本文主要是介绍哔哩哔哩后端Java一面,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
作者:晓宜
个人简介:互联网大厂Java准入职,阿里云专家博主,csdn后端优质创作者,算法爱好者
最近各大公司的春招和实习招聘都开始了,这里分享下去年面试B站的的一些问题,希望对大家有所帮助!
后续会跟新二面的一些问题,感兴趣的同学可以关注我的博客
讲一下AOP
AOP则是针对业务处理过程中的切面进行提取,它所面对的是处理过程的某个步骤或阶段,以获得逻辑过程的中各部分之间低耦合的隔离效果。
具体步骤:
- 将业务逻辑组件和切面类都加入到容器中, 告诉spring哪个是切面类(@Aspect)
- 编写具体的切面类函数,并且添加注解,如around,before,after等
- 在切面类上的每个通知方法上标注通知注解, 告诉Spring要监控哪些类下的哪些方法
- 开启基于注解的AOP模式 @EableXXXX
volatile的使用
1.保证可见性,不保证原子性
(1)当写一个volatile变量时,JMM会把该线程本地内存中的变量强制刷新到主内存中去。
(2)这个写操作会导致其他线程中的volatile变量缓存无效。
2.禁止指令重排
重排序是指编译器和处理器为了优化程序性能而对指令序列进行排序的一种手段,用volatile修饰的共享变量会在读写共享变量时加入不同的屏障,阻止其他读写操作越过屏障,达到阻止成排序的效果。
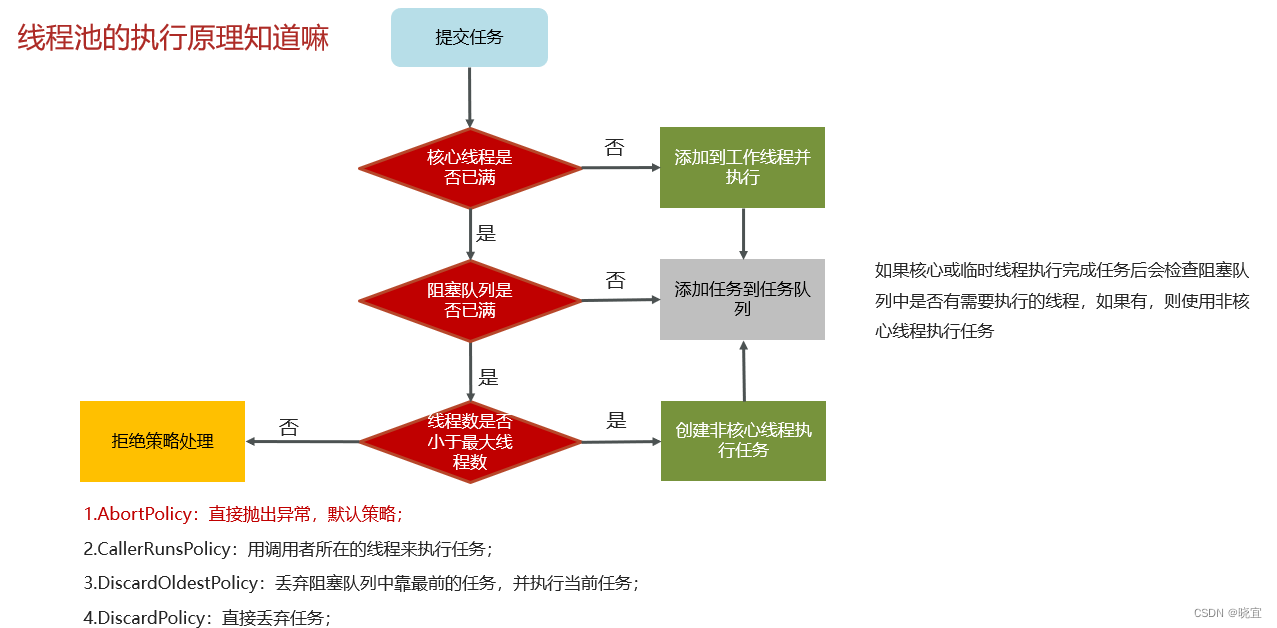
讲一下线程池的参数和流程
线程池的核心参数
- corePoolSize 核心线程数目
- maximumPoolSize 最大线程数目 = (核心线程+救急线程的最大数目)
- keepAliveTime 生存时间 - 救急线程的生存时间,生存时间内没有新任务,此线程资源会释放
- unit 时间单位 - 救急线程的生存时间单位,如秒、毫秒等
- workQueue - 当没有空闲核心线程时,新来任务会加入到此队列排队,队列满会创建救急线程执行任务
- threadFactory 线程工厂 -可以定制线程对象的创建,例如设置线程名字、是否是守护线程等
- handler 拒绝策略 - 当所有线程都在繁忙,workQueue也放满时,会触发拒绝策略
线程池的执行流程
threadlocal的用法
Threadlocal是多线程中对于解决线程安全的一个操作类,它会为每个线程分配一个独立的线程副本用来存储数据,从而防止变量并发访问时的冲突问题。threadlocal同时实现了线程内变量的共享
案例:使用JDBC操作数据库时,会将每一个线程的Connection放入各自的ThreadLocal中,从而保证每个线程都在各自的 Connection 上进行数据库的操作,避免A线程关闭了B线程的连接。
基本使用
- set(v) 设置值
- get() 获取值
- remove() 删除值
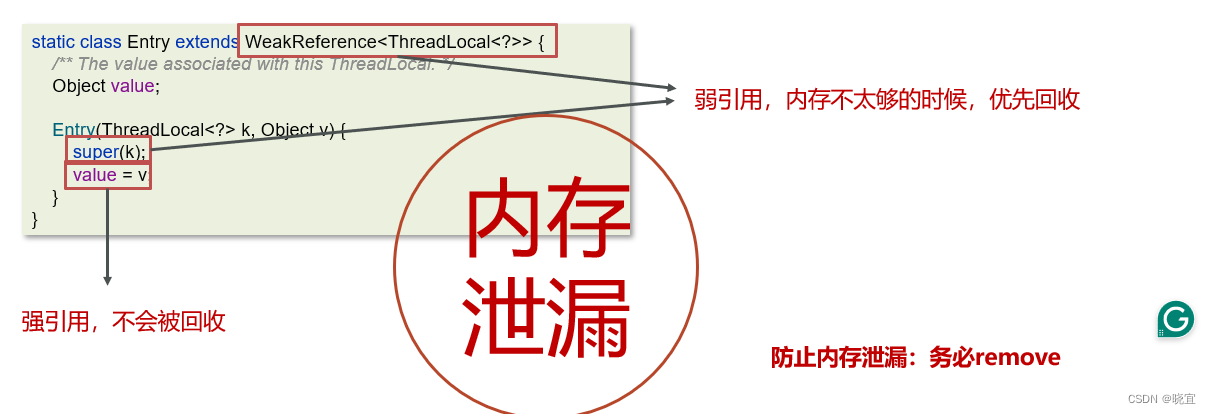
内存泄漏
每一个Thread维护一个ThreadLocalMap,在ThreadLocalMap中的Entry对象继承了WeakReference。其中key为使用弱引用的ThreadLocal实例,value为线程变量的副本
讲一讲你熟悉的Java集合
List:
ArrayList:数组实现的,常用于查询,因为他不需要移动指针,玩的是数据
LinedList: 链表实现的,常用与增删改查,因为他不需要移动数据,玩的是指针
Vectory: 线程安全的,出现问题会抛出异常需要手动捕获(不常用)
Stack:继承自Vector,实现一个后进先出的堆栈(不常用)
Set:
HashSet:哈希表实现的, 数据无序, 可以放一个Null值,存储单列数据
TreeSet:二叉树实现的,数据自动排序,不允许放null值,存储单列数据
Map:
TreeMap: 二叉树实现的,数据有序,HashTable 与 HashMap无序
HashMap:线程不安全,效率快,适用于单线程操作
HashTable:线程安全,因为底层都加了synchronized关键字来确保线程同步,适用于多线程操作
hashmap的底层结构
