本文主要是介绍【HyperLips:】数字人——控制嘴唇 项目源码python实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

最近受到商汤“复活”汤晓鸥的视频刺激,大大的amazing!没看过的小伙伴可以自行百度,看了不研究一下【数字人】技术,都要跟时代脱轨了,那就以HyperLips为开篇吧。
目录
🍎🍎1.摘要
🍎🍎2.网络结构
🌷🌷2.1输入输出
🌷🌷2.2网络框架
🌷🌷2.3定量比较
🌷🌷2.4用户研究
🌷🌷2.5效果对比
🍎🍎3.源码实现
🌷🌷3.1环境搭建
🌷🌷3.2下载模型
🌷🌷3.3模型推理
🐸原视频
🐸新视频
🌷🌷3.4模型训练
🐸3.4.1训练数据
🐸3.4.2数据预处理
🐸3.4.3训练lipsync
🐸3.4.4训练hyperlips base
🐸3.4.5 生成checkpoints_hyperlips_base视频
🐸3.4.7预处理高分辨率数据
🐸3.4.8训练高分辨率模型
整理不易,欢迎一键三连!!!
送你们一条美丽的--分割线--
项目:project
论文:paper
代码:code
🍎🍎1.摘要
摘要:会说话的面孔生成在虚拟数字人领域具有广泛的潜在应用。 然而,在确保唇形同步的同时渲染高保真面部视频仍然是现有音频驱动的说话人脸生成方法的一个挑战。 为了解决这个问题,我们提出了 HyperLips,这是一个两阶段框架,由用于控制嘴唇的超网络和用于渲染高保真面部的高分辨率解码器组成。 在第一阶段,我们构建一个基础人脸生成网络,该网络使用超网络来控制音频上的视觉人脸信息的编码潜在代码。 首先,FaceEncoder通过提取特征来获得潜在编码,然后,HyperConv(其权重参数由 HyperNet 以音频特征作为输入更新)将修改潜在代码以将嘴唇运动与音频同步。 最后,FaceDecoder 将修改并同步的潜在代码解码为视觉人脸内容。 在第二阶段,我们通过高分辨率解码器获得更高质量的人脸视频。 为了进一步提高面部生成的质量,我们使用第一阶段生成的面部图像和检测到的草图作为输入来训练高分辨率解码器 HRDecoder。 大量的定量和定性实验表明,我们的方法优于最先进的工作,具有更真实、高保真度和唇形同步。
Abstract—Talking face generation has a wide range of potential applications in the field of virtual digital humans. However,rendering high-fidelity facial video while ensuring lip synchronization is still a challenge for existing audio-driven talking face generation approaches. To address this issue, we propose HyperLips, a two-stage framework consisting of a hypernetwork for controlling lips and a high-resolution decoder for rendering high-fidelity faces. In the first stage, we construct a base face generation network that uses the hypernetwork to control the encoding latent code of the visual face information over audio. First,FaceEncoder is used to obtain latent code by extracting features from the visual face information taken from the video source containing the face frame.Then, HyperConv, which weighting parameters are updated by HyperNet with the audio features as input, will modify the latent code to synchronize the lip movement with the audio. Finally, FaceDecoder will decode the modified and synchronized latent code into visual face content. In the second stage, we obtain higher quality face videos through a high-resolution decoder. To further improve the quality of face generation, we trained a high-resolution decoder, HRDecoder, using face images and detected sketches generated from the first stage as input. Extensive quantitative and qualitative experiments show that our method outperforms state-of-the-art work with more realistic, high-fidelity, and lip synchronization.
🍎🍎2.网络结构
🌷🌷2.1输入输出
- 网络输入:视频+音频
- 网络输出:唇形更改后的视频

给定源视频(左上)和驱动音频(右上)的视觉人脸信息,我们的方法能够渲染和生成更真实、高保真和口型同步的视频(下)。查看放大的补丁,我们的方法可以看到牙齿等细节。
🌷🌷2.2网络框架

我们的框架的概述如上所示。我们的目标是在给定音频和视频序列的情况下,通过逐帧在输入视频的下半部分实现被遮挡的面部,生成具有同步嘴唇运动的高保真说话面部视频。我们提出的方法由两个阶段组成:基础脸部生成和高保真度渲染。在基础人脸生成中,我们设计了一个超网络,以音频特征作为输入来控制视觉信息的编码和解码,以获得基础人脸图像。在高保真渲染中,我们使用第一阶段训练的网络中的人脸数据和相应的人脸草图来训练 HRDecoder 网络,以增强基础人脸。
🌷🌷2.3定量比较

