本文主要是介绍基于FatFs文件系统操作MX25L25635 应用于STM32L152单片机上,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第一次做低功耗项目,所以选用了这块STM32L1系列单片机。感觉它在低功耗上面确实很不错,不过牺牲了高主频的条件,嗯那也是情理之中,不可能主频又高功耗又低是吧。项目需要储存数据,那时第一个会想到SD卡,于是选择贴片式的SD卡(国内有代理),然而第一版硬件调试过程中发现3.4V供电 电流达到50ms,我想这样不行功耗那么高,于是一部分一部分去除,后来发现这个贴片式的SD卡静态下也需要大概40ms左右,我晕!于是开始改用MX25L25635,这个静态2ms左右,但是写的读话比较高(60ms以上)不过考虑到数据操作的不怎么频繁,也就是瞬态功耗。调试这块东西挺坎坷的,好多是第一次那么细操作去调试,因为之前直接上正点原子代码就可以了。
好了不说废话,芯片参考文档 https://pdf1.alldatasheet.com/datasheet-pdf/view/575659/MCNIX/MX25L25635FMI10G.html
简单
总结下该芯片:
1、芯片接口支持传统SPI(模式0和模式3 单线读写) ,QSPI(2线/4线读写,这个STM32就有这个接口)
2、芯片默认3字节地址命令,就是通讯时候写入一字节命令后在写三字节就是指定地址,这样就有24bits,可以寻址到芯片一半的空间(总空间256Mb=32M字节,一半就是16M字节),想全部使用的话还是使用四字节地址模式。
3、操作每一个命令都要先CS拉低完成拉高,这个你肯定会觉得那肯定啦!然而当你一个操作里面有几个命令的话呢?
4、芯片不像W25Q那样有三个状态寄存器,它只有一个。
5、写使能命令后不需要专门等待,写完成!只需要写命令后需要等待。
6、芯片只能内部只能写0,写1要擦除,也就是说你写的前提要保证写的那段空间都是0xFF,不然就需要擦除哦。
好了先调试芯片读写。本人用的是模式SPI单线的。
//默认3字节地址不需要寄存器初始化直接读出是否合理就可以了
printf("\n0x%08x\n", MX25L256_ID());
printf("\n0x%02x\n", MX25L256_ReadSR(MX25L_ReadStatusReg1));
printf("\n0x%02x\n", MX25L256_ReadSR(MX25L_ReadStatusReg3));/**
* 向Flash写入一字节数据
**/
void MX25L256_Write_Byte(u8 data)
{ u8 i;SCK_H;__NOP(); for( i=0;i<8;i++){ if(data&0x80) {MOSI_H; /*若最高位为高,则输出高*/}else{MOSI_L; /*若最高位为低,则输出低*/ } __NOP();data <<= 1;SCK_L;__NOP();SCK_H;} MOSI_H;
}
/**
* 读取Flash一字节数据
**/
u8 MX25L256_Read_Byte(void)
{u8 i ,data=0;SCK_H;__NOP();for( i=0;i<8;i++){SCK_L;__NOP();SCK_H;data <<= 1; /*数据左移*/if(MISO){data++; /*若从从机接收到高电平,数据自加一*/}__NOP();}return data;
}/**
*读取SPI FLASH
*在指定地址开始读取指定长度的数据
*pBuffer:数据存储区
*ReadAddr:开始读取的地址(最大32bit)
*NumByteToRead:要读取的字节数(最大65535)
**/
void MX25L256_Read(u8* pBuffer,u32 ReadAddr,u32 NumByteToRead)
{ u32 i;NSS_L;MX25L256_Write_Byte(MX25L_ReadData);MX25L256_Write_Byte((u8)(ReadAddr>>16));MX25L256_Write_Byte((u8)(ReadAddr>>8));MX25L256_Write_Byte((u8)ReadAddr);for( i=0;i<NumByteToRead;i++){pBuffer[i]=MX25L256_Read_Byte();}NSS_H;//printf("读完成!\r\n");
} /**
*SPI在一页(0~65535)内写入少于256个字节的数据
*在指定地址开始写入最大256字节的数据
*pBuffer:数据存储区
*WriteAddr:开始写入的地址(最大32bit)
*NumByteToWrite:要写入的字节数(最大256),该数不应该超过该页的剩余字节数!!!
