本文主要是介绍LeetCode 173.二叉搜索树迭代器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
实现一个二叉搜索树迭代器类BSTIterator ,表示一个按中序遍历二叉搜索树(BST)的迭代器:
BSTIterator(TreeNode root) 初始化 BSTIterator 类的一个对象。BST 的根节点 root 会作为构造函数的一部分给出。指针应初始化为一个不存在于 BST 中的数字,且该数字小于 BST 中的任何元素。
boolean hasNext() 如果向指针右侧遍历存在数字,则返回 true ;否则返回 false 。
int next()将指针向右移动,然后返回指针处的数字。
注意,指针初始化为一个不存在于 BST 中的数字,所以对 next() 的首次调用将返回 BST 中的最小元素。
你可以假设 next() 调用总是有效的,也就是说,当调用 next() 时,BST 的中序遍历中至少存在一个下一个数字。
示例:
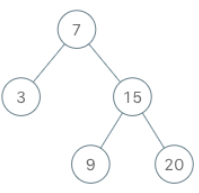
输入
[“BSTIterator”, “next”, “next”, “hasNext”, “next”, “hasNext”, “next”, “hasNext”, “next”, “hasNext”]
[[[7, 3, 15, null, null, 9, 20]], [], [], [], [], [], [], [], [], []]
输出
[null, 3, 7, true, 9, true, 15, true, 20, false]
解释
BSTIterator bSTIterator = new BSTIterator([7, 3, 15, null, null, 9, 20]);
bSTIterator.next(); // 返回 3
bSTIterator.next(); // 返回 7
bSTIterator.hasNext(); // 返回 True
bSTIterator.next(); // 返回 9
bSTIterator.hasNext(); // 返回 True
bSTIterator.next(); // 返回 15
bSTIterator.hasNext(); // 返回 True
bSTIterator.next(); // 返回 20
bSTIterator.hasNext(); // 返回 False
提示:
树中节点的数目在范围 [1, 105] 内
0 <= Node.val <= 106
最多调用 105 次 hasNext 和 next 操作
进阶:
你可以设计一个满足下述条件的解决方案吗?next() 和 hasNext() 操作均摊时间复杂度为 O(1) ,并使用 O(h) 内存。其中 h 是树的高度。
法一:先在构造函数中把整个二叉树的中序遍历存下来:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class BSTIterator {
public:BSTIterator(TreeNode* root) : curIdx(0),inorderRes(){inorder(root);}int next() {return inorderRes[curIdx++];}bool hasNext() {return curIdx < inorderRes.size();}private:int curIdx;vector<int> inorderRes;void inorder(TreeNode *node){if (node == nullptr){return;}inorder(node->left);inorderRes.push_back(node->val);inorder(node->right);}
};/*** Your BSTIterator object will be instantiated and called as such:* BSTIterator* obj = new BSTIterator(root);* int param_1 = obj->next();* bool param_2 = obj->hasNext();*/
如果树中有n个节点,此算法构造函数的时间复杂度为O(n),next和hasNext方法的时间复杂度为O(1);空间复杂度为O(n),构造函数的栈空间平均需要O(logn),最差需要O(n),存储中序遍历的结果需要O(n)。
法二:手动模拟一个栈:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class BSTIterator {
public:BSTIterator(TreeNode* root) {curNode = root;}int next() {while (curNode != nullptr){s.push(curNode);curNode = curNode->left;}curNode = s.top();int ret = curNode->val;s.pop();curNode = curNode->right;return ret;}bool hasNext() {return !s.empty() || curNode;}private:stack<TreeNode *> s;TreeNode *curNode;
};/*** Your BSTIterator object will be instantiated and called as such:* BSTIterator* obj = new BSTIterator(root);* int param_1 = obj->next();* bool param_2 = obj->hasNext();*/
如果树中有n个节点,此算法构造函数和hasNext方法的时间复杂度为O(1),next方法的时间复杂度平均为O(1),最差为O(n);空间复杂度为O(logn),模拟的栈空间平均需要O(logn),最差需要O(n)。
法三:Morris遍历,核心是将当前节点的前驱结点连到当前节点,这样就不需要栈了,对于中序遍历来说,就是将当前节点的左节点的最右节点指向自身:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class BSTIterator {
public:BSTIterator(TreeNode* root) : curNode(root){}int next() {if (curNode->left == nullptr){int res = curNode->val;curNode = curNode->right;return res;}while (curNode->left){TreeNode *mostRightOfLeft = getMostRightOfLeft(curNode);if (mostRightOfLeft->right == nullptr){mostRightOfLeft->right = curNode;curNode = curNode->left;}else if (mostRightOfLeft->right == curNode){int res = curNode->val;mostRightOfLeft->right = nullptr;curNode = curNode->right;return res;}}int res = curNode->val;curNode = curNode->right;return res;}bool hasNext() {return curNode;}private:TreeNode *curNode;TreeNode *getMostRightOfLeft(TreeNode *node){TreeNode *cur = node->left;while (cur->right != nullptr && cur->right != node){cur = cur->right;}return cur;}
};/*** Your BSTIterator object will be instantiated and called as such:* BSTIterator* obj = new BSTIterator(root);* int param_1 = obj->next();* bool param_2 = obj->hasNext();*/
如果树中有n个节点,此算法构造函数和hasNext方法的时间复杂度为O(1),next方法的时间复杂度平均为O(1),最差为O(n);空间复杂度为O(1)。
这篇关于LeetCode 173.二叉搜索树迭代器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