表1和表2分别显示了LRS2和MEAD-Neutral数据集的定量比较。结果表明,无论是我们的 HyperLips-Base 还是我们的 HyperLips-HR,生成的人脸在 PSNR、SSIM 和 LMD 指标方面都明显优于其他方法。我们的 HyperLips-HR 在 PSNR 和 SSIM 方面明显优于我们的 HyperLips-Base,这表明我们的 HRDecoder 增强了高保真人脸渲染。然而LMD指数并没有明显的增加,这表明HRDecoder对改善唇同步没有帮助。对于LSE-C和LSE-D,Wav2Lip表现出更好的结果,甚至超越了groundtruth。它只是证明了他们的lip-sync结果与groundtruth几乎相当,而不是更好。虽然LSE-C和LSE-D是我们的方法并不是最好的,但我们在 LMD 指标上表现更好,LMD 指标是另一个同步指标,用于测量视觉域中的对应性。
🌷🌷2.4用户研究
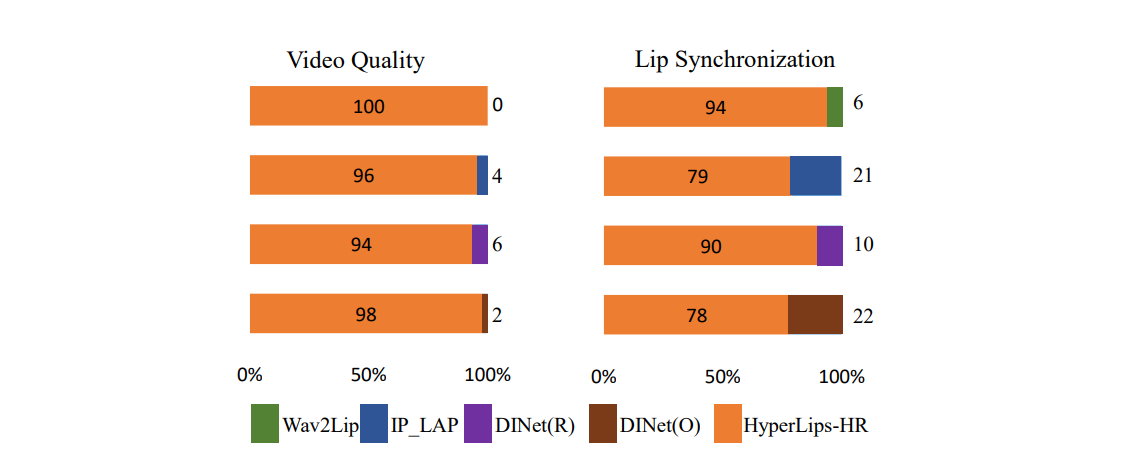
用户研究。可以看出,我们的结果在视频质量和口型同步方面优于其他方法。
🌷🌷2.5效果对比
Visual_Comparison
🍎🍎3.源码实现
🌷🌷3.1环境搭建
Python 3.8.16
torch 1.10.1+cu113
torchvision 0.11.2+cu113
ffmpeg#其他基础库,可以一次性通过一下命令安装
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple🌷🌷3.2下载模型
模型下载链接:百度网盘

并将下载好的模型文件放置./checkpoints/ 目录下。
🌷🌷3.3模型推理
首先修改inference.py文件,修改你要输入的原始视频文件路径和新的语音文件路径。inference.py如下所示。
from HYPERLIPS import Hyperlips
import argparse
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '1'parser = argparse.ArgumentParser(description='Inference code to lip-sync videos in the wild using HyperLipsBase or HyperLipsHR models')
parser.add_argument('--checkpoint_path_BASE', type=str,help='Name of saved HyperLipsBase checkpoint to load weights from', default="checkpoints/hyperlipsbase_multi.pth")
parser.add_argument('--checkpoint_path_HR', type=str,help='Name of saved HyperLipsHR checkpoint to load weights from', default=None)#"checkpoints/hyperlipshr_mead_128.pth"
parser.add_argument('--face', type=str,help='Filepath of video/image that contains faces to use', default="test/video2/video2.mp4")
parser.add_argument('--audio', type=str,help='Filepath of video/audio file to use as raw audio source', default="test/video2/obam-english.wav")
parser.add_argument('--outfile', type=str, help='Video path to save result. See default for an e.g.',default='result/result_video2-obma-en.mp4')
parser.add_argument('--pads', nargs='+', type=int, default=[0, 10, 0, 0],help='Padding (top, bottom, left, right). Please adjust to include chin at least')
parser.add_argument('--filter_window', default=None, type=int,help='real window is 2*T+1')
parser.add_argument('--hyper_batch_size', type=int, help='Batch size for hyperlips model(s)', default=128)
parser.add_argument('--resize_factor', default=1, type=int,help='Reduce the resolution by this factor. Sometimes, best results are obtained at 480p or 720p')
parser.add_argument('--img_size', default=128, type=int)
parser.add_argument('--segmentation_path', type=str,help='Name of saved checkpoint of segmentation network', default="checkpoints/face_segmentation.pth")
parser.add_argument('--face_enhancement_path', type=str,help='Name of saved checkpoint of segmentation network', default="checkpoints/GFPGANv1.3.pth")#"checkpoints/GFPGANv1.3.pth"
parser.add_argument('--no_faceenhance', default=False, action='store_true',help='Prevent using face enhancement')
parser.add_argument('--gpu_id', type=float, help='gpu id (default: 0)',default=0, required=False)
args = parser.parse_args()def inference_single():Hyperlips_executor = Hyperlips(checkpoint_path_BASE=args.checkpoint_path_BASE,checkpoint_path_HR=args.checkpoint_path_HR,segmentation_path=args.segmentation_path,face_enhancement_path = args.face_enhancement_path,gpu_id = args.gpu_id,window =args.filter_window,hyper_batch_size=args.hyper_batch_size,img_size = args.img_size,resize_factor = args.resize_factor,pad = args.pads)Hyperlips_executor._HyperlipsLoadModels()Hyperlips_executor._HyperlipsInference(args.face,args.audio,args.outfile)if __name__ == '__main__':inference_single()
-
checkpoint_path_BASE:基础模型地址
-
checkpoint_path_HR:高分辨率模型地址
-
face:源视频地址,目前支持MP4格式
-
audio:源音频地址,目前支持WAV格式
-
outfile:输出视频地址
其他参数保持默认即可,包括面部增强模型地址、面部分割模型地址等。
举例,让原视频的奥巴马说出以下音频,音频内容如下:
Hello everyone, I am Obama and my wish is world peace
这样,将这个新音频和源奥巴马的视频作为输入,输出选择一个新的MP4地址即可开始进行模型预测推理了。
推理成功:


