本文主要是介绍POI推荐实战1:将NYC及CDRs处理后在GETNext运行,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
NYCTKYCDRsInGETNext
将数据经过deepmove方式处理后导入GETNext
目录
- NYCTKYCDRsInGETNext
- 1 NYC&TKY
- 数据经DeepMove方式处理
- 处理后pk文件经PG2Net导出并处理格式
- 数据导入GETNext模型并在服务器训练
- 2 CDRs
- 数据经DeepMove方式处理
- 处理后pk文件经PG2Net导出并处理格式
- 数据导入GETNext模型并训练
1 NYC&TKY
数据经DeepMove方式处理
1、数据直接从Google下载原始txt文件

2、GETNext所给示例数据显示特征有如下这些:user_id,POI_id,POI_catid,POI_catid_code,POI_catname,latitude,longitude,timezone,UTC_time,local_time,day_of_week,norm_in_day_time,trajectory_id,norm_day_shift,norm_relative_time,但观察数据导入过程发现只需要norm_in_day_time,latitude,longitude,POI_catname,POI_catid_code,POI_catid,POI_id,user_id七项特征输入。于是确定经过数据处理后需要保留的特征
3、txt转csv并将时间调整为deepmove示例文件格式

4、deepmove数据处理函数调整
此函数用来生成sessions,与原来的session_tran对比,新建session_tran_new用来读取不同的所需要的特征如经纬度和用户id
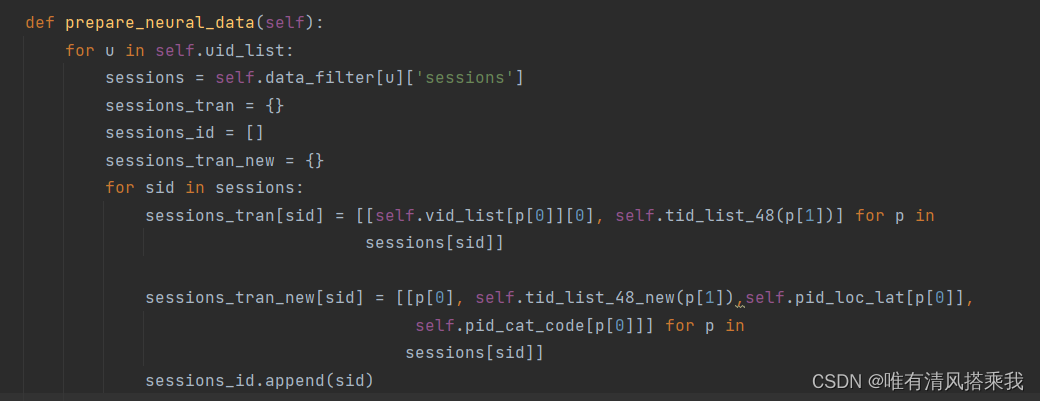
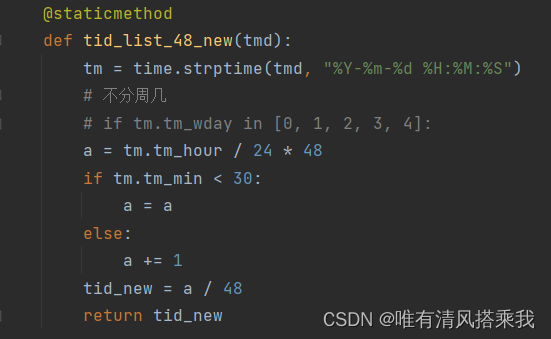
5、在时间部分,与deepmove相比,GETNext不区分周六日并将一天按每半个小时划分。调整后的时间部分处理函数如下:
处理后pk文件经PG2Net导出并处理格式
1、改写PG2Net读取pk文件部分
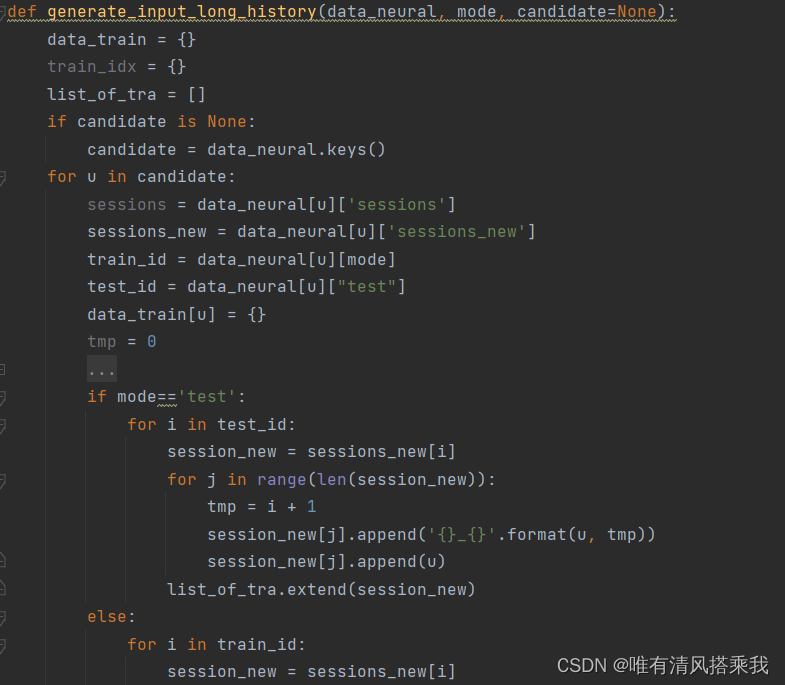
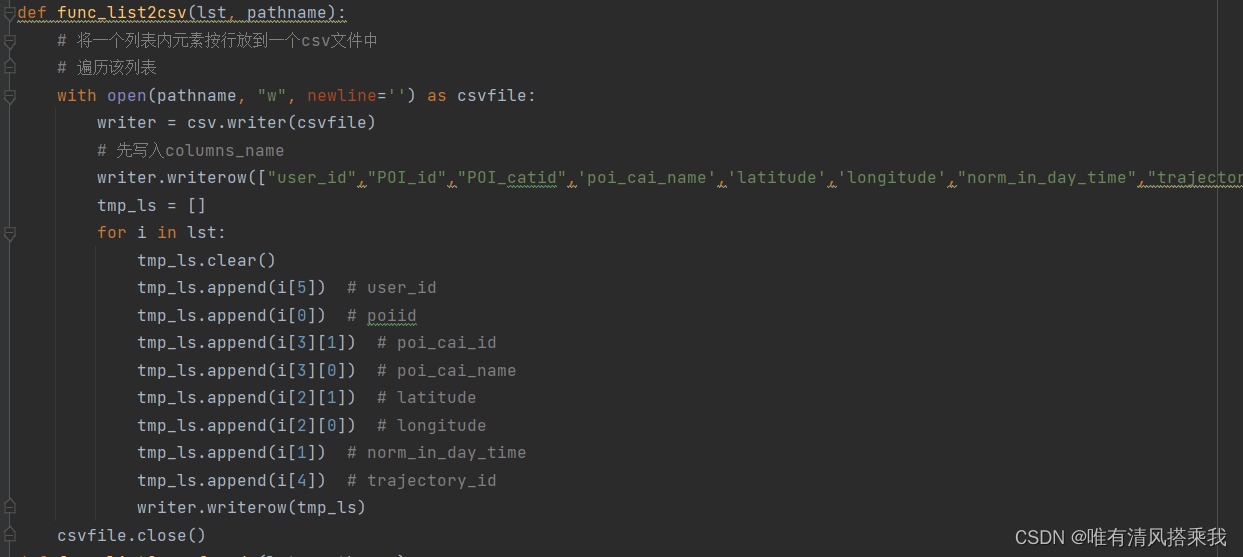
2、对train数据和test数据读出后暂存在列表,经过函数处理后添加表头以及调整格式分别保存到csv
3、设置采样率为100%以打乱数据顺序
数据导入GETNext模型并在服务器训练
1、将数据放入GETNext构图函数,构图后得到训练所需文件

