本文主要是介绍SpringDataRedis笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

spring:application:name: springdataredisredis:host: 120.0.0.1port: 6379password: 123456lettuce:pool:#最大连接数 默认就是8max-active: 8#最大空闲连接 默认就是8max-idle: 8#最小空闲连接 默认是0min-idle: 0#连接等待时间 默认-1无限等待max-wait: 100




RedisTemplate默认用JDK序列化

就会出现这样情况
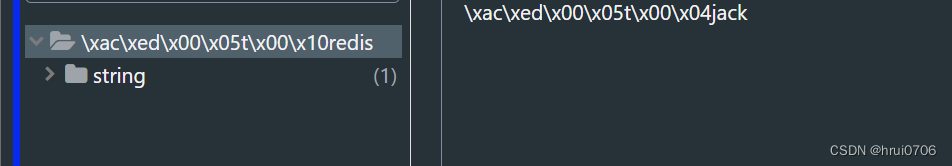
会导致的问题是 当不同客户端由于序列化不同 取出来的不同
例如 我们取 取不出来了 当然 你如果相同客户端 还是可以取出来的 但是显示效果不好 可读性效果不好
所以一般会修改他的序列化 可读性强

那么就改变RedisTemplate的序列化方式

配置类
一般来说key和hashkey都会String
@Configuration
public class RedisTemplateConfig {@Beanpublic RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory connectionFactory){//创建TemplateRedisTemplate<String,Object> redisTemplate=new RedisTemplate<>();//设置连接工程redisTemplate.setConnectionFactory(connectionFactory);//设置序列化工具GenericJackson2JsonRedisSerializer jackson2JsonRedisSerializer=new GenericJackson2JsonRedisSerializer();//Key和hashKey一般用String序列化redisTemplate.setKeySerializer(RedisSerializer.string());redisTemplate.setHashKeySerializer(RedisSerializer.string());//value和hashValue采用JSON序列化redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);return redisTemplate;}}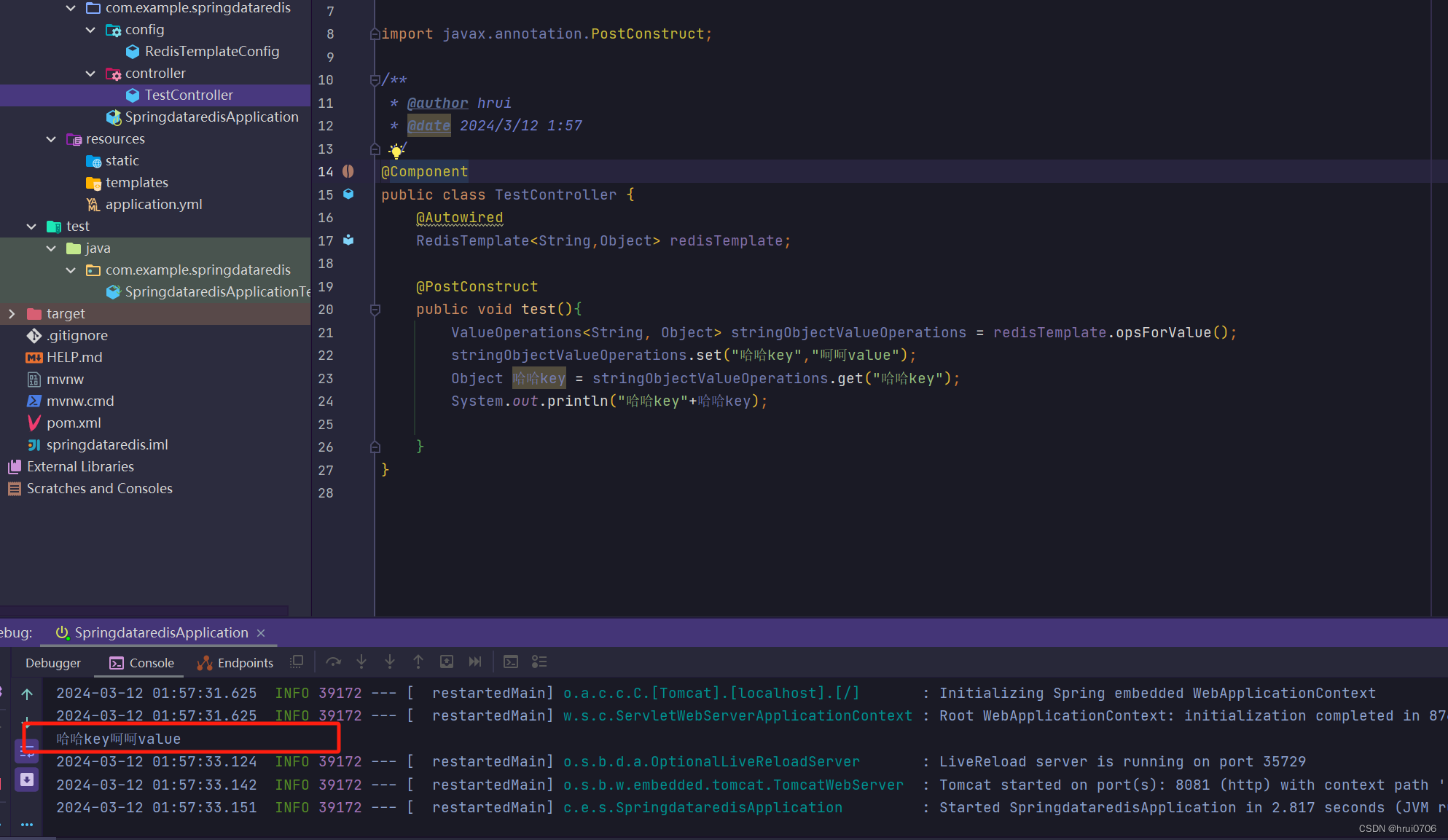

