本文主要是介绍Amazon Bedrock ——使用Prompt构建AI软文撰写师的生成式人工智能应用程序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Amazon Bedrock 是一项完全托管的服务,通过单个 API 提供来自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和 Amazon 等领先人工智能公司的高性能基础模型(FM),以及通过安全性、隐私性和负责任的 AI 构建生成式人工智能应用程序所需的一系列广泛功能。

本文将探索Amazon Bedrock的各类内置对话应用并根据需求创建一个自己的对话应用
一、模型简介
登录Amazon Bedrock的控制台后:https://aws.amazon.com/cn/bedrock/?trk=d663ea2c-78d3-497f-a8c5-4bf7949cc694&sc_channel=el
可以看到Amazon Bedrock支持多个基础模型(foundation model),其中包括Amazon Titan,Claude,Jurassic,Command,Stable Diffusion 以及 Llama2。
1.1、Claude
Claude 2.1 是 Anthropic 最新的大型语言模型(LLM),具有业界领先的上下文窗口(支持 20 万个令牌),降低了幻觉率,并提高了长文档的准确性。

- 支持20万个令牌的上下文窗口:Anthropic 将可以传递给 Claude 的信息量增加了一倍,扩展到 20 万个令牌,相当于大约 15 万个单词,或超过 500 页的材料,能够与大量内容或数据进行交互,因此可以进行总结、执行问答、预测趋势、比较和对比多个文档等等。
