本文主要是介绍【决策树】预测用户用电量,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
决策树预测用户用电量
文章目录
- 决策树预测用户用电量
- 👉引言💎
- 一、 数据预处理
- 数据预处理
- 初步数据分析
- 二、 机器学习算法
- 决策树回归预测用电量
- 决策树模型介绍:
- 回归预测
- 三、 可视化结果
- 四、 数据分析与结论
- 代码如下
👉引言💎
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。
热爱写作,愿意让自己成为更好的人…
…

| 铭记于心 | ||
|---|---|---|
| 🎉✨🎉我唯一知道的,便是我一无所知🎉✨🎉 |
一、 数据预处理
数据预处理
通过pandas的read_csv()方法将表格数据读入到内存中,同时对原始数据进行统计分析,发现有许多缺失数据,首先进行数据预处理。
对原始数据使用pandas库DataFrame类的groupby()以及apply()方法进行分组聚合,以用户为关键点进行分组,可以得到每个用户的各方面用电数据,随后对缺失数据以及对应的用电属性进行统计并可视化,舍弃有效数据少的属性,保留剩余的属性进行进一步分析。
部分属性图分布趋势如下
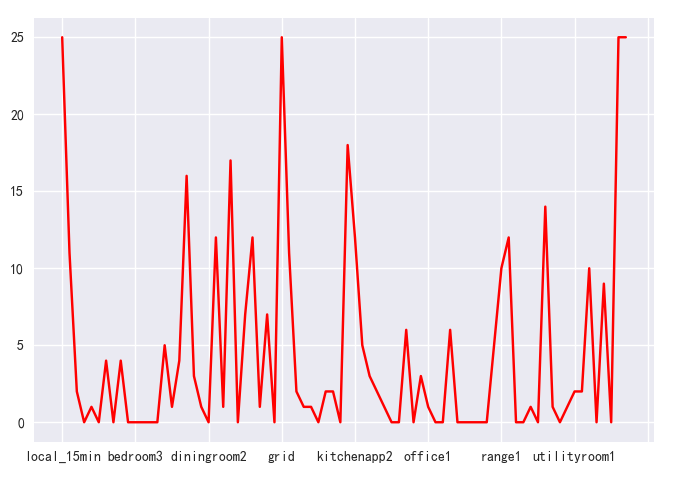
x轴表示用电属性,y轴表示具备该数据的用户数量,将中点线绘制到图中进行对比分析,从中取出有效用户数据超过用户量一半的属性进行下一步分析
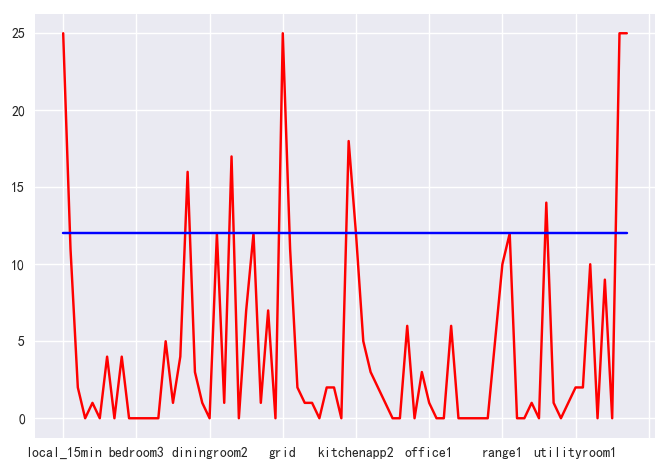
通过数据处理得到不同属性情况下用户用电数据的有效数量(即多少位用户在具备该属性下的时段数据),同时进行倒序排序,。由此可得前五项(由于leg1v与leg2v的属性意义对用电量预测关系不大,故舍去)
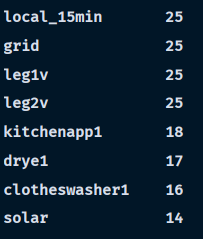
故选取kitchenapp1,grid, drye1,以及clotheswasher1 对数据较全的用户进行相关分析
初步数据分析
由于数据量比较大,取出一个用户的数据进行相关性分析,首先取出第一个用户,也就是编号为25的用户的用电数据进行回归预测,其用电数据主要是grid以及kitchenapp1,drye1,clotheswasher1 。