我这里因为引入了web (里面包含了jackson依赖)如果没有 就引入

这样对象也可以序列化
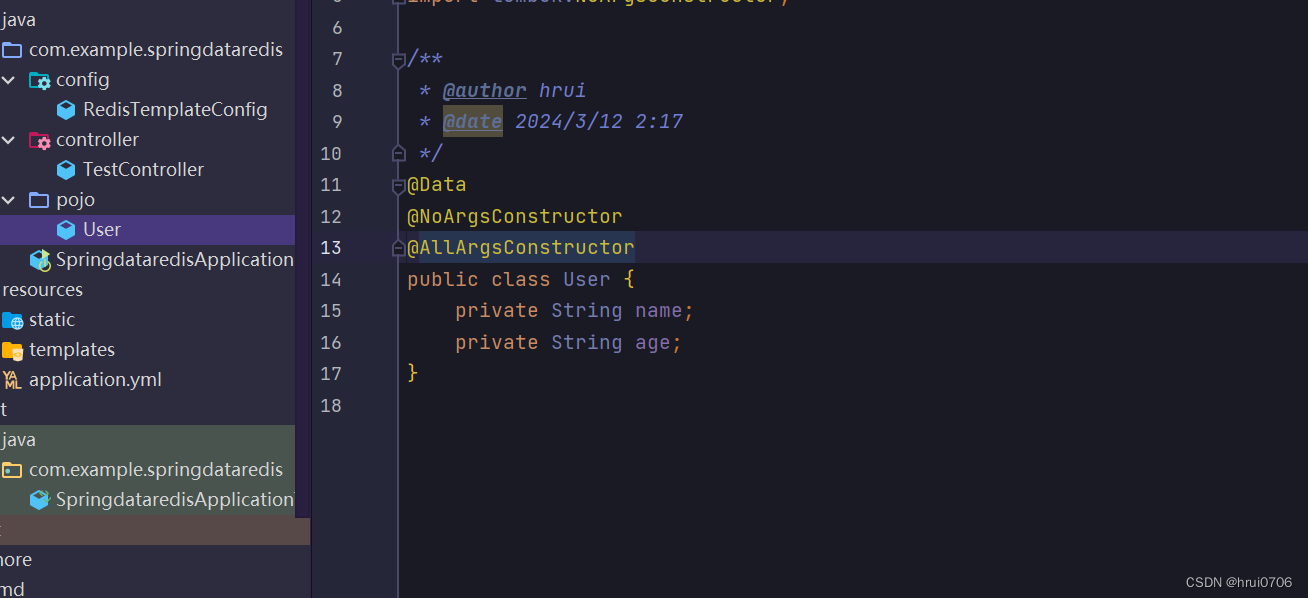

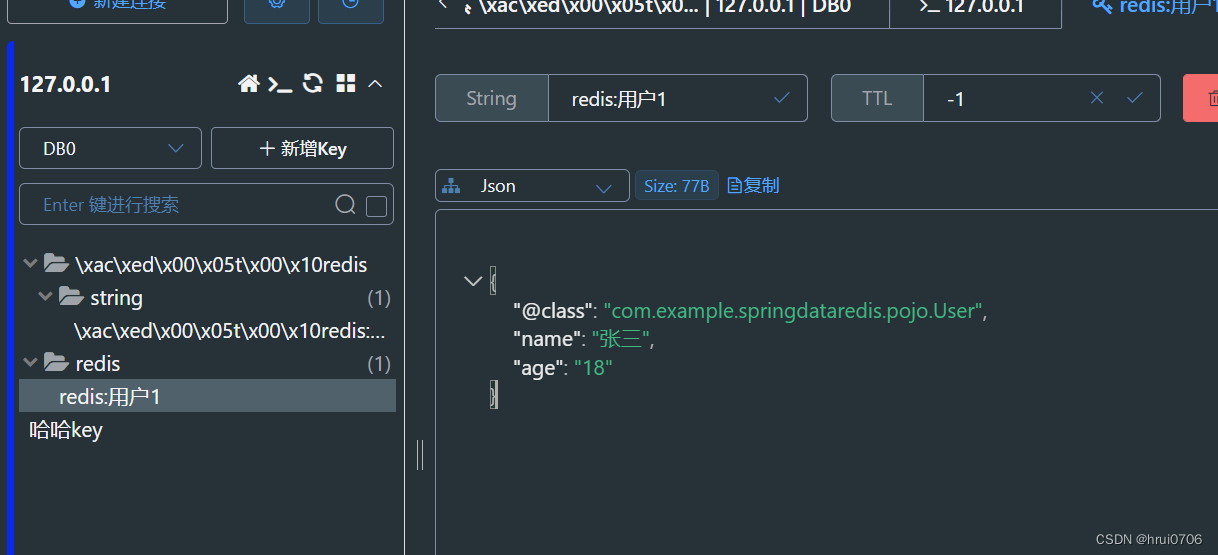

一般的做法