2、训练在服务器上进行,epoch设置为40,训练结果与PG2Net对比如下

2 CDRs
数据经DeepMove方式处理
1、CDR数据集没有POI种类并且对POI没有编号,首先对POI进行编号,处理方式为构建编号字典,如果经纬度完全相同则认为是同一个地点编号相同;同时对时间格式进行处理,处理后的数据如下
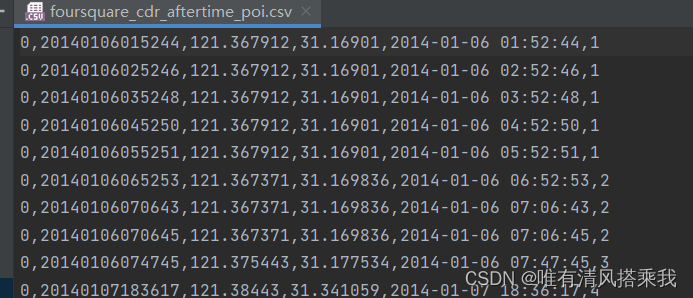
2、与NYC类似将符合deepmove格式的数据导入并进行处理,处理后得到pk文件
处理后pk文件经PG2Net导出并处理格式
1、将pk文件导入PG2Next,然后做法与NYC相同,改写了原PG2Net读取pk文件的函数,结果暂存列表调整格式增加表头后转为csv保存,得到train和test对应的csv文件
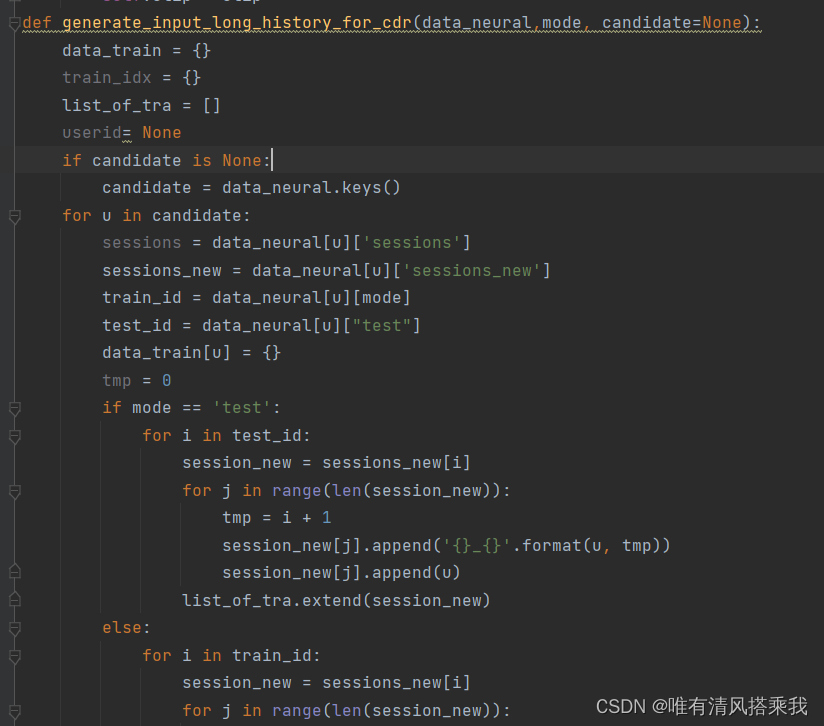
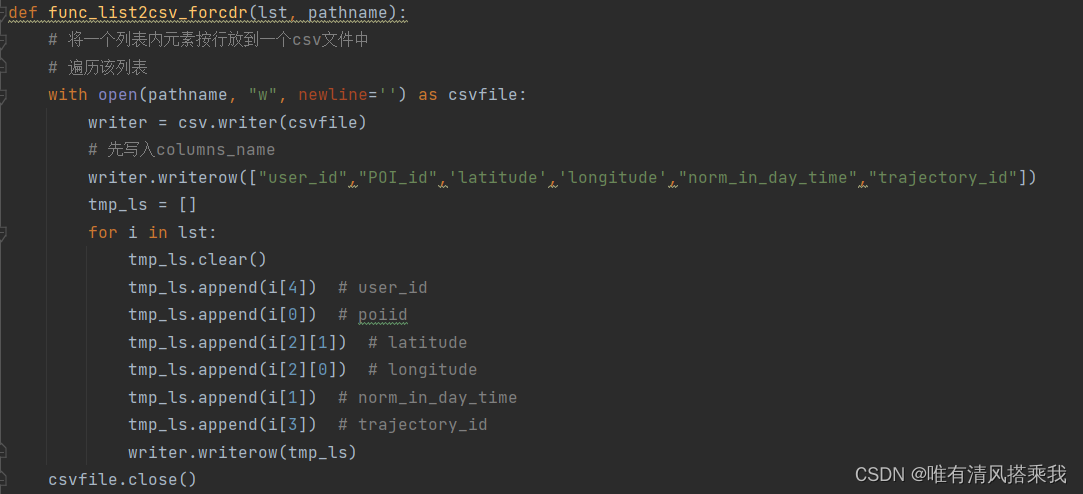
数据导入GETNext模型并训练
1、将处理好的train.csv导入GETNext进行构图,得到25g大的csv…。。。
2、采取采样的方式,采样5%,进行构图后得到11g左右大的csv

3、项目在服务器进行训练,epoch设为40,训练完后结果如下

这篇关于POI推荐实战1:将NYC及CDRs处理后在GETNext运行的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