数据意义解释:
grid:每个时间段仪表数据目前测量从电网或馈电到电网的功率 。
kitchenapp1:第一厨房小家电电路仪表数据呈现。这种类型的电路只包括厨房里的壁式插座,因此可能包括烤面包机、咖啡机、搅拌机等。
drye1:电动干衣机(240V电路)仪表数据呈现
clotheswasher1:单机洗衣机仪表数据呈现
分别数据可视化为折线图与热力图如下:
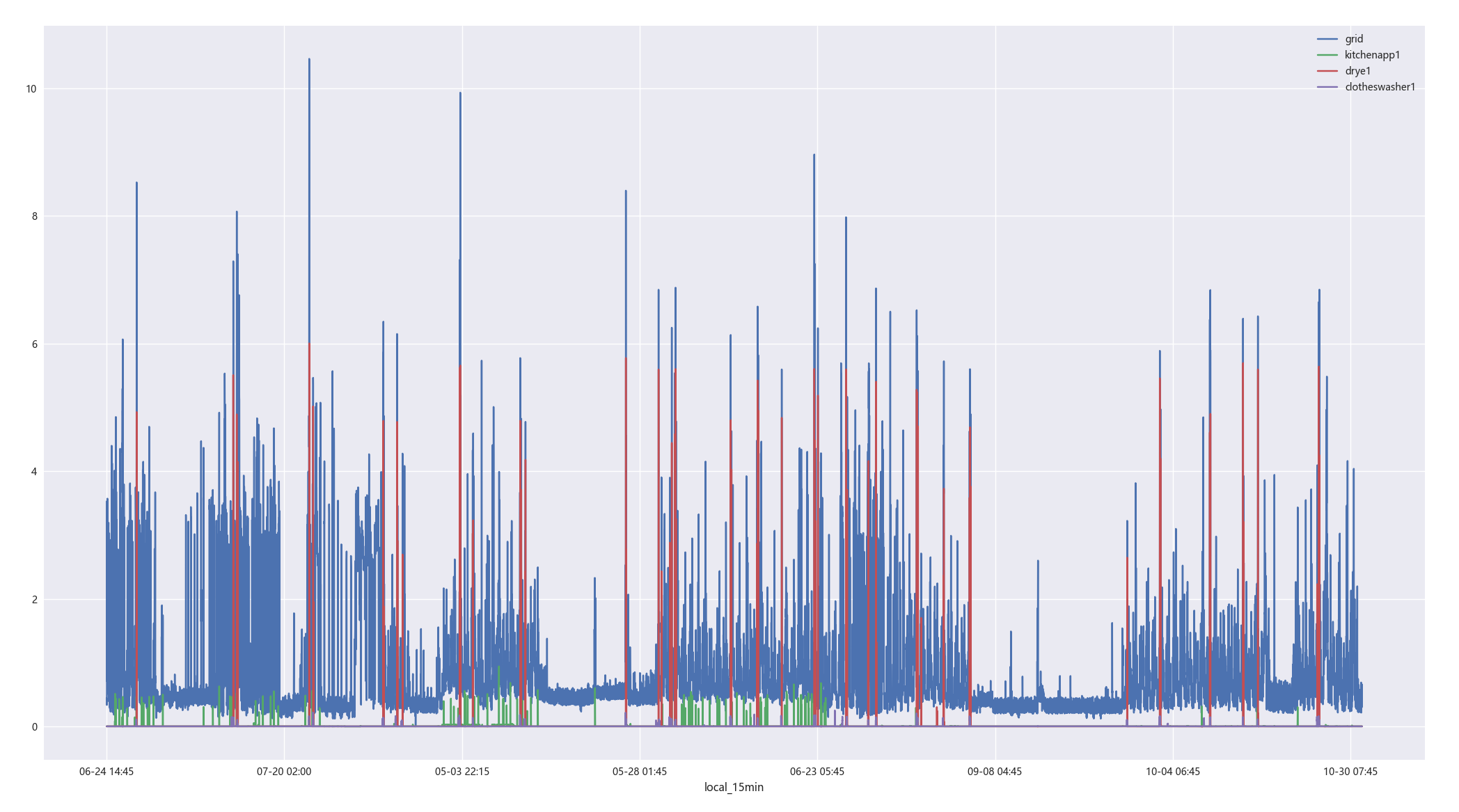
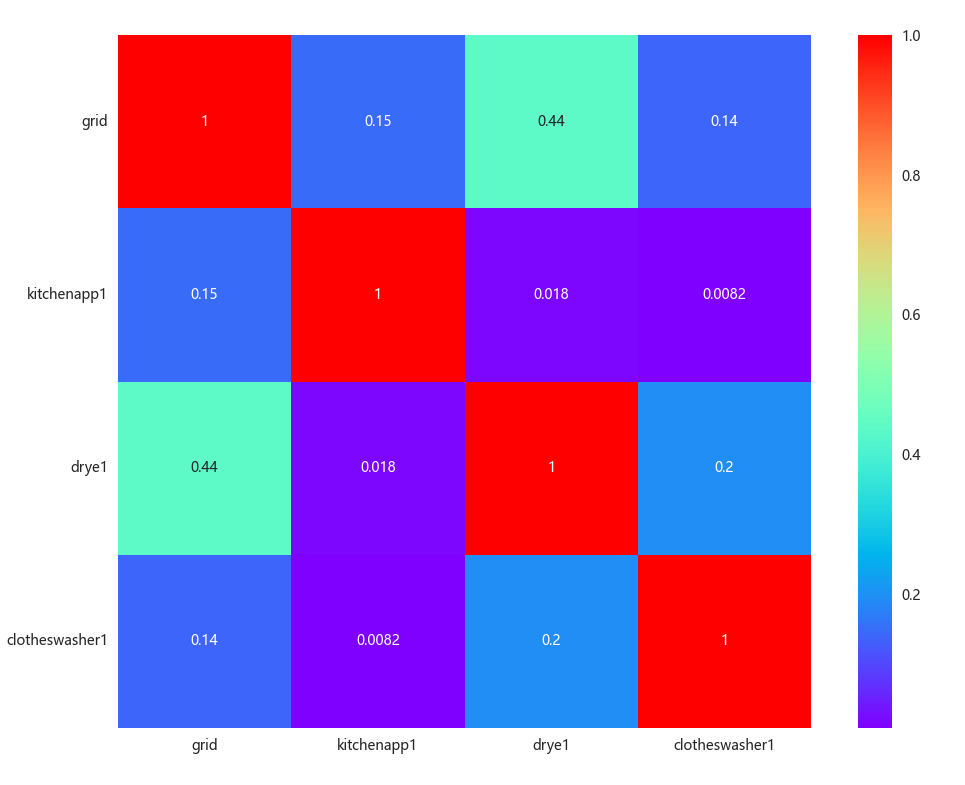
由上图相关性分析可得,drye1 的影响比其他因素更大
二、 机器学习算法
决策树回归预测用电量
决策树模型介绍:
决策树(Decision Tree)及其变种是另一类将输入空间分成不同的区域,每个区域有独立参数的算法。决策树分类算法是一种基于实例的归纳学习方法,它能从给定的无序的训练样本中,提炼出树型的分类模型。树中的每个非叶子节点记录了使用哪个特征来进行类别的判断,每个叶子节点则代表了最后判断的类别。根节点到每个叶子节点均形成一条分类的路径规则。而对新的样本进行测试时,只需要从根节点开始,在每个分支节点进行测试,沿着相应的分支递归地进入子树再测试,一直到达叶子节点,该叶子节点所代表的类别即是当前测试样本的预测类别。
机器学习中,决策树是一个预测模型。它代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分支叉路径则代表某个可能的属性值,而每个叶节点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来作预测。从数据产生决策树的机器学习技术叫做决策树学习,通俗说就是决策树。
回归预测
接下里通过构建决策树回归模型预测用户的时段用电量,这里使用python的sklearn机器学习库进行相关的分析
sklearn是机器学习中一个常用的python第三方模块,里面对一些常用的机器学习方法进行了封装,比如SVM、KNN、贝叶斯、线性回归、逻辑回归、决策树、随机森林、xgboost、GBDT、boosting、神经网络NN;statsmodels 用于拟合多种统计模型,比如方差分析、ARIMA、线性回归等,执行统计测试以及数据探索和可视化。