HashMap的数据结构: 底层使用hash表数据结构,即数组和链表或红黑树
- 当我们往HashMap中put元素时,利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
- 存储时,如果出现hash值相同的key,此时有两种情况。
a. 如果key相同,则覆盖原始值;
b. 如果key不同(出现冲突),则将当前的key-value放入链表或红黑树中 - 获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。

hashmap扩容机制
hashmap的扩容机制是在put()过程中发生的,我们这里介绍下具体的put流程
- 判断键值对数组table是否为空或为null,否则执行resize()进行扩容(初始化)
- 根据键值key计算hash值得到数组索引
- 判断table[i]==null,条件成立,直接新建节点添加
- 如果table[i]==null ,不成立
4.1 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value
4.2 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对
4.3 遍历table[i],链表的尾部插入数据,然后判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操 作,遍历过程中若发现key已经存在直接覆盖value - 插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold(数组长度*0.75),如果超过,进行扩容。
为什么string通常作为hashmap的key
设计 hashCode() 时最重要的因素就是对同一个对象调用 hashCode() 都应该产生相同的值。String 类型的对象对这个条件有着很好的支持,因为 String 对象的 hashCode() 值是根据 String 对象的内容计算的,并不是根据对象的地址计算。
String 对象底层是一个 final 修饰的 char 类型的数组,hashCode() 的计算是根据字符数组的每个元素进行计算的,所以内容相同的 String 对象会产生相同的散列码。
算法题 层序遍历
题目
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
代码
class Solution:def levelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:if not root:return []ans = []cnt = 0queue = []queue.append(root)while queue:n = len(queue)temp = []for i in range(n):node = queue.pop(0)if not node: break# print(node)temp.append(node.val)if node.left: queue.append(node.left)if node.right:queue.append(node.right)ans.append(temp)return ans
算法题 全排列
题目
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
代码
class Solution:def permute(self, nums: List[int]) -> List[List[int]]:n = len(nums)s = set(nums)ans = []path = [0] * ndef dfs(index,s):if index==n:ans.append(path.copy())return for x in s:path[index] = xdfs(index+1,s-{x})dfs(0,s)return ans
这篇关于哔哩哔哩后端Java一面的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