🐸原视频
🐸新视频
目前试用的效果中,英文语音比中文语音的模拟效果好很多,可能训练样本大多是英文的吧,但是英文语音模拟出来的后半段,口型变化不是很大的情况下,视频看起来还是有点假的,感兴趣的小伙伴可以自己多做几组语音,对比一下。
🌷🌷3.4模型训练
🐸3.4.1训练数据
本项目使用的是MEAD数据集,下载地址在MEAD数据集。

可以看到,视频的来源主要是BBC频道和TED演讲视频,这也就不难理解,中文模拟效果不好的了。

下载后的数据组织格式为:
data_root (datasets)
├── name of dataset(MEAD)
| ├── videos ending with(.mp4)🐸3.4.2数据预处理
从视频文件中提取人脸图像和原始音频,并生成文件列表,通过运行以下命令获取 train.txt 和 val.txt:
命令:
python preprocess.py --origin_data_root=datasets/MEAD --clip_flag=0 --Function=base --hyperlips_train_dataset=Train_data🐸3.4.3训练lipsync
数据准备好之后,就可以进行模型训练了,首先训练lipsync,命令如下:
python color_syncnet_trainv3.py --data_root=Train_data/imgs --checkpoint_dir=checkpoints_lipsync_expert注意:预训练模型pretrain_sync_expert.pth要提前存放于./checkpoints目录下。
🐸3.4.4训练hyperlips base
训练hyperlips base模型的命令如下:
python Train_hyperlipsBase.py --data_root=Train_data/imgs --checkpoint_dir=checkpoints_hyperlips_base --syncnet_checkpoint_path=checkpoints/pretrain_sync_expert.pth同样,预训练模型pretrain_sync_expert.pth要提前存放于./checkpoints目录下。
🐸3.4.5 生成checkpoints_hyperlips_base视频
基于训练的checkpoints_hyperlips_base模型,进行视频推理生成,命令如下:
python Gen_hyperlipsbase_videos.py --checkpoint_path_BASE=checkpoints_hyperlips_base/xxxxxxxxx.pth --video=datasets --outfile=hyperlips_base_results🐸3.4.7预处理高分辨率数据
从原始视频中提取图像、草图和唇部蒙版,并通过运行以下命令从 hyperlips 基础视频生成的视频中提取图像和草图,与之前不同的是,这次提取的信息更细节了。
命令如下:
python preprocess.py --origin_data_root=datasets/MEAD --Function=HR --hyperlips_train_dataset=Train_data --hyperlipsbase_video_root=hyperlips_base_results 🐸3.4.8训练高分辨率模型
基于高分辨率面部、唇部等高分辨率信息,其中img_size的尺寸可以自由调整为256或512。
python Train_hyperlipsHR.py -hyperlips_trian_dataset=Train_data/HR_Train_Dateset --checkpoint_dir=checkpoints_hyperlips_HR --batch_size=28 --img_size=128至此就大功告成了!
HyperLips工程整体还是比较完整和规范的,复现起来也比较友好,有问题欢迎评论区交流,本人尝试复现了其他几个数字人的工程,一言难尽啊。。。
整理不易,欢迎一键三连!!!
送你们一条美丽的--分割线--
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷🌷
这篇关于【HyperLips:】数字人——控制嘴唇 项目源码python实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








