本文主要是介绍文本生成评估指标简单介绍BLEU+ROUGE+Perplexity+Meteor 代码实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
以下指标主要针对两种:机器翻译和文本生成(文章生成),这里的文本生成并非是总结摘要那类文本生成,仅仅是针对生成句子/词的评价。
首先介绍BLEU,ROUGE, 以及BLEU的改进版本METEOR;后半部分介绍PPL(简单介绍,主要是关于交叉熵的幂,至于这里的为什么要求平均,是因为我们想要计算在一个n-gram的n中,平均每个单词出现需要尝试的次数。
机器翻译(Machine Translation, MT)
BLEU:Bilingual Evaluation Understudy
形式:
目的:计算网络生成文本Candidate和参考翻译文本(Reference, 可以有多个参考)之间的文本交叉计算。
计算:针对单个Reference:
举例子:
Candidate: ha ha ha
Reference: only saying ha is not good
针对unigram计算BLUE:
BLUE-1 = Candidate在Reference出现的次数 len(Candidate) = count(ha) count(ha,ha, ha) = 1 3 \text{BLUE-1} = \frac{\text{Candidate在Reference出现的次数}}{\text{len(Candidate)}}=\frac{\text{count(ha)}}{\text{count(ha,ha, ha)}} = \frac{1}{3} BLUE-1=len(Candidate)Candidate在Reference出现的次数=count(ha,ha, ha)count(ha)=31
缺点(存在问题): 如果长度很短的话,分母会很小,BLEU取值会很大,为了消除长度带来的影响:
B P = { e 1 − l r e f l c d d , l c d d < l r e f 1 , l c d d ≥ l r e f BP=\left\{ \begin{aligned} e^{1 - \frac{l_{ref}}{l_{cdd}}}, &\quad l_{cdd} < l_{ref} \\ 1, &\quad l_{cdd} \ge l_{ref} \end{aligned} \right. BP=⎩ ⎨ ⎧e1−lcddlref,1,lcdd<lreflcdd≥lref
这里的BP跟n-gram的n无关
则修正之后的BLUE计算方式为:
计算步骤:
- 确定n, n是ngram的n
- 统计n-gram在reference,Candidate出现次数,reference出现次数作为次数统计上限
- 对Candidate中每个n-gram计算匹配次数:
M = ∑ n − g r a m min ( O n g r a m c d d , O n g r a m r e f ) M = \sum_{n-gram} \min(O_{ngram}^{cdd}, O_{ngram}^{ref}) M=n−gram∑min(Ongramcdd,Ongramref)- 计算BLEU-N
B L E U N = M l c d d − 1 + n BLEU_{N} = \frac{M}{l_{cdd} - 1 + n} BLEUN=lcdd−1+nM- 利用几何平均计算综合得分
B L E U = B P ⋅ ( ∏ n = 1 k B L E U n ) 1 k BLEU = BP \cdot ({\prod \limits_{n = 1}^{k}}BLEU_{n})^{\frac{1}{k}} BLEU=BP⋅(n=1∏kBLEUn)k1
这里的k一般取值为4,代表的是看了1-gram, 2-gram, 3-gram, 4-gram综合判断
参考:https://mp.weixin.qq.com/s/wdIWq6XUcB6HJchpHie–g
使用场景:短文本生成的机器翻译评估(有reference的样本)
缺点:只适用于短文本,不适合长文本生成(生成故事)
实现
from torchtext.data.metrics import bleu_score
candidate_corpus = [['My', 'full', 'pytorch', 'test'], ['Another', 'Sentence']]
references_corpus = [[['My', 'full', 'pytorch', 'test'], ['Completely', 'Different']], [['No', 'Match']]]
bleu_score(candidate_corpus, references_corpus)
ROUGE: Recall-Oriented Understuy for Gisting Evaluation
简介:主要用于评估机器翻译、文本摘要(或其他自然语言处理任务)的质量,即:衡量目标文本与生成文本之间的匹配程度,此外还考虑生成文本的召回率,BLEU则相对更看重生成文本的准确率,着重于涵盖参考摘要的内容和信息的完整性。
分别有四种方法:ROUGE-N, ROUGE-L, ROUGE-W, ROUGE-S
主要有两种形式:
- ROUGE-N(N = 1, 2, 3, …)
- ROUGE-L
ROUGE-N计算方式为:
ROUGE-N = Candidate ∩ Reference l e n ( Reference ) \text{ROUGE-N} = \frac{\text{Candidate} \cap \text{Reference}}{len(\text{Reference})} ROUGE-N=len(Reference)Candidate∩Reference
这里的分子交集不像最长公共子串一样,这里的交集不考虑顺序。
ROUGE-L
考虑最长公共子串(是区分顺序的,参考leetcode中最长公共子串计算,不过在这里最小单元从leetcode的字符变成了单词。1143. 最长公共子序列
单句ROUGE-L
ROUGE-L = 最长公共子串 ( Candidate , Reference ) l e n ( Reference ) \text{ROUGE-L} = \frac{\text{最长公共子串}(\text{Candidate}, \text{Reference})}{len(\text{Reference})} ROUGE-L=len(Reference)最长公共子串(Candidate,Reference)
举例子
Candidate: police killed the gunman
Reference1: police kill the gunman
Reference2: the gunman kill police
对reference1而言,ROUGE-2为1/3; 对于reference2而言,ROUGE为1/3
对于reference1而言,ROUGE-L为3/4l; 对于reference2而言,ROUGE-L为1/2
还有ROUGE-W, ROUGE-S, 可以参考: 自动文摘评测方法:Rouge-1、Rouge-2、Rouge-L、Rouge-S
缺点:
- ROUGE只关注文本的表面信息,而忽略了文本的语义信息,因此在评估文本质量时可能会出现误差.