在本次模型构建过程中主要使用的相关的库版本为:
python版本为3.9
numpy版本为 1.23.4
matplotlib版本为3.5.3
pandas版本为 1.5.1
sklearn版本为:0.0
运用sklearn.model_selection的train_test_split进行数据集划分,也可以用k折交叉验证(KFold)
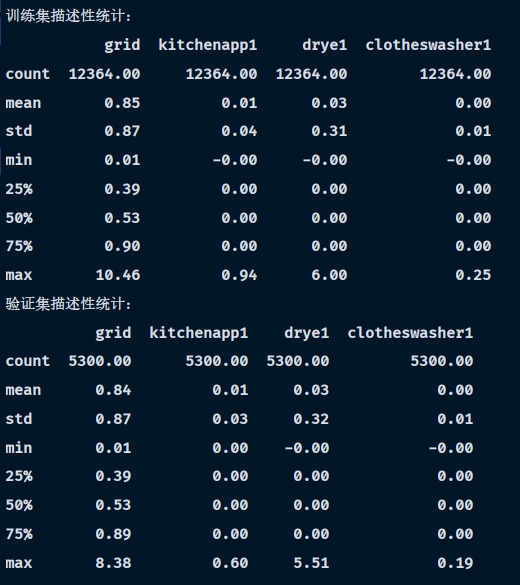
在使用sklearn对数据集进行划分后,得到训练集与测试集,自变量即grid列的数据,表示用户在不同时间段的用电量,同时将其他三个变量设置为自变量,得到训练集与测试集的统计描述
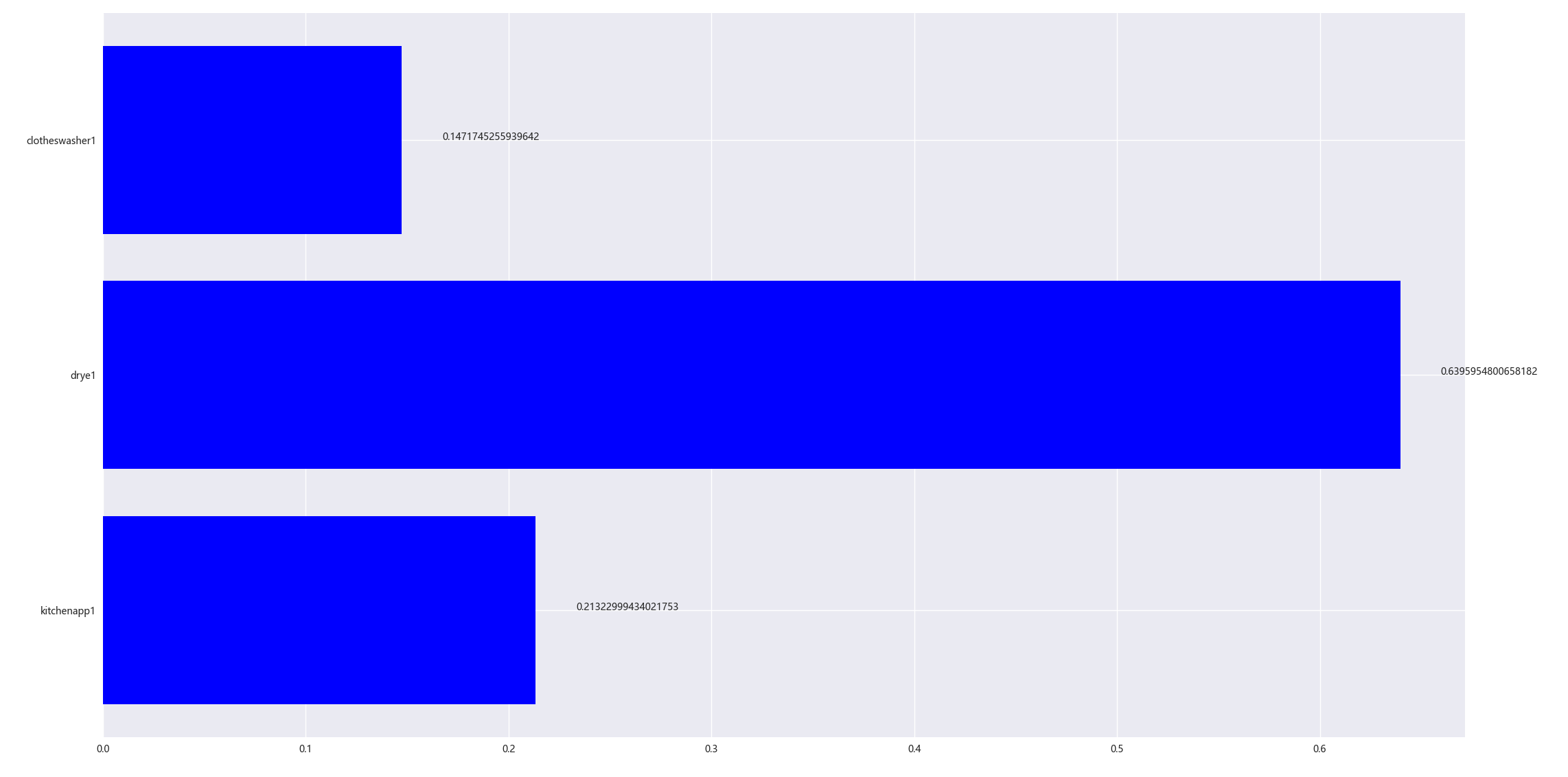
进行初步的训练与评估后得到特征重要性,并可视化如下所示
三、 可视化结果
可视化结果及相关分析在上文
四、 数据分析与结论
通过决策树回归得到, 电动干衣机(240V电路)的使用对Y时段用户用电量影响最大,其重要性系数为0.6396,远高于其他因素,与相关系数分析结果一致
随后分别以训练集以及验证集展开对决策树模型的评估
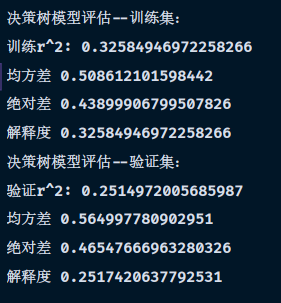
发现评估效果良好
决策树回归模型构建过程图:

代码如下
import warningsimport numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
warnings.filterwarnings('ignore')plt.style.use('seaborn')
plt.rcParams['font.sans-serif'] = 'Microsoft YaHei'data = pd.read_csv('15minute_data_newyork.csv')
data[data.columns[1]] = data[data.columns[1]].apply(lambda x: x[5:-6])#数据预分析
User = data.groupby(data.columns[0]).count()
# 用户数量及编号列表
name = User.index
namef = len(list(name))//2
sum = len(User.index)
