本文主要是介绍协程库项目—协程类模块,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ucontext_t结构体、非对称协程
协程类
ucontext_t结构体
头文件中定义的四个函数(getcontext(), setcontext(), makecontext(), swapcontext())和两个结构类型(mcontext_t, ucontext_t)在一个进程中实现用户级的线程切换。
其中,mcontext_t类型与机器相关,不透明;ucontext_t结构体至少包含以下几个域:
typedef struct ucontext {struct ucontext *uc_link;sigset_t uc_sigmask;stack_t uc_stack;mcontext_t uc_mcontext;...
} ucontext_t;
当当前上下文运行终止时,系统会恢复uc_link指向的上下文;uc_sigmask为该上下文中的阻塞信号集合;uc_stack为该上下文中使用的栈;uc_mcontext保存的上下文的特定机器表示,包括调用线程的特定寄存器等。
下面是这四个函数的详细介绍:
int getcontext(ucontext_t *ucp);
初始化ucp结构体,将当前的上下文保存到ucp中。
int setcontext(const ucontext_t *ucp);
设置当前的上下文为ucp,setcontext的上下文ucp应该通过getcontext或者makecontext取得。如果调用成功则不返回。如果上下文是通过调用getcontext()取得,程序会继续执行这个调用(从该上下文的状态开始继续执行,即调用getcontext处后接着执行)。如果上下文是通过调用makecontext取得,程序会调用makecontext函数的第二个参数指向的函数,如果func函数返回,则恢复makecontext第一个参数指向的上下文。如果uc_link为NULL,则线程退出。
void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...);
makecontext修改通过getcontext取得的上下文ucp(这意味着调用makecontext前必须先调用getcontext)。然后给该上下文指定一个栈空间ucp->stack,设置后继的上下文ucp->uc_link。当上下文通过setcontext或者swapcontext激活后,执行func函数,argc为func的参数个数,后面是func的参数序列。当func执行返回后,继承的上下文被激活,如果继承上下文为NULL时,线程退出。
int swapcontext(ucontext_t *oucp, ucontext_t *ucp);
保存当前上下文到oucp结构体中,然后激活upc上下文。如果执行成功,getcontext返回0,setcontext和swapcontext不返回;如果执行失败,getcontext,setcontext,swapcontext返回-1,并设置对应的errno。
小结一下:
makecontext:初始化一个ucontext_t,func参数指明了该context的入口函数,argc为入口参数的个数,每个参数的类型必须是int类型。另外在makecontext前,一般需要显示的初始化栈信息以及信号掩码集同时也需要初始化uc_link,以便程序退出上下文后继续执行。
swapcontext:原子操作,该函数的工作是保存当前上下文并将上下文切换到新的上下文运行。
getcontext:将当前的执行上下文保存在cpu中,以便后续恢复上下文
setcontext:将当前程序切换到新的context,在执行正确的情况下该函数直接切换到新的执行状态,不会返回。
⾮对称模型
非对称协程(asymmetric
coroutines)是跟一个特定的调用者绑定的,协程让出CPU时,只能让回给调用者。何为非对称呢?在于协程的调用(call/resume)和返回(return/yield)的地位不对等。程序控制流转移到被调用者协程,而被调用者只能返回最初调用它的协程。
对称协程(symmetric
coroutines)在于协程调用和返回的地位是对等的。启动之后就跟启动之前的协程没有任何关系了。协程的切换操作,一般而言只有一个操作,yield,用于将程序控制流转移给其他的协程。对称协程机制一般需要一个调度器的支持,按一定调度算法去选择yield的目标协程。
这里采用的是非对称模型,
保证⼦协程不能再创建新的协程,即协程不能嵌套调⽤,⼦协程只能与主线程进行切换。注意下图中子协程只能切换回主协程,不能创建新的子协程。
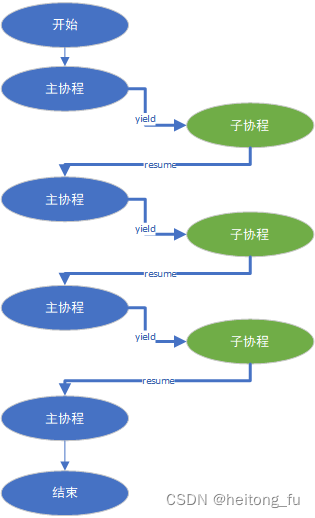
对于非对称协程,⼦协程和⼦协程切换导致线程主协程跑⻜的关键原因在于,每个线程只有两个线程局部变量⽤于保存当前的协程上下⽂信息。也就是说线程任何时候都最多只能知道两个协程的上下⽂,其中⼀个是当前正在运⾏协程的上下⽂,另⼀个是线程主协程的上下⽂,如果⼦协程和⼦协程切换,那这两个上下⽂都会变成⼦协程的上下⽂,线程主 协程的上下⽂丢失了,程序也就跑⻜了。
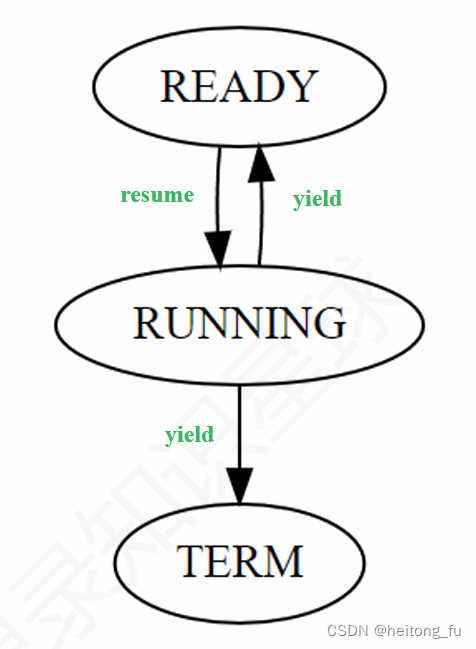
简化协程状态
只设置三种协程状态:就绪态、运⾏态和结束态,⼀个协程要么正在运⾏(RUNNING),要么准备运⾏(READY),要运⾏
结束(TERM)。
协程操作
协程创建操作
创建线程主协程:只需要将协程设置为当前运行协程,协程转为RUNING,获取当前上下文。
创建⽤户协程:则需要额外创建栈空间和绑定协程入口函数
/**
* @brief 线程主协程构造函数
* @attention ⽆参构造函数只⽤于创建线程的第⼀个协程,也就是线程主函数对应的协程,
* 这个协程只能由GetThis()⽅法调⽤,所以定义成私有⽅法
*/
