本文主要是介绍免费阅读篇 | 芒果YOLOv8改进113:注意力机制ShuffleAttention:深度卷积神经网络的随机注意力,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可
该专栏完整目录链接: 芒果YOLOv8深度改进教程
该篇博客为
免费阅读内容,YOLOv8+ShuffleAttention改进内容🚀🚀🚀
文章目录
- 1. ShuffleAttention 论文
- 2. YOLOv8 核心代码改进部分
- 2.1 核心新增代码
- 2.2 修改部分
- 2.3 YOLOv8-SA 网络配置文件
- 2.4 运行代码
- 改进说明
1. ShuffleAttention 论文
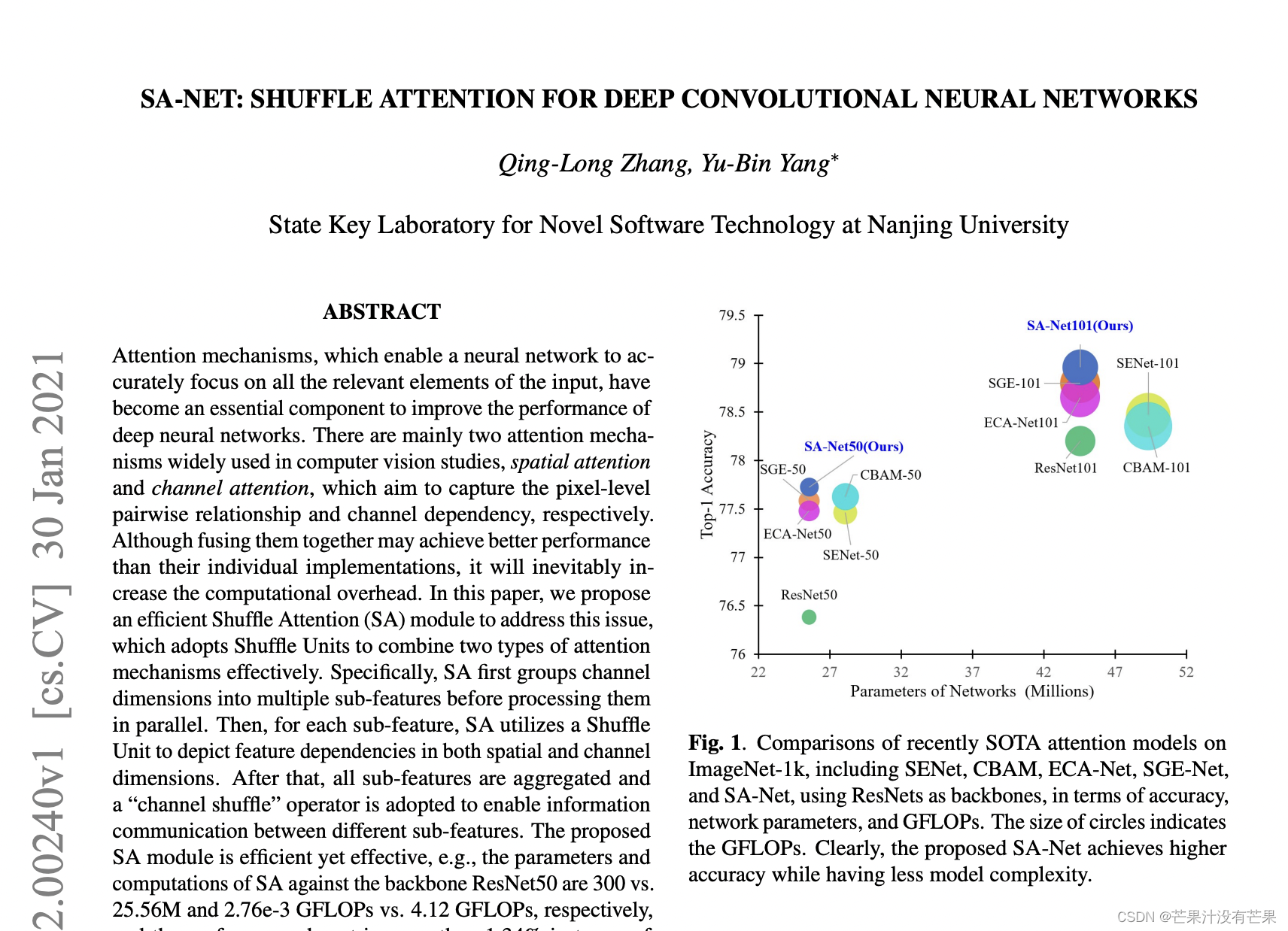
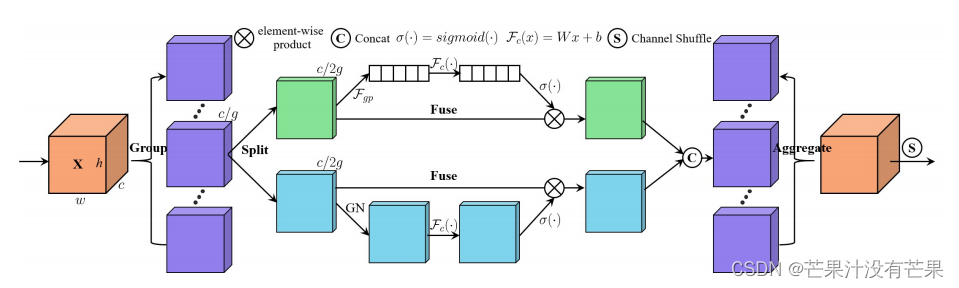
注意力机制使神经网络能够准确地关注输入的所有相关元素,已成为提高深度神经网络性能的重要组成部分。计算机视觉研究中广泛使用的注意力机制主要有两种:空间注意力和通道注意力,其目的分别是捕获像素级的成对关系和通道依赖性。虽然将它们融合在一起可能会比它们单独的实现获得更好的性能,但它不可避免地会增加计算开销。在本文中,我们提出了一种高效的洗牌注意力(SA)模块来解决这个问题,它采用洗牌单元来有效地结合两种类型的注意机制。具体来说,SA 首先将通道维度分组为多个子特征,然后并行处理它们。然后,对于每个子特征,SA 利用洗牌单元来描述空间和通道维度上的特征依赖性。之后,所有子特征被聚合,并采用“通道洗牌”算子来实现不同子特征之间的信息通信。所提出的 SA 模块高效且有效,例如,SA 针对主干 ResNet50 的参数和计算量分别为 300 vs. 25.56M 和 2.76e-3 GFLOPs vs. 4.12 GFLOPs,并且性能提升超过 1.34% Top-1 准确度方面。对常用基准(包括用于分类的 ImageNet-1k、用于对象检测的 MS COCO 和实例分割)的大量实验结果表明,所提出的 SA 通过实现更高的准确度和更低的模型复杂度,显着优于当前的 SOTA 方法
具体细节可以去看原论文:https://arxiv.org/pdf/2102.00240.pdf
2. YOLOv8 核心代码改进部分
2.1 核心新增代码
首先在ultralytics/nn/modules文件夹下,创建一个 sa.py文件,新增以下代码
import numpy as np
import torch
from torch import nn
from torch.nn import init
from torch.nn.parameter import Parameter# https://arxiv.org/pdf/2102.00240.pdf
class ShuffleAttention(nn.Module):def __init__(self, channel=512, out_channel=512, reduction=16,G=8):super().__init__()self.G=Gself.channel=channelself.avg_pool = nn.AdaptiveAvgPool2d(1)self.gn = nn.GroupNorm(channel // (2 * G), channel // (2 * G))self.cweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))self.cbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))self.sweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))self.sbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))self.sigmoid=nn.Sigmoid()def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)@staticmethoddef