filed = User.apply(lambda x: x != 0).apply(np.sum, axis=0)filed.plot( style=['r'])
plt.plot(filed.index,[namef]*len(filed.index),'b')
plt.show(block=True)# User=User.loc[:,(filed>namef//2).values]
# User.apply(lambda x: x != 0).apply(np.sum, axis=0).sort_values(ascending=False)nowData=data[['dataid','local_15min','grid','kitchenapp1','drye1','clotheswasher1']].dropna(how='any').set_index('dataid')#得到一个用户的三方面用电数据
User=nowData.groupby(['dataid'])
userSiggle=list(User)[0][1]
User.apply(lambda x: x != 0).apply(np.sum, axis=0).sort_values(ascending=False)
userSiggle.apply(lambda x: x != 0).apply(np.sum, axis=0).sort_values(ascending=False)
userSiggle.set_index(userSiggle.columns[0],inplace=True)
userSiggle.plot()
plt.show(block=True)userScorr=userSiggle.corr()
f,fig = plt.subplots(nrows=1,ncols=1,figsize=(12,9))
sns.heatmap(userScorr,cmap='rainbow',annot=True, vmax=1 , square=True , fmt='.2g')
label_y = fig.get_yticklabels()
plt.setp(label_y , rotation = 360)
plt.show(block=True)# userSiggle.to_csv("userSiggle.csv")