Fiber::Fiber(){SetThis(this);m_state = RUNNING;if (getcontext(&m_ctx)) {Fzk_ASSERT2(false, "getcontext");}++s_fiber_count;m_id = s_fiber_id++; // 协程id从0开始,⽤完加1Fzk_LOG_DEBUG(g_logger) << "Fiber::Fiber() main id = " << m_id;
}/**
* @brief 构造函数,⽤于创建⽤户协程
* @param[] cb 协程⼊⼝函数
* @param[] stacksize 栈⼤⼩
*/
Fiber::Fiber(std::function<void()> cb, size_t stacksize): m_id(s_fiber_id++), m_cb(cb) {++s_fiber_count;m_stacksize = stacksize ? stacksize : g_fiber_stack_size->getValue();m_stack = StackAllocator::Alloc(m_stacksize);if (getcontext(&m_ctx)) {Fzk_ASSERT2(false, "getcontext");}m_ctx.uc_link = nullptr;m_ctx.uc_stack.ss_sp = m_stack;m_ctx.uc_stack.ss_size = m_stacksize;makecontext(&m_ctx, &Fiber::MainFunc, 0);Fzk_LOG_DEBUG(g_logger) << "Fiber::Fiber() id = " << m_id;
}
协程间执行权转换操作
resume:将协程(非TERM、RUNNING状态)设置为当前运行协程,协程转为RUNING,恢复协程运行
yield:将主协程设置为当前运行协程,协程转为READY,让出执⾏权
主要区别:前者将保存线程主协程上下文,并切换运行子协程的上下文;前者将保存子协程上下文,并切换运行主协程的上下文;
/// @brief 恢复协程运行
///恢复该协程的运行。
void Fiber::resume() {Fzk_ASSERT(m_state != TERM && m_state != RUNNING);SetThis(this);m_state = RUNNING;//涉及后面的协程调度,如果协程参与调度器调度,那么应该和调度器的主协程进行swap,而不是线程主协程// if (m_runInScheduler) {// if (swapcontext(&(Scheduler::GetMainFiber()->m_ctx), &m_ctx)) {// Fzk_ASSERT2(false, "swapcontext");// }// } else {// if (swapcontext(&(t_thread_fiber->m_ctx), &m_ctx)) {// Fzk_ASSERT2(false, "swapcontext");// }// }//发生段错误,已解决,是新创建的子协程未保存其上下文,导致&m_ctx对未初始化对象进行取地址操作if (swapcontext(&(t_thread_fiber->m_ctx), &m_ctx)) {Fzk_ASSERT2(false, "swapcontext");}
}
/// @brief 当前协程让出执⾏权
///当前协程让出执⾏权, 当前协程的状态有两种情况:1、协程函数未执行完,更新为READY; 2、执行完更新为TERM
void Fiber::yield() {/// 协程运行完之后会自动yield一次,用于回到主协程,此时状态已为结束状态Fzk_ASSERT(m_state == RUNNING || m_state == TERM);SetThis(t_thread_fiber.get());if(m_state != TERM) {m_state = READY;}// 如果协程参与调度器调度,那么应该和调度器的主协程进行swap,而不是线程主协程// if(m_runInScheduler) {// if(swapcontext(&m_ctx, &(Scheduler::GetMainFiber()->m_ctx))) {// Fzk_ASSERT2(false, "swapcontext");// }// } else {// if (swapcontext(&m_ctx, &(t_thread_fiber->m_ctx))) {// Fzk_ASSERT2(false, "swapcontext");// }// }if (swapcontext(&m_ctx, &(t_thread_fiber->m_ctx))) {Fzk_ASSERT2(false, "swapcontext");}
}
后续工作:实现协程调度类
为使得协程类能够通过调度器来运⾏,需要对已实现的协程类进行以下具体操作:
- 给协程类增加⼀个bool类型的成员m_runInScheduler,⽤于记录该协程是否通过调度器来运⾏。
- 创建协程时,根据协程的身份指定对应的协程类型,具体来说,只有想让调度器调度的协程的 m_runInScheduler值为true,线程主协程和线程调度协程的m_runInScheduler都为false。
- resume⼀个协程时,如果如果这个协程的m_runInScheduler值为true,表示这个协程参与调度器调度,那它应该和三个线程局部变量中的调度协程上下⽂进⾏切换,同理,在协程yield时,也应该恢复调度协程的上下⽂,表示从⼦协程切换回调度协程;
- 如果协程的m_runInScheduler值为false,表示这个协程不参与调度器调度,那么在resume协程时,直接和线程主协程切换就可以了,yield也⼀样,应该恢复线程主协程的上下⽂。m_runInScheduler值为false的协程。上下⽂切换完全和调度协程⽆关,可以脱离调度器使⽤。
这篇关于协程库项目—协程类模块的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