channel_shuffle(x, groups):b, c, h, w = x.shapex = x.reshape(b, groups, -1, h, w)x = x.permute(0, 2, 1, 3, 4)# flattenx = x.reshape(b, -1, h, w)return xdef forward(self, x):b, c, h, w = x.size()#group into subfeaturesx=x.view(b*self.G,-1,h,w) #bs*G,c//G,h,w#channel_splitx_0,x_1=x.chunk(2,dim=1) #bs*G,c//(2*G),h,w#channel attentionx_channel=self.avg_pool(x_0) #bs*G,c//(2*G),1,1x_channel=self.cweight*x_channel+self.cbias #bs*G,c//(2*G),1,1x_channel=x_0*self.sigmoid(x_channel)#spatial attentionx_spatial=self.gn(x_1) #bs*G,c//(2*G),h,wx_spatial=self.sweight*x_spatial+self.sbias #bs*G,c//(2*G),h,wx_spatial=x_1*self.sigmoid(x_spatial) #bs*G,c//(2*G),h,w# concatenate along channel axisout=torch.cat([x_channel,x_spatial],dim=1) #bs*G,c//G,h,wout=out.contiguous().view(b,-1,h,w)# channel shuffleout = self.channel_shuffle(out, 2)return out
2.2 修改部分
在ultralytics/nn/modules/init.py中导入 定义在 sa.py 里面的模块
from .sa import ShuffleAttention'ShuffleAttention' 加到 __all__ = [...] 里面
第一步:
在ultralytics/nn/tasks.py文件中,新增
from ultralytics.nn.modules import ShuffleAttention
然后在 在tasks.py中配置
找到
elif m is nn.BatchNorm2d:args = [ch[f]]
在这句上面加一个
elif m is ShuffleAttention:c1, c2 = ch[f], args[0]if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)c2 = make_divisible(min(c2, max_channels) * width, 8)args = [c1, c2, *args[1:]]
2.3 YOLOv8-SA 网络配置文件
新增YOLOv8-SA.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 3, ShuffleAttention, [1024]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
2.4 运行代码
直接替换YOLOv8-SA.yaml 进行训练即可
到这里就完成了这篇的改进。
改进说明
这里改进是放在了主干后面,如果想放在改进其他地方,也是可以的。直接新增,然后调整通道,配齐即可,如果有不懂的,可以添加博主联系方式,如下
🥇🥇🥇
添加博主联系方式:
友好的读者可以添加博主QQ: 2434798737, 有空可以回答一些答疑和问题
🚀🚀🚀
参考
https://github.com/ultralytics/ultralytics
这篇关于免费阅读篇 | 芒果YOLOv8改进113:注意力机制ShuffleAttention:深度卷积神经网络的随机注意力的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