啥意思呢 就是说建议是将value序列化 和hashValue序列话也改成String 达到节省redis内存占用问题,代码上就稍微多写几行
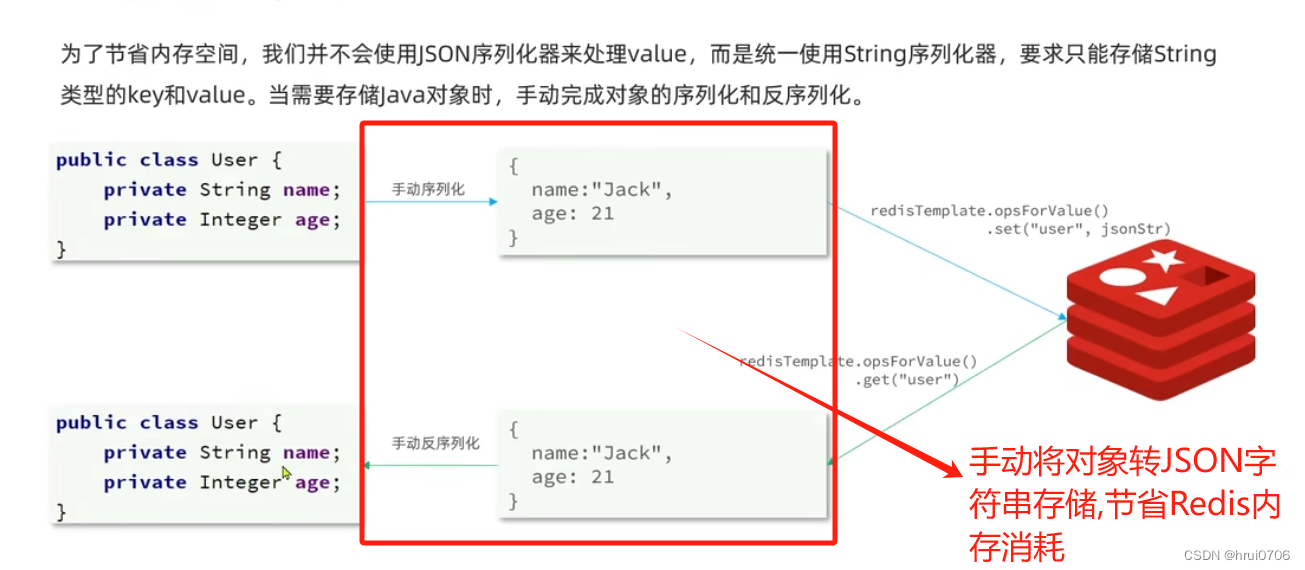
SpringBoot提供了StringRedisTemplate专门用于将Key Value的序列化方式默认就是String方式