**/
void MX25L256_Write_Page(u8* pBuffer,u32 WriteAddr,u32 NumByteToWrite)
{u32 i;u8 data;MX25L256_Write_Enable();NSS_L;MX25L256_Write_Byte(MX25L_PageProgram);MX25L256_Write_Byte((u8)(WriteAddr>>16));MX25L256_Write_Byte((u8)(WriteAddr>>8));MX25L256_Write_Byte((u8)WriteAddr);for( i=0;i<NumByteToWrite;i++){MX25L256_Write_Byte(pBuffer[i]);}NSS_H;while((MX25L256_ReadSR(MX25L_ReadStatusReg1)&0x01)==0x01);//等待写完成
} 恩核心的东西就这些,操作就可以了,命令的宏定义去看文档写的好清楚或者参看正点原子的W25Q256代码,命令操作是兼容的。
然后是挂载FatFs,之前用过正点原子SD卡挂载以为好简单,在CubeMX自动生成以为就可以。没想到。。。。
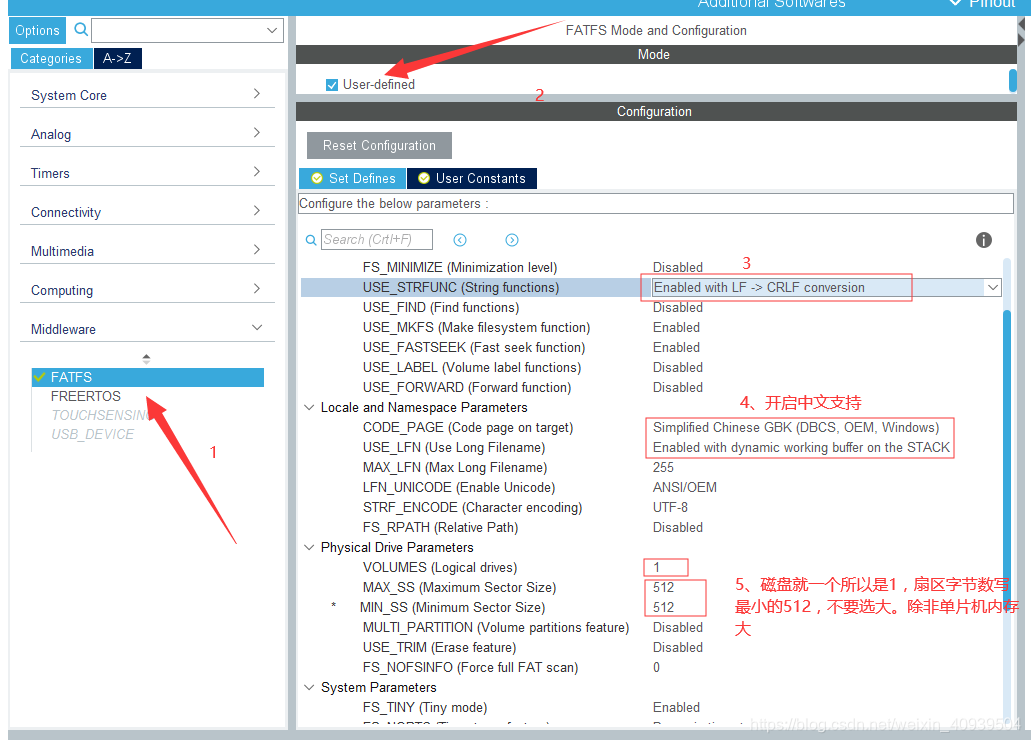
自动生成代码,在user_diskio.c 加入操作flash的驱动函数。
/*** @brief Initializes a Drive* @param pdrv: Physical drive number (0..)* @retval DSTATUS: Operation status*/
DSTATUS USER_initialize (BYTE pdrv /* Physical drive nmuber to identify the drive */
)
{/* USER CODE BEGIN INIT */Stat = STA_NOINIT;MX25L256_Init();//return Stat;return ~Stat;/* USER CODE END INIT */
}/*** @brief Gets Disk Status * @param pdrv: Physical drive number (0..)* @retval DSTATUS: Operation status*/
DSTATUS USER_status (BYTE pdrv /* Physical drive number to identify the drive */
)
{/* USER CODE BEGIN STATUS *///Stat = STA_NOINIT;//return Stat;return RES_OK;/* USER CODE END STATUS */
}/*** @brief Reads Sector(s) * @param pdrv: Physical drive number (0..)* @param *buff: Data buffer to store read data* @param sector: Sector address (LBA)* @param count: Number of sectors to read (1..128)* @retval DRESULT: Operation result*/
DRESULT USER_read (BYTE pdrv, /* Physical drive nmuber to identify the drive */BYTE *buff, /* Data buffer to store read data */DWORD sector, /* Sector address in LBA */UINT count /* Number of sectors to read */
)
{/* USER CODE BEGIN READ */for(;count>0;count--){MX25L256_Read(buff,sector*SPI_FLASH_SECTOR_SIZE,SPI_FLASH_SECTOR_SIZE);sector++;buff+=SPI_FLASH_SECTOR_SIZE;}return RES_OK;/* USER CODE END READ */
}/*** @brief Writes Sector(s) * @param pdrv: Physical drive number (0..)* @param *buff: Data to be written* @param sector: Sector address (LBA)* @param count: Number of sectors to write (1..128)* @retval DRESULT: Operation result*/
#if _USE_WRITE == 1
DRESULT USER_write (BYTE pdrv, /* Physical drive nmuber to identify the drive */const BYTE *buff, /* Data to be written */DWORD sector, /* Sector address in LBA */UINT count /* Number of sectors to write */
)
{ /* USER CODE BEGIN WRITE *//* USER CODE HERE */for(;count>0;count--){ MX25L256_Write((u8*)buff,sector*SPI_FLASH_SECTOR_SIZE,SPI_FLASH_SECTOR_SIZE);//MX25L256_Write_Page((u8*)buff,sector*SPI_FLASH_SECTOR_SIZE,SPI_FLASH_SECTOR_SIZE);sector++;buff+=SPI_FLASH_SECTOR_SIZE;}return RES_OK;/* USER CODE END WRITE */
}