from sklearn.model_selection import train_test_split
house_train,house_test=train_test_split(userSiggle,test_size=0.3, random_state=0)
print ('训练集描述性统计:')
print (house_train.describe().round(2))
print ('验证集描述性统计:')
print (house_test.describe().round(2))X_train=house_train.loc[:,userSiggle.columns[1:]]
y_train=house_train.loc[:,userSiggle.columns[0]]X_test=house_test.loc[:,userSiggle.columns[1:]]
y_test=house_test.loc[:,userSiggle.columns[0]]##决策树模型训练、评估
from sklearn.tree import DecisionTreeRegressor
from sklearn.tree import export_graphviz
#tree = DecisionTreeRegressor(criterion='mse' ,max_depth=4,max_features='sqrt',min_samples_split=2,min_samples_leaf=1,random_state=0).fit(X_train,y_train)
tree = DecisionTreeRegressor(criterion='mse' ,max_depth=None,max_features='sqrt',min_samples_split=2,min_samples_leaf=1,random_state=0).fit(X_train,y_train)
y_tree=tree.predict(X_train)export_graphviz(tree, out_file = 'house_tree.dot',max_depth=None,feature_names = userSiggle.columns[1:],rounded = True, precision = 1)##特征重要性
print(userSiggle.columns[1:])
print ("指标重要性:",tree.feature_importances_)
plt.barh(range(len(tree.feature_importances_)), tree.feature_importances_, color='b',tick_label = userSiggle.columns[1:])
list(map(lambda x:plt.text( x[1]+0.02,x[0], x[1]),enumerate(tree.feature_importances_)))
plt.show(block=True)from sklearn.metrics import mean_squared_error,explained_variance_score,mean_absolute_error,r2_score
print ("决策树模型评估--训练集:")
print ('训练r^2:',tree.score(X_train,y_train))
print ('均方差',mean_squared_error(y_train,tree.predict(X_train)))
print ('绝对差',mean_absolute_error(y_train,tree.predict(X_train)))
print ('解释度',explained_variance_score(y_train,tree.predict(X_train)))print ("决策树模型评估--验证集:")
print ('验证r^2:',tree.score(X_test,y_test))
print ('均方差',mean_squared_error(y_test,tree.predict(X_test)))
print ('绝对差',mean_absolute_error(y_test,tree.predict(X_test)))
print ('解释度',explained_variance_score(y_test,tree.predict(X_test)))这篇关于【决策树】预测用户用电量的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







