本文主要是介绍【PRIVGUARD-privguard-artifact-main】代码学习(parser部分),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
privguard-artifact-main:parser部分简述
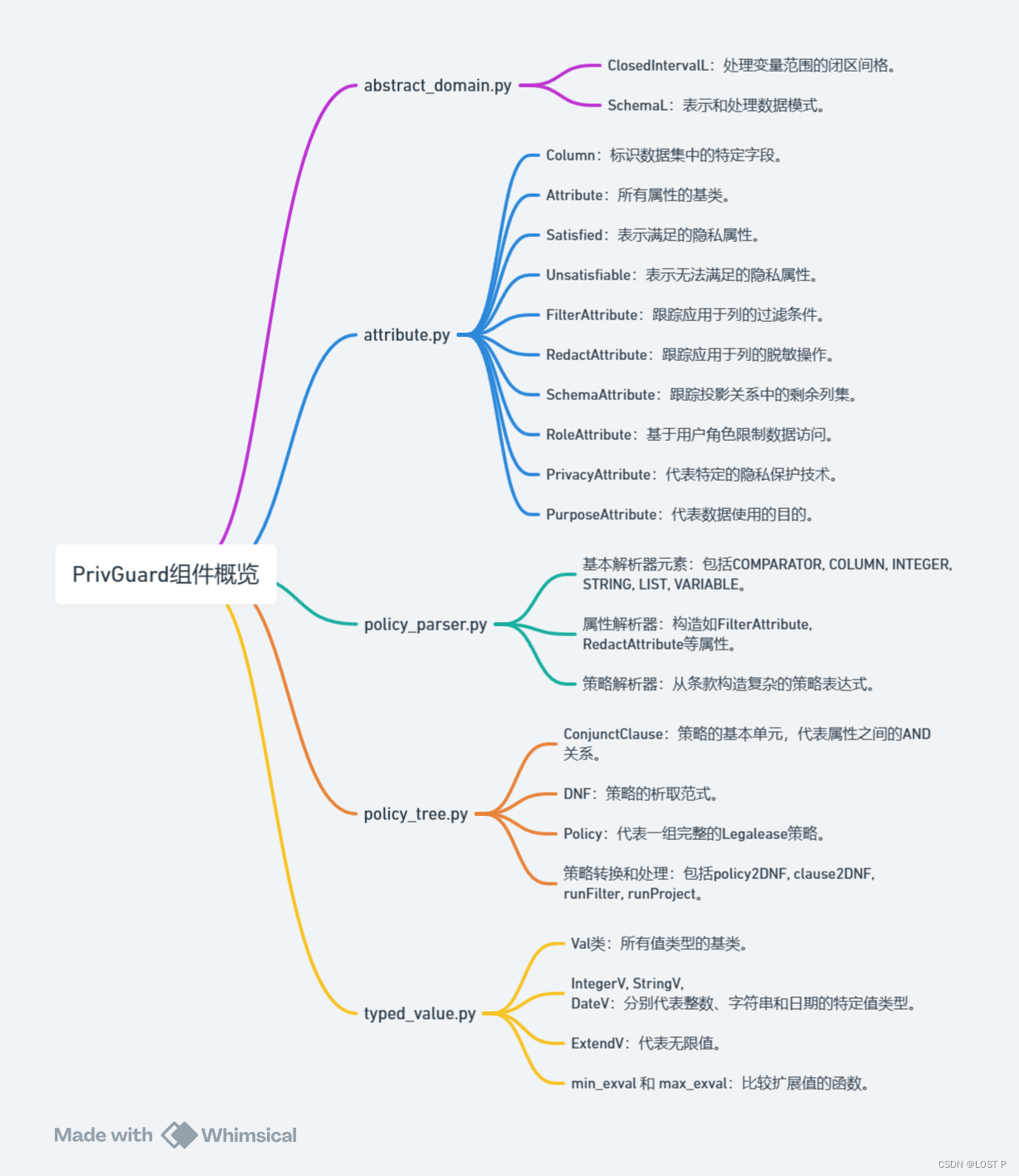
1.abstract_domain.py
(1)简介
实现PrivGuard中的抽象域功能。PrivGuard是一个旨在确保Python程序符合特定隐私策略的工具。代码中定义了两种类型的抽象域:闭区间格(ClosedIntervalL)和模式格(SchemaL)。
-
闭区间格(ClosedIntervalL):这部分代码定义了一个处理扩展值闭区间的格结构。闭区间格用于表示变量的值范围,例如,一个整数变量可以在1到10之间取值。该格提供了判断子集、计算并集和交集等操作,这对于分析变量值的可能范围以及它们如何影响程序中的隐私策略至关重要。
-
模式格(SchemaL):模式格用于表示和处理数据模式,如数据表或数据集的列结构。它通过一组列名来定义模式,并提供了判断子集、并集和交集的功能。这对于分析数据集如何满足特定的隐私策略是必要的,特别是在处理涉及多个数据源和数据结构的复杂数据处理任务时。
当然可以。让我们通过具体的例子来解释上述代码的作用:
(2)示例
i.闭区间格(ClosedIntervalL)示例
假设我们正在处理一个医疗数据集,我们有一个名为“年龄”的字段,我们希望确保分析仅涉及年龄在18至65岁之间的个体,以符合某些隐私规定。在这种情况下,我们可以使用闭区间格(ClosedIntervalL)来表示这个年龄范围:
from typed_value import ExtendV# 创建年龄范围为18至65的闭区间格实例
age_interval = ClosedIntervalL(ExtendV(18), ExtendV(65))
在这个例子中,ExtendV(18)和ExtendV(65)定义了闭区间的下限和上限,表示允许的年龄范围。在数据分析或数据处理过程中,我们可以使用这个闭区间格来检查某个数据集或数据处理操作是否仅包括这个年龄范围内的个体。
ii.模式格(SchemaL)示例
假设我们有一个关于银行客户的数据集,包含客户的姓名、年龄、账户余额等信息。为了遵守隐私政策,我们可能只允许数据分析任务使用年龄和账户余额字段,而不使用姓名字段。在这种情况下,我们可以使用模式格(SchemaL)来表示允许的数据模式:
# 创建一个仅包含“年龄”和“账户余额”的模式格实例
allowed_schema = SchemaL(['年龄', '账户余额'])
在这个例子中,模式格allowed_schema表示了一个仅包含“年龄”和“账户余额”字段的数据结构。通过将数据集与此模式格进行比较,我们可以检查数据集是否符合隐私政策的要求,即不包含不应该使用的敏感信息,如客户的姓名。
2.attribute.py
attribute.py用于描述和处理数据隐私保护策略中的不同属性。PrivGuard旨在帮助确保数据处理程序遵守特定的隐私政策。代码中定义的各种属性类代表数据可以拥有的不同特征和要求,这些特征和要求需要在数据处理和分析中得到满足和尊重。
(1)主要类和作用:
| 编号 | 类别 | 描述 |
|---|---|---|
| 1 | Column | 表示数据库或数据集中的一列,用于识别数据集的特定字段。 |
| 2 | Attribute | 所有属性类的基类,定义属性的基本接口和行为。 |
| 3 | Satisfied | 表示一个已经满足的属性,意味着不需要额外的操作来满足这个属性相关的隐私策略要求。 |
| 4 | Unsatisfiable | 表示一个无法满足的属性,意味着不存在任何方法可以使数据满足这个属性相关的隐私策略要求。 |
| 5 | FilterAttribute | 表示数据过滤条件,用于追踪程序中对特定列应用的过滤条件。 |
| 6 | RedactAttribute | 表示数据脱敏操作,用于追踪对特定列应用的脱敏(或红action)操作。 |