#endif /* _USE_WRITE == 1 *//*** @brief I/O control operation * @param pdrv: Physical drive number (0..)* @param cmd: Control code* @param *buff: Buffer to send/receive control data* @retval DRESULT: Operation result*/
#if _USE_IOCTL == 1
DRESULT USER_ioctl (BYTE pdrv, /* Physical drive nmuber (0..) */BYTE cmd, /* Control code */void *buff /* Buffer to send/receive control data */
)
{/* USER CODE BEGIN IOCTL */DRESULT res = RES_ERROR;switch(cmd){case CTRL_SYNC:res = RES_OK; break; case GET_SECTOR_SIZE:*(WORD*)buff = SPI_FLASH_SECTOR_SIZE;res = RES_OK;break; case GET_BLOCK_SIZE:*(WORD*)buff = SPI_FLASH_BLOCK_SIZE;res = RES_OK;break; case GET_SECTOR_COUNT:*(DWORD*)buff = SPI_FLASH_SECTOR_COUNT;res = RES_OK;break;default:res = RES_PARERR;break;}return res;/* USER CODE END IOCTL */
}[点击并拖拽以移动]
文件前面宏定义扇区和块数目。
主函数,注意flash一开始是没有文件系统的,所以第一次挂载是返回FR_NO_FILESYSTEM,然后就让它重刷整个盘,在自己制作文件系统写入对应的位置就好了。f_mkfs("0:", 0, 0);这个过程需要好久哦,因为主频本来就低还有是单总线的写入,同时芯片自身正片刷0xFF需要一分多钟。
MX_FATFS_Init();res = f_mount(&fs, "0:", 1); /* Mount a logical drive */res = f_mkfs("0:", 0, 0);if(res != FR_OK){if(res == FR_NO_FILESYSTEM){printf("f_mount 没有文件系统,开始格式化spi-flash\r\n");res = f_mkfs("0:", 0, 0);printf("SD卡成功格式化!\r\n");//格式化后先取消挂载res = f_mount(NULL, "0:", 1);//再重新挂载res = f_mount(&fs, "0:", 1);if(res != FR_OK){printf("f_mkfs 格式化失败,err = %d\r\n", res);while(1);}else{printf("格式化成功,开始重新挂载spi-flash\r\n");res = f_mount(&fs, "0:", 1);if(res != FR_OK){printf("f_mount 发生错误,err = %d\r\n", res);}else printf("spi-flash文件系统挂载成功\r\n");}}else{printf("f_mount 发生其他错误,err = %d\r\n", res);while(1);}}else printf("spi-flash文件系统挂载成功\r\n");可以接下来读操作下(文件没有的话自己创建,读是从起始位置读):
res=f_open(&file,"0:hello.txt",FA_OPEN_ALWAYS|FA_READ);if(res==FR_OK){f_lseek(&file,0);res = f_read (&file, ReadBuffer, 50, &Br);if(res == FR_OK) {printf("%s",ReadBuffer);printf("读取成功=%d",res);}else{printf("读取失败=%d",res);}f_close(&file); //记得一定要关闭文件}else{printf("\n打开文件失败!错误代码:%02x \n",res);}memset(ReadBuffer,0,100);写入操作
res=f_open(&file,"0:hello.txt",FA_OPEN_ALWAYS|FA_WRITE);if(res==FR_OK){f_lseek(&file,f_size(&file));res = f_write (&file, USART_RX_BUF1, USART_RX_STA1, &Bw);if(res == FR_OK) {printf("\n写入完毕!\n");}else{printf("写入失败=%d",res);}f_close(&file); //记得一定要关闭文件}else{ printf("\n打开文件失败! 错误代码:%02x \n",res);}好了基本上这样。然而上述虽然可以成功,但是他的速度真的慢啊,因为我单片机主频是1.5Mhz,本来不用文件系统读还算接受的了,用了直接无语了。所以后期改用四线QSPI模式,不使用文件系统操作,项目只需写入基本数据,读出来就可以了。这个过程也让我了解到开发文件系统和flash一些要点。
过程中问题:
1、不使能 FS_Tiny的话会编译出现没空间的错误。
2、改栈空间大小如下,因为文件系统好多局部数组比较大的。

3、定义FATFS fs; FIL file; 需要在全局中。
4、flash读出数据不正确考虑下模拟时序,他是时钟下降沿数据有效。
好了看看输出过程


这篇关于基于FatFs文件系统操作MX25L25635 应用于STM32L152单片机上的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





