫
寄存器
main函数被谁调用
2.正题
结论:
前言:
- 学习这么久以来,可能有很多疑问:
- 局部变量怎么创建的?
- 为什么局部变量的值是随机的?
- 函数是怎么传参的?传参的顺序是怎么样的?
- 形参和实参是什么样的关系?
- 函数调用是怎么做的?
- 函数调用结束后是怎么返回的?
- 那么本篇博文就来一一讲解一下。
- 环境:vs2021,大家也可以使用更低版本的编译器更容易观察出现象。(推荐vc6.0)在不同的编译器下面,函数调用的过程中栈帧的创建是稍有差异的,大体逻辑是一样的具体差异的细节取决于编译器的实现。(越新的编译器封装的就越复杂,不容易抽离出函数栈帧这个过程)
1.铺垫
寄存器
百度百科链接
寄存器中有eax/ebx/ecx/ edx /ebp/esp
重点是esp/ebp两个寄存器中存放的是地址,这两个地址是用来维护函数栈帧的。
一般吧ebp叫做栈底指针,把esp叫做栈顶指针,栈区的使用习惯是先使用高地址再使用低地址。我们今天测试环境中是rbp,rsp
每一个函数调用都要在栈区上创建或者开辟一块空间。

main函数被谁调用
我们调试调用堆栈
不会调试的可以先看我的这篇文章:vs2021环境调试详细

调用关系


那接下来我们就来看看具体的过程剖析
2.正题
F10运行调试起来,右键来到反汇编,看我们的反汇编代码

刚进入,我们的rbp和rsp在为我们的调用main函数的函数维护栈帧,进入main函数过后

先压入了一个rbp和一个rdi
再讲rsp减148h(这是一个16进制数字)

接着往下:
![]()
lea的意思是:load effective address 就是1加载一个地址造rbp中
那么现在的rbp和rsp就维护了main函数维护的这块空间。

main函数的空间开辟好了过后,开始执行main函数中的代码:

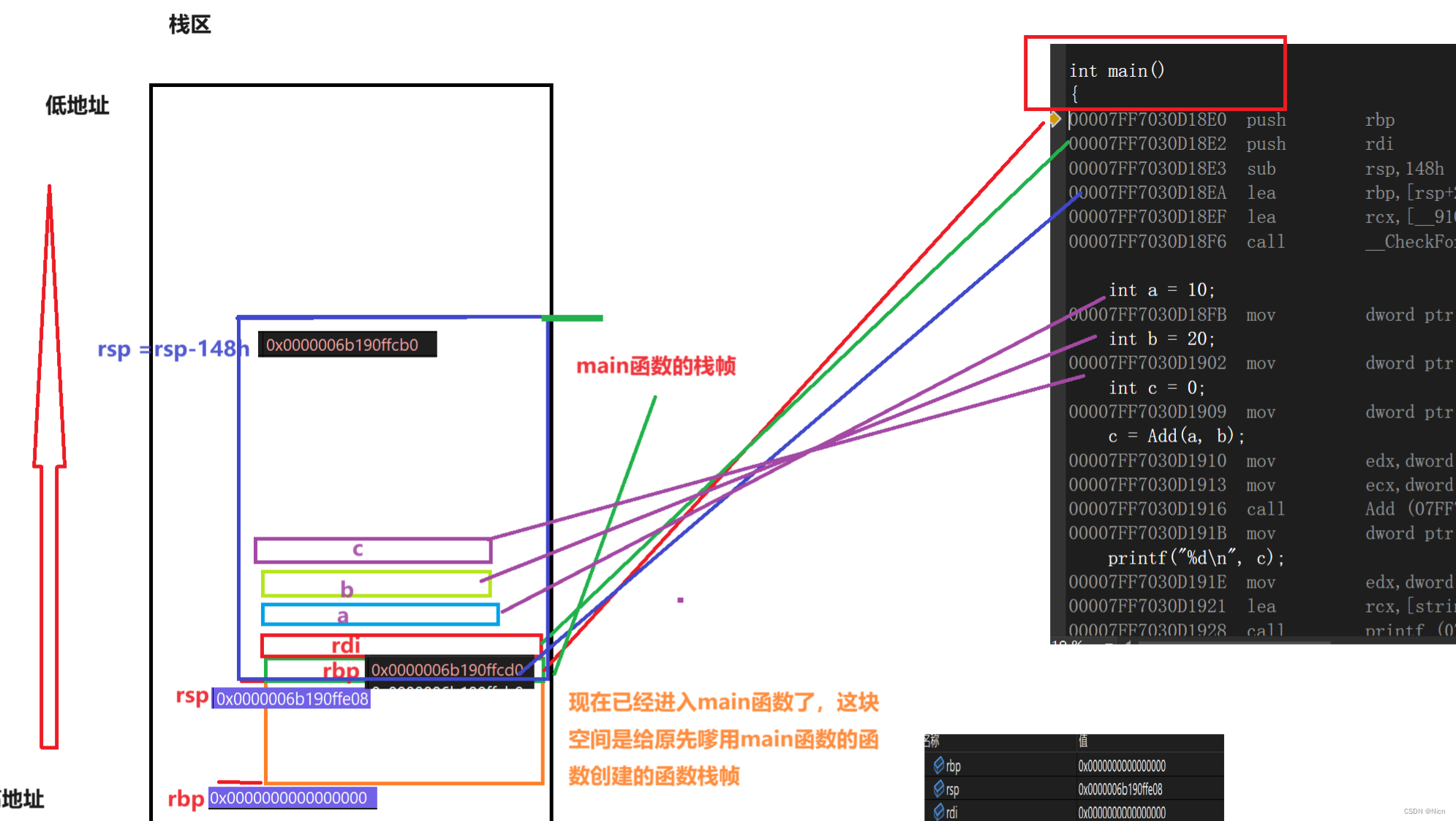
往下执行:

edx 存储20
ecx 存储10
然后call调用add函数
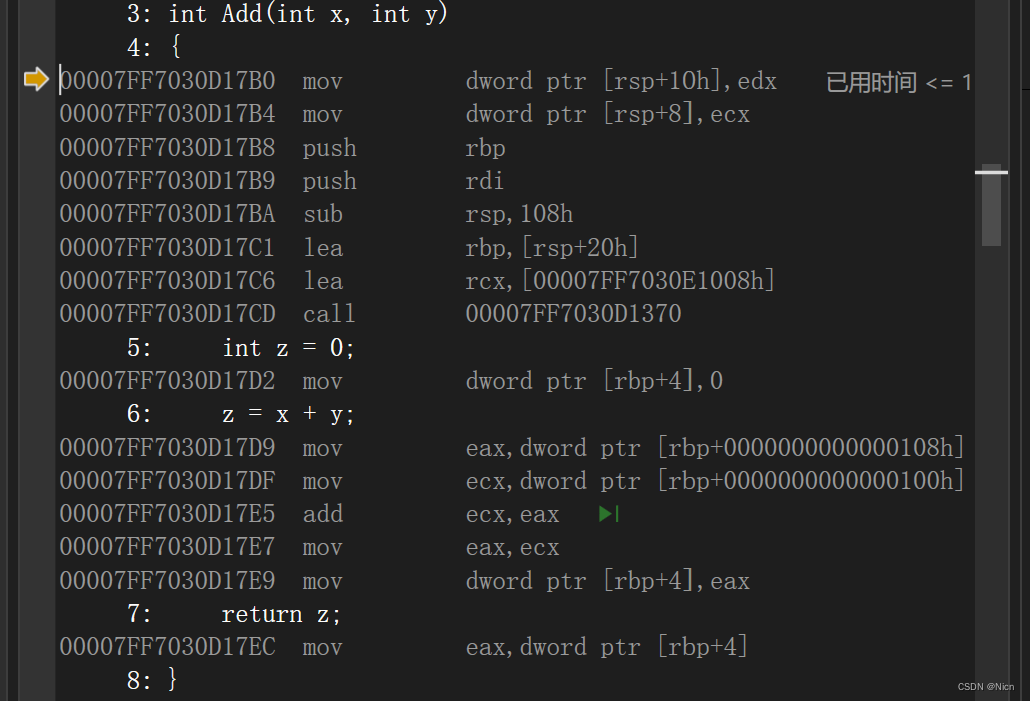
先将edx的值放到rsp+10的位置
将ecx的值放到rsp+8的位置
压入rbp和rdi
 return后,将rbp+E8h给rsp,相当于销毁了add的栈帧
return后,将rbp+E8h给rsp,相当于销毁了add的栈帧
将rbp和rid出栈(这里由于我重新启动了一次所以数据不一样,不过还是可以看到rbp和rsp之间相差20.回到了起点,原先的空间被释放了)

结论:
那到这里我们就已经可以回答了
局部变量是如何创建的:
调用函数的时候在栈上开辟空间过后,在这块空间里给变量分配空间。
为什么局部变量不初始化是随机值?
因为随机值是随机写入的,创建好空间后就会将这块空间的值变为随机值。初始化就将随机值覆盖
函数如何传参:
还没有调用函数的时候,就将这参数的值通过寄存器(ebx,ecx)push到了栈顶,通过指针偏移的方式找到形参。
形参和实参的关系:
形参是在压栈时独立开辟的空间(ebx,ecx),值相同,空间二者各自独立。
函数是如何返回的
调用函数之前,都会调用call指令,会将调用call指令的后一条指令的地址先压入栈,然后将函数调用的上一个函数的rdp也压入栈,函数调用结束返回pop(弹出edp)就得到我们上一个函数的函数栈帧的维护地址,就回到了原始栈帧空间,又有下一条指令的地址,就可以继续运行。返回值通过寄存器eax带回。
这篇关于【C语言】函数栈帧---函数的创建于销毁过程剖析(一览无遗)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