| 7 | SchemaAttribute | 表示数据架构或结构属性,用于追踪投影关系中剩余的列集。 |
| 8 | RoleAttribute | 表示数据访问者的角色属性,用于限制数据的访问和使用。 |
| 9 | PrivacyAttribute | 表示应用于数据的特定隐私保护技术,如k匿名、l多样性、t接近性或差分隐私(DP)。 |
| 10 | PurposeAttribute | 表示数据使用的目的属性,说明数据将如何被使用,还在构建中。 |
(2)例子:
-
FilterAttribute:
假设有一个数据库表格,其中有一列名为"age",现在想要过滤出所有年龄大于18的记录。在这种情况下,你可以使用FilterAttribute来表示这个过滤条件:age_column = Column('age') age_filter = FilterAttribute(age_column, Interval(18, None)) # 假设Interval是一个表示数值范围的类 -
RedactAttribute:
假设在处理个人信息时,需要隐藏每个人名字的一部分以保护隐私。可以使用RedactAttribute来标记这个操作:name_column = Column('name') name_redact = RedactAttribute(name_column, slice_(1, None)) # 假设从第二个字符开始隐藏 -
PrivacyAttribute(隐私属性):
如果你的数据处理任务需要应用差分隐私技术来保护数据,你可以这样表示:dp_privacy = PrivacyAttribute('DP', eps=1.0, delta=1e-5) # 应用ε=1.0, δ=1e-5的差分隐私
3.policy_parser.py
使用Python和pyparsing库编写的Legalease策略解析器。Legalease是一种专门用于定义数据处理和隐私策略的语言。在这个框架中,策略通常用于规定哪些数据字段需要进行过滤、脱敏、保持特定模式、遵守隐私标准、限制特定角色的访问权限、或者符合特定用途。
(1)主要组件及其功能:
i.基本解析器元素
| 元素 | 描述 |
|---|---|
| COMPARATOR | 解析比较运算符,如’==', ‘!=’, ‘>’, ‘>=’, ‘<’, ‘<=’。用于条件表达式中比较列值。 |
| COLUMN | 解析数据中的列名,用于确定需要过滤或脱敏的列。 |
| INTEGER | 解析整数值,用于条件表达式中的比较,如年龄或薪水等数值条件。 |
| STRING | 解析字符串值,用于需要比较字符串的策略中,如用户角色或数据类别。 |
| LIST | 解析逗号分隔的列名列表,指定策略适用的多个数据列。 |
| VARIABLE | 解析一般的变量名,用于指定角色或目的属性。 |
ii.属性解析器
| 属性 | 描述 |
|---|---|
| FilterAttribute | 根据策略条件构造表示数据过滤需求的属性,例如基于年龄或薪水的过滤。 |
| RedactAttribute | 创建表示脱敏需求的属性,指示隐藏或替换输出数据中的某些信息,例如姓名的一部分。 |
| SchemaAttribute | 解析数据模式要求,指定策略中提及的数据列应如何保持。 |
| PrivacyAttribute | 表示数据应遵守的隐私保护技术,如k匿名性、差分隐私等。 |
| RoleAttribute | 解析用户角色的要求,确定哪些角色可以访问数据。 |
| PurposeAttribute | 解析数据用途的规定,指定数据可以用于何种目的。 |
iii.策略解析器
- 使用上述定义的属性解析器构建更复杂的策略表达式。策略由一个或多个条款组成,每个条款定义了一组属性和条件。
- CLAUSE: 代表了策略中的一个允许条款,使用逻辑操作符(如AND、OR)连接不同的属性。
- policy_parser: 最终的策略解析器,它使用所有上述组件来解析完整的Legalease策略字符串,并将其转换成可用于策略评估的内部表示形式。
(2)示例:
假设有以下Legalease策略字符串:“ALLOW FILTER age >= 18 AND SCHEMA name, email”。这个策略的含义是:
- 使用FILTER_ATTRIBUTE解析器解析"FILTER age >= 18",结果是一个过滤属性,表示只允许年龄大于或等于18岁的记录。
- 使用SCHEMA_ATTRIBUTE解析器解析"SCHEMA name, email",结果是一个模式属性,表示数据输出应仅包含"name"和"email"两列。
- CLAUSE将这两个属性组合在一起,使用AND逻辑,表示两个条件都必须满足。
- policy_parser将整个字符串解析为一个或多个这样的策略条款。
4.policy_tree.py
定义了Legalease策略的语法树表示和处理方法。代码片段主要涉及几个部分:策略的内部表示、策略转换为析取范式(DNF),以及根据数据处理操作对策略进行更新的方法。
(1)主要组件及其功能:
-
ConjunctClause(合取子句):
-
这是构成策略的基本单元,表示一组属性的逻辑“与”(AND)关系。
-
例如,一个合取子句
ConjunctClause([FilterAttribute('age', ClosedIntervalL(18, None)), SchemaAttribute(['name'])])表示“年龄大于等于18并且只包含姓名字段”。
-
-
DNF(析取范式):
-
表示整个策略,策略由一系列合取子句以逻辑“或”(OR)关系连接组成。
-
例如,
DNF([ConjunctClause([...]), ConjunctClause([...])])可以表示两种不同的数据处理要求组合。
-
-
Policy(策略):
- 表示一组完整的Legalease策略,提供了一种将策略字符串转换成程序可以理解和操作的形式的方式。
- 包含用于处理和修改策略的方法,如过滤操作、投影操作(限定列)等。
- 初始化时可以从字符串、已有的条款列表或DNF形式创建。
(2)策略转换和处理方法:
-
策略转换(policy2DNF & clause2DNF):
clause2DNF和policy2DNF函数将Legalease策略从其原始或嵌套列表形式转换为更结构化和标准化的析取范式(DNF)。- 这种转换是处理和应用策略的基础,因为DNF形式容易与程序执行的具体数据操作相结合。
- 例如,策略“ALLOW FILTER age >= 18 OR FILTER income > 5000”将被分解成两个合取子句。
-
策略更新方法(runFilter, runProject等):
- 这些方法根据数据操作动态更新策略。例如:
runFilter(col, val, op)根据过滤条件更新策略,如只保留满足特定条件的记录。runProject(cols)根据投影操作更新策略,确保只有指定的列被保留。
- 这些方法通过考虑操作的效果来调整策略,去除因操作已满足而变得不必要的策略要求,或添加新的要求以确保策略的一致性和完整性。
- 例如,如果策略要求“年龄必须大于18”,而程序过滤出所有年龄大于20的记录,那么这个策略要求已被满足,因此可以更新为一个空操作(或视为满足)。
- 这些方法根据数据操作动态更新策略。例如:
示例:
假设Legalease策略:
policy_str = "ALLOW FILTER age >= 18 AND (SCHEMA age OR (FILTER gender == 'M' AND (ROLE MANAGER OR FILTER age <= 90)))"
此策略表示允许数据记录,如果用户的年龄大于等于18岁,并且符合以下条件之一:只包含年龄字段、性别为男性并且是管理者角色或年龄不超过90岁。
通过以下代码初始化一个Policy对象,并且打印其内部表示:
policy = Policy(policy_str)
print(policy)
若执行过滤操作,只留下年龄大于等于18岁的记录,可以使用以下代码:
print(policy.runFilter('age', 18, 'ge'))
这会更新策略,以反映过滤操作的结果。