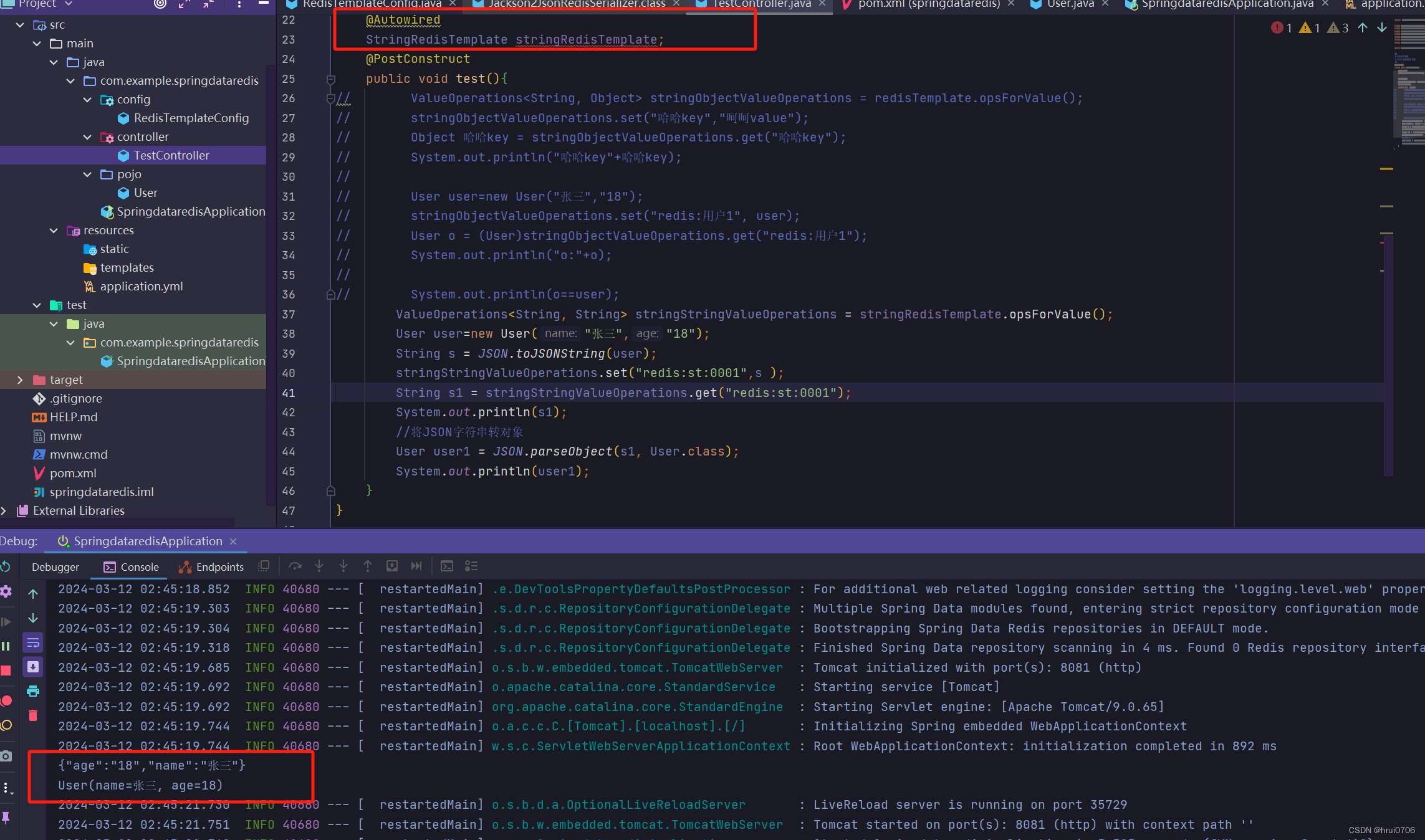
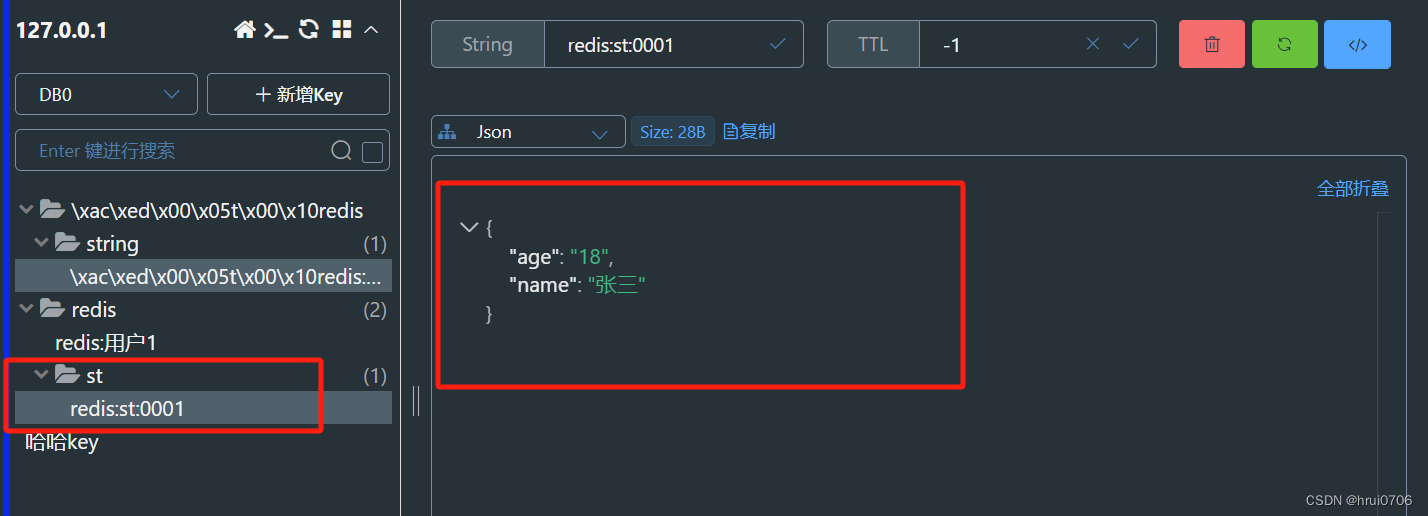
代码上我们就多写了几行 但是在大数据时候 保证了Redis中内存不浪费
@Beanpublic CacheManager cacheManager(RedisConnectionFactory connectionFactory) {//生成一个默认配置,通过config对象即可对缓存进行自定义配置RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();config = config// 设置 key为string序列化.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))// 设置value为json序列化.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer() ))// 不缓存空值.disableCachingNullValues()// 设置缓存的默认过期时间 30分钟.entryTtl(Duration.ofMinutes(30L));//特殊缓存空间应用不同的配置Map<String, RedisCacheConfiguration> map = new HashMap<>();map.put("provider1", config.entryTtl(Duration.ofMinutes(30L)));//provider1缓存空间过期时间 30分钟map.put("provider2", config.entryTtl(Duration.ofHours(1L)));//provider2缓存空间过期时间 1小时//使用自定义的缓存配置初始化一个RedisCacheManagerRedisCacheManager cacheManager = RedisCacheManager.builder(connectionFactory).cacheDefaults(config) //默认配置.withInitialCacheConfigurations(map) //特殊缓存.transactionAware() //事务.build();return cacheManager;}这篇关于SpringDataRedis笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