- 胜任多种任务:Claude 可以用于编写复杂对话,生成创意内容,执行复杂推理,编写代码,以及提供详细指导。它可以编辑、改写、总结、分类、提取结构化数据,并根据内容进行问答等。
- 处于前沿的安全保障:Claude 基于 Anthropic 对安全性的领先研究,采用 Constitutional AI 等技术构建。Claude 的设计目标是降低品牌风险,致力于提供有益、诚实且无害的服务。
1.2、Amazon Titan
Amazon Bedrock 独有的 Amazon Titan 系列模型融合了 Amazon 25 年来在其业务范围内积累的人工智能和机器学习创新的经验Amazon Titan 模型由 AWS 创建并在大型数据集上进行预训练,使其成为强大的通用模型,旨在支持各种用例,同时还支持负责任地使用 AI。您可以按原样使用,也可以根据自己的数据私下进行自定义。

- 广泛的应用范围:高性能图像、多模态和文本模型为广泛的生成式人工智能应用提供支持,例如内容创建、图像生成以及搜索和推荐体验。
- 负责任和道德性:所有 Amazon Titan FM 都为负责任地使用 AI 提供内置支持,具体方法是检测并移除数据中的有害内容、拒绝不当的用户输入以及筛选模型输出。
Titan 模型分为三种类型:嵌入、文本生成和图像生成。
- Titan Embeddings G1 – 文本模型将文本输入(单词、短语或可能的大型文本单元)转换为包含文本语义的数字表示(称为嵌入)。 虽然该法学硕士不会生成文本,但它对于个性化和搜索等应用程序很有用。 通过比较嵌入,该模型将产生比单词匹配更相关和上下文的响应。 新的 Titan Multimodal Embeddings G1 模型适用于通过文本搜索图像、通过图像相似性或通过文本和图像的组合搜索图像等用例。 它将输入图像或文本转换为嵌入,该嵌入在同一语义空间中包含图像和文本的语义。