通过这些方法,可以使得策略动态地适应数据处理操作的变化,帮助确保数据处理过程遵守初设的隐私保护规则。
5.typed_value.py
定义了PrivGuard策略中支持的数据类型,以及对这些数据类型进行操作的函数和类。这些数据类型和操作是处理和评估Legalease策略中的条件和规则的基础。
(1)主要组件及其功能
i.Val类
- 通用值的基类,用于PrivGuard策略中的所有值类型。它定义了基本值(如整数、字符串、日期等)共有的比较方法(小于、等于、大于等),使得不同类型的值可以在策略评估时进行比较和逻辑判断。
- 功能:
- 提供了标准的比较运算符方法(
__lt__,__le__,__eq__,__ne__,__ge__,__gt__),允许值之间进行比较。 - 通过重载这些方法,任何继承自
Val的子类可以用于比较运算。
- 提供了标准的比较运算符方法(
ii.IntegerV类
- 这是Val类的子类,代表整数值。这使得策略中可以包含和处理整数值,例如年龄、计数等。
- 功能:
- 继承了Val类的所有方法,并增加了特定于整数的操作,如加法(
__add__)和减法(__sub__)。 - 通过这些操作,可以构建表示范围、条件或对整数值的数学运算的策略表达式。
- 继承了Val类的所有方法,并增加了特定于整数的操作,如加法(
iii.StringV类
- 继承自Val类,表示字符串值。用于处理策略中的文本内容,如姓名、地址等。
- 功能:
- 与IntegerV类似,它继承了Val类的比较方法,但专用于字符串类型的值。
- 在策略中使用StringV类可以对字符串值进行逻辑和条件判断。
iv.DateV类
- 代表日期值,也是Val类的一个子类。它使策略可以处理和评估基于日期的条件,例如出生日期、事务日期等。
- 功能:
- 允许将日期值包含在策略条件中。
- 支持与其他日期值或日期范围的比较。
v. ExtendV类
- 这是一个特殊的类,用于创建可以表示无穷大(
inf)和无穷小(ninf)的值。这对于定义没有明确上限或下限的条件非常有用。 - 功能:
- 通过提供无穷大和无穷小的概念,可以在策略中表达如“大于某个值”或“小于某个值”的开放区间。
- 支持与其他扩展值的比较运算。
vi. min_exval 和 max_exval 函数
- 这两个函数用于比较扩展值,并返回两者之间的最小值或最大值。这对于处理范围和界限特别有用。
- 功能:
min_exval(v1, v2): 返回两个扩展值之间的最小值。max_exval(v1, v2): 返回两个扩展值之间的最大值。- 这些函数允许策略中的条件逻辑涉及无穷大或无穷小的情况,使得策略可以更灵活地表达条件范围。
(2)示例:
-
比较两个整数值:
int_val1 = IntegerV(10) int_val2 = IntegerV(20) print(int_val1 < int_val2) # 输出 True,因为 10 小于 20 -
创建一个字符串值并比较:
str_val = StringV('hello') print(str_val == 'hello') # 输出 True,因为字符串相等 -
使用扩展值处理无穷大和无穷小:
extended_val1 = ExtendV('inf') # 代表无穷大 extended_val2 = ExtendV(100) print(extended_val1 > extended_val2) # 输出 True,因为无穷大大于任何有限数 -
计算两个扩展值的最小值和最大值:
ext_val1 = ExtendV(5) ext_val2 = ExtendV('inf') print(min_exval(ext_val1, ext_val2)) # 输出 e5,因为5小于无穷大 print(max_exval(ext_val1, ext_val2)) # 输出 einf,因为无穷大大于5
这篇关于【PRIVGUARD-privguard-artifact-main】代码学习(parser部分)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