- ROUGE评价指标对于文本的长度比较敏感,因此在评估长文本时可能会出现偏差.
参考:一文带你理解|NLP评价指标 BLEU 和 ROUGE(无公式) - 知乎
实现:
from torchmetrics.text.rouge import ROUGEScore
preds = "My name is John"
target = "Is your name John"
rouge = ROUGEScore()
from pprint import pprint
pprint(rouge(preds, target))
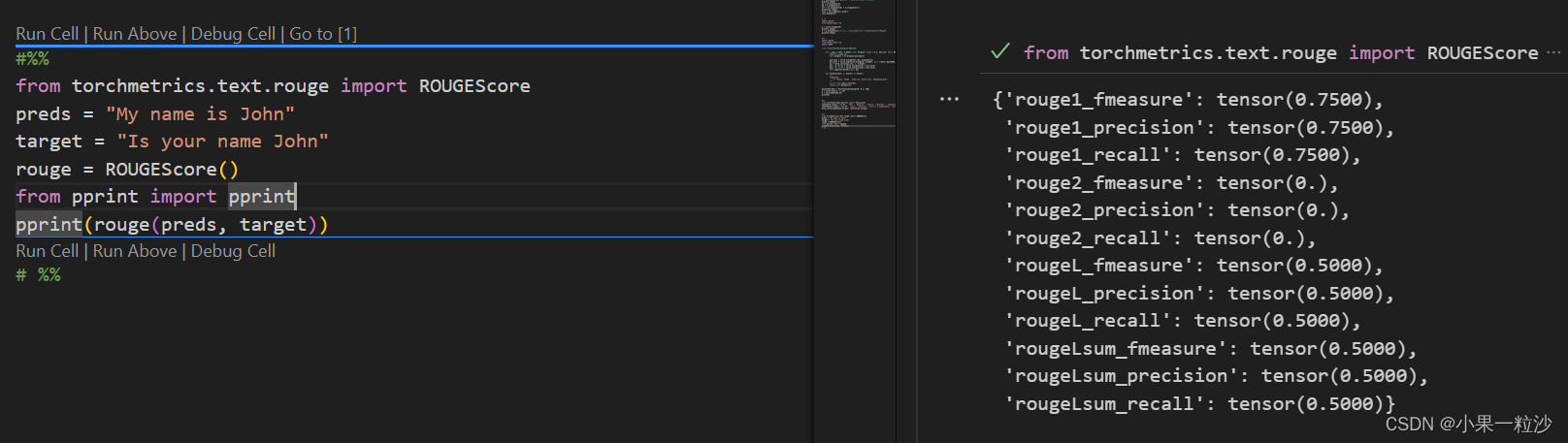
来源:https://torchmetrics.readthedocs.io/en/stable/text/rouge_score.html
跑代码会遇到问题:https://blog.csdn.net/qq_24263553/article/details/105726751
METEOR: The Metric for Evaluation of Translation with Explicit ORdering
目的:解决BLEU的不足,与 BLEU 相比,METEOR 考虑了更多的因素,如同义词匹配、词干匹配、词序等,因此它通常被认为是一个更全面的评价指标。
实现(计算):基于unigram精度和召回率的调和平均
应用:机器翻译(Machine Translation, MT), Image Caption, Question Generation, Summarization
参考:【NLG】(三)文本生成评价指标—— METEOR原理及代码
from nltk.translate.meteor_score import meteor_scorereference3 = '我 说 这 是 怎 么 回 事,原 来 明 天 要 放 假 了'
reference2 = '我 说 这 是 怎 么 回 事'
hypothesis2 = '我 说 这 是 啥 呢 我 说 这 是 啥 呢'
# reference3:参考译文
# hypothesis2:生成的文本
res = round(meteor_score([reference3, reference2], hypothesis2), 4)
print(res)输出:
0.4725
文本生成(Text Generation)
Perplexity 困惑度
这里作了详细的解释:求通俗解释NLP里的perplexity是什么?
计算: 2 H ( p , p ^ ) 2^{H(p, \hat{p})} 2H(p,p^)
其中 H ( p , p ^ ) H(p, \hat{p}) H(p,p^)计算为:
H ( p , p ^ ) = − 1 n ∑ x p ( x ) log 2 p ^ ( x ) H(p, \hat{p}) = -\frac{1}{n} \sum_{x} p(x) \log_2 \hat{p}(x) H(p,p^)=−n1x∑p(x)log2p^(x)
通俗解释:
困惑度p可以理解为,如果每个时间步都根据语言模型计算的概率分布随机挑词,那么平均情况下,挑多少个词才能挑到正确的那个
from torchmetrics.text import Perplexity
import torch
gen = torch.manual_seed(42)
preds = torch.rand(2, 8, 5, generator=gen)
target = torch.randint(5, (2, 8), generator=gen)
target[0, 6:] = -100
perp = Perplexity(ignore_index=-100)
perp(preds, target)
参考:
【NLG】(二)文本生成评价指标—— METEOR原理及代码示例
一文搞懂Language Modeling三大评估标准
Perplexity of fixed-length models
这篇关于文本生成评估指标简单介绍BLEU+ROUGE+Perplexity+Meteor 代码实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