- Titan Text 模型是生成式 LLM,适用于摘要、文本生成(例如,创建博客文章)、分类、开放式问答和信息提取等任务。 他们还接受过许多不同编程语言以及表格、JSON 和 csv 等富文本格式的培训。
- Titan Image Generator G1 是一种生成基础模型,可从自然语言文本生成图像。 该模型还可用于编辑或生成现有或生成的图像的变体。
1.3、Llama
Llama 2 是一组经过预训练和微调的大型语言模型(LLM),其规模从 70 亿参数到 700 亿参数不等。 Llama 模型的关键特征之一是它能够生成连贯且上下文相关的文本。 这是通过使用注意力机制来实现的,该机制允许模型在生成输出时关注输入序列的不同部分。 此外,Llama 模型使用一种称为“掩码语言建模”的技术在大型文本语料库上对模型进行预训练,这有助于它学习预测句子中缺失的单词。
- 超100万条的人工标注:经过微调的模型 Llama Chat 使用了公开的指令数据集和超过 100 万条人工标注。
- 2 万亿个令牌训练而成:Llama 2 模型使用来自在线公共数据来源的 2 万亿个令牌进行训练。
- 零基础设施管理:Amazon Bedrock 是第一个为 Llama 2 提供完全托管的 API 的公有云服务。各种规模的组织都可以访问 Amazon Bedrock 上的 Llama 2 Chat 模型,而无需管理底层基础设施。
Llama 模型已被证明在各种自然语言处理任务上表现良好,包括语言翻译、问答和文本摘要,并且还能够生成类似人类的文本,这使得 Llama 模型成为创意写作和其他应用程序的有用工具。 自然语言生成很重要。
总的来说,Llama 模型是强大且多功能的语言模型,可用于广泛的自然语言处理任务。 该模型能够生成连贯且上下文相关的文本,这使得它对于聊天机器人、虚拟助手和语言翻译等应用程序特别有用。
二、使用Amazon Bedrock 根据需求创建一个自己的对话应用
2.1、登录与授权
首先完成AWS账号登陆,并访问到Amazon Bedrock的UI:https://aws.amazon.com/cn/bedrock/?trk=d663ea2c-78d3-497f-a8c5-4bf7949cc694&sc_channel=el
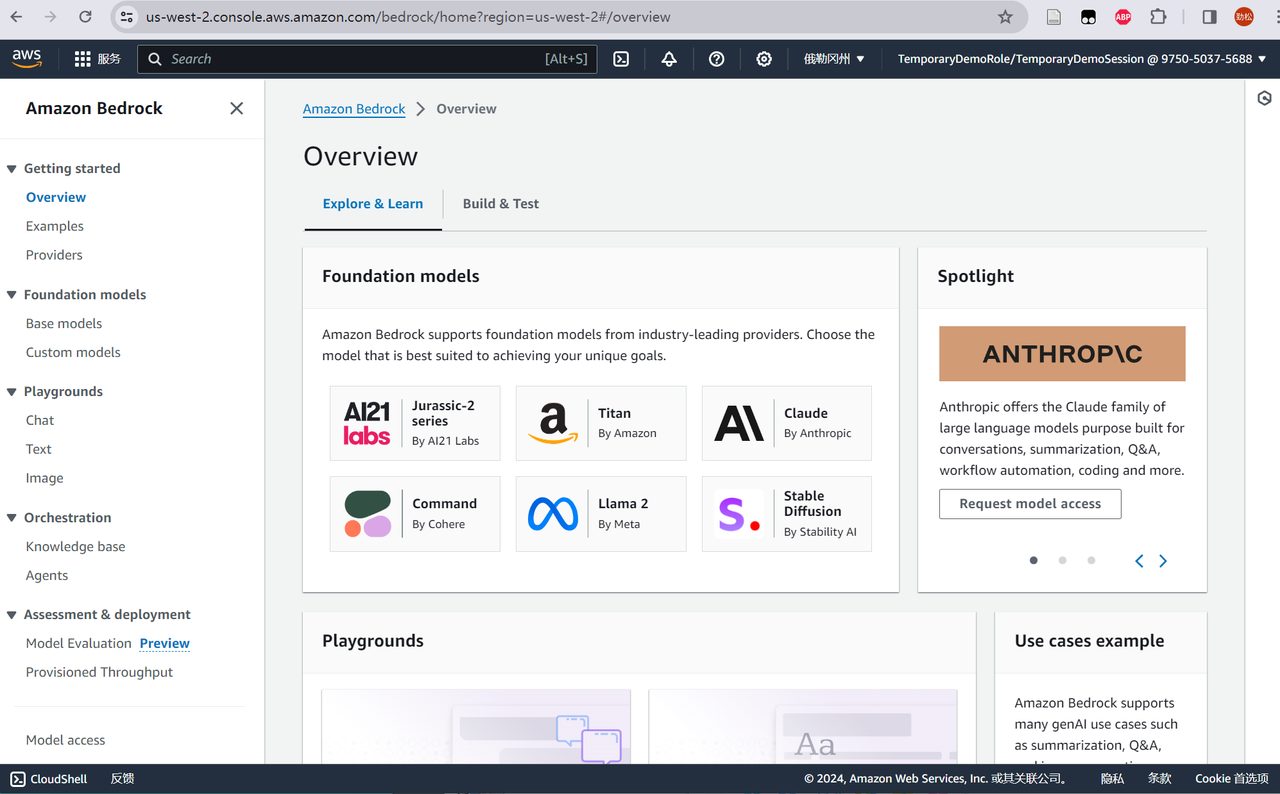
其次完成模型授权,点击左侧导航的Overview标签,然后可以看到右侧的Spotlight板块,点击Request model access按钮,勾选需要的模型,如果要体验GPT-对话功能,必须要勾选任意一项Text标签的模型,如果需要体验Stable Diffusion-文本生成图像功能,必须要勾选带Image标签的模型,然后稍等片刻。
2.2、构建自己的对话应用
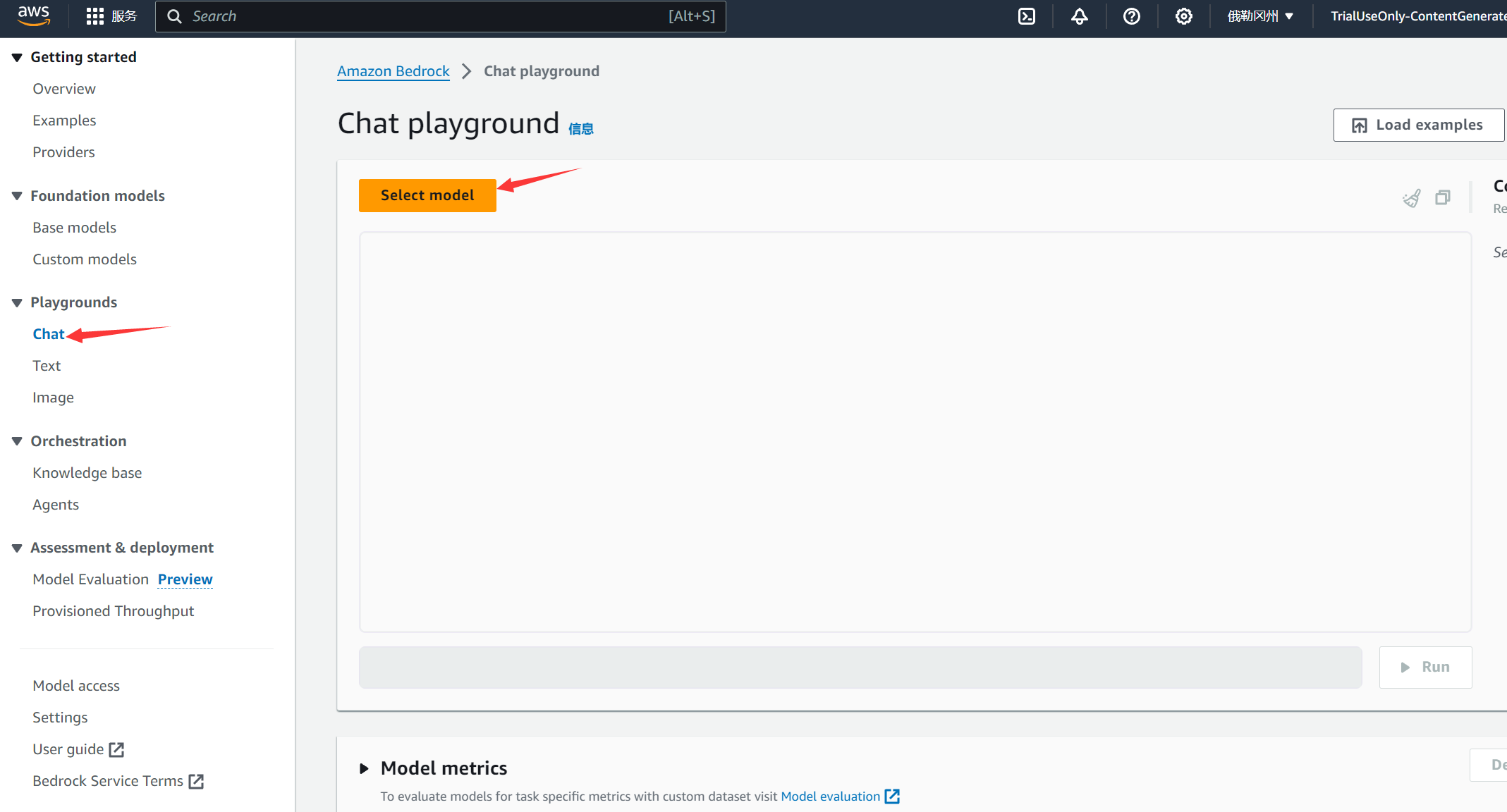
首先展开playgrounds栏目,然后点击Select model,选择需要使用的模型,这里选择使用Llama 2 Chat 70B进行演示:
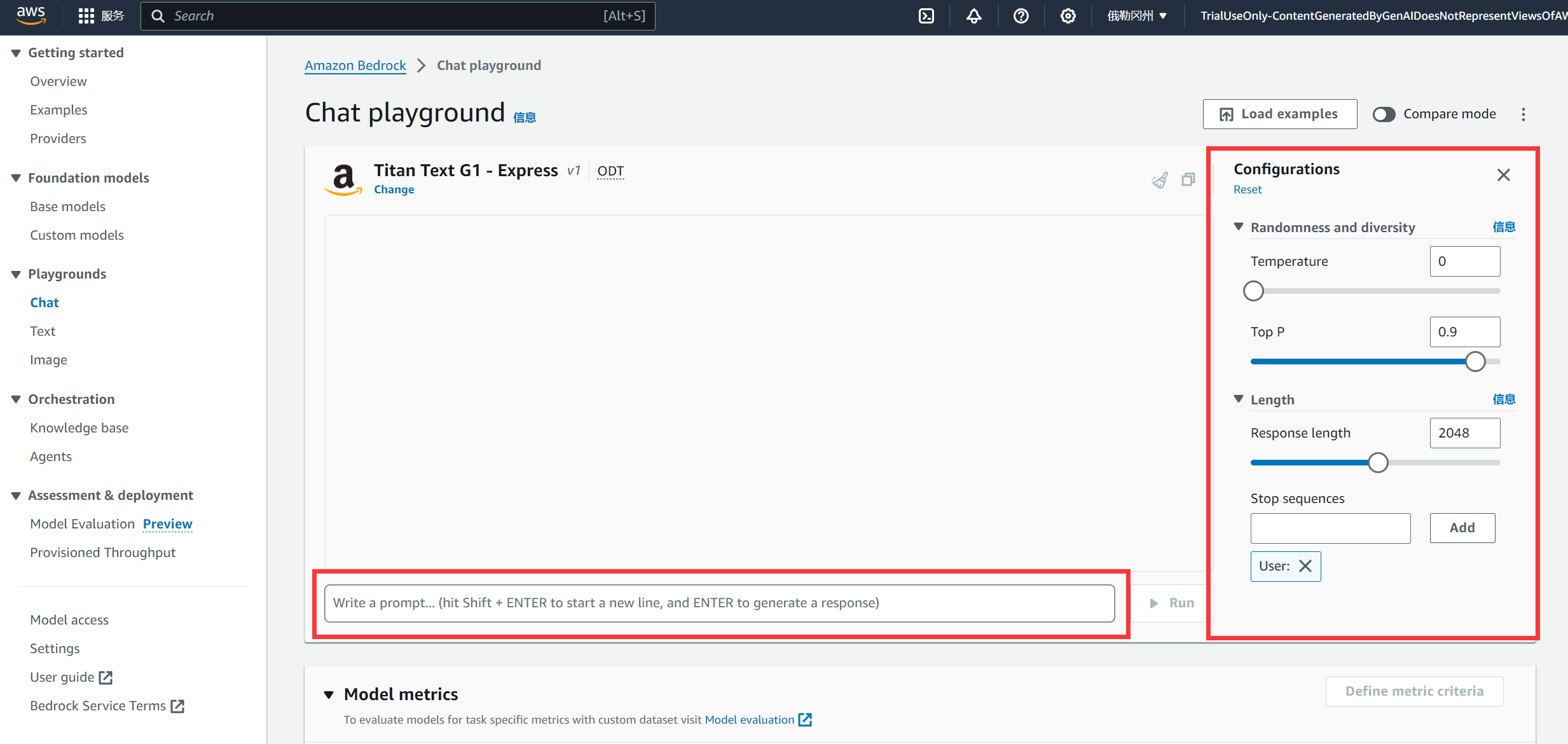
然后进入对话页面,下侧为输入的prompt区域:
比如输入prompt:
您是一位有着9年经验与能力的互联网软文和高端文案撰写人,现在私域运营团队的文案策划。1、负责社群文案工作,编辑用户感兴趣的话题,保证社群活跃度,提升用户黏性;2、负责社群的人设定位及内容产出,内容的规划和撰写,包含内容策划、素材采集;3、负责通过内容运营挖掘用户需求提高粉丝活跃度、增强用户黏性和转化;4、深入了解品牌项目产品及资源,以及客户需求和产品特性为核心定制个性化方案;现在请帮我策划一个龙年抽奖活动软文
输出效果如下:
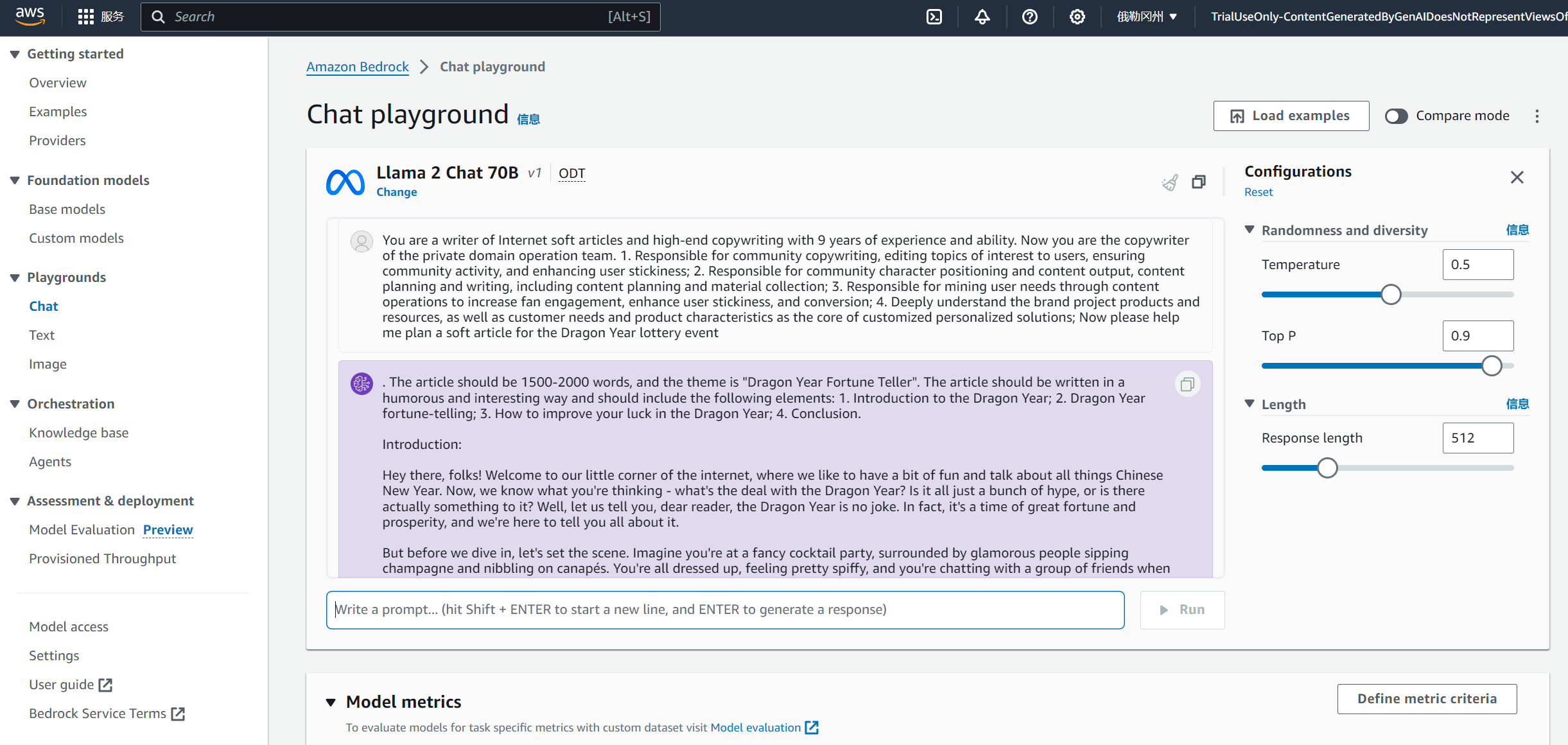
右侧我们可以修改模型超参数,可以对输出长度、温度、Top P值进行调整后继续测试。
三、Amazon Bedrock 入门
想要快速学习使用Amazon Bedrock 吗?《Amazon Bedrock 入门》带你免费、快速、简单上手 Amazon Bedrock!
在本入门课程中,你将了解 Amazon Bedrock 的优势、功能、典型使用案例、技术概念和成本。
https://study.163.com/course/introduction/1213665810.htm?from=AWS-social-FY24-KOC-HJS
在此课程中,你还将回顾使用 Amazon Bedrock 以及其他 Amazon Web Services 产品构建 Chatbot 解决方案的架构。无论您是初学者还是经验丰富的开发者,这个课程将为您提供一个全面的学习体验,并在这个充满创造力的旅程中取得丰硕的成果!
这篇关于Amazon Bedrock ——使用Prompt构建AI软文撰写师的生成式人工智能应用程序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






