本文主要是介绍Util工具类功能设计与类设计(http模块一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
类功能
类定义
类实现
编译测试
Split分割字符串测试
ReadFile读取测试
WriteFile写入测试
UrlEncode编码测试
UrlDecode编码测试
StatuDesc状态码信息获取测试
ExtMime后缀名获取文件mime测试
IsDirectory&IsRegular测试
VaildPath请求路径有效性判断测试
总编译
补充
trunc截断
编码格式的规定
md5sum校验和比较两个文件是否一致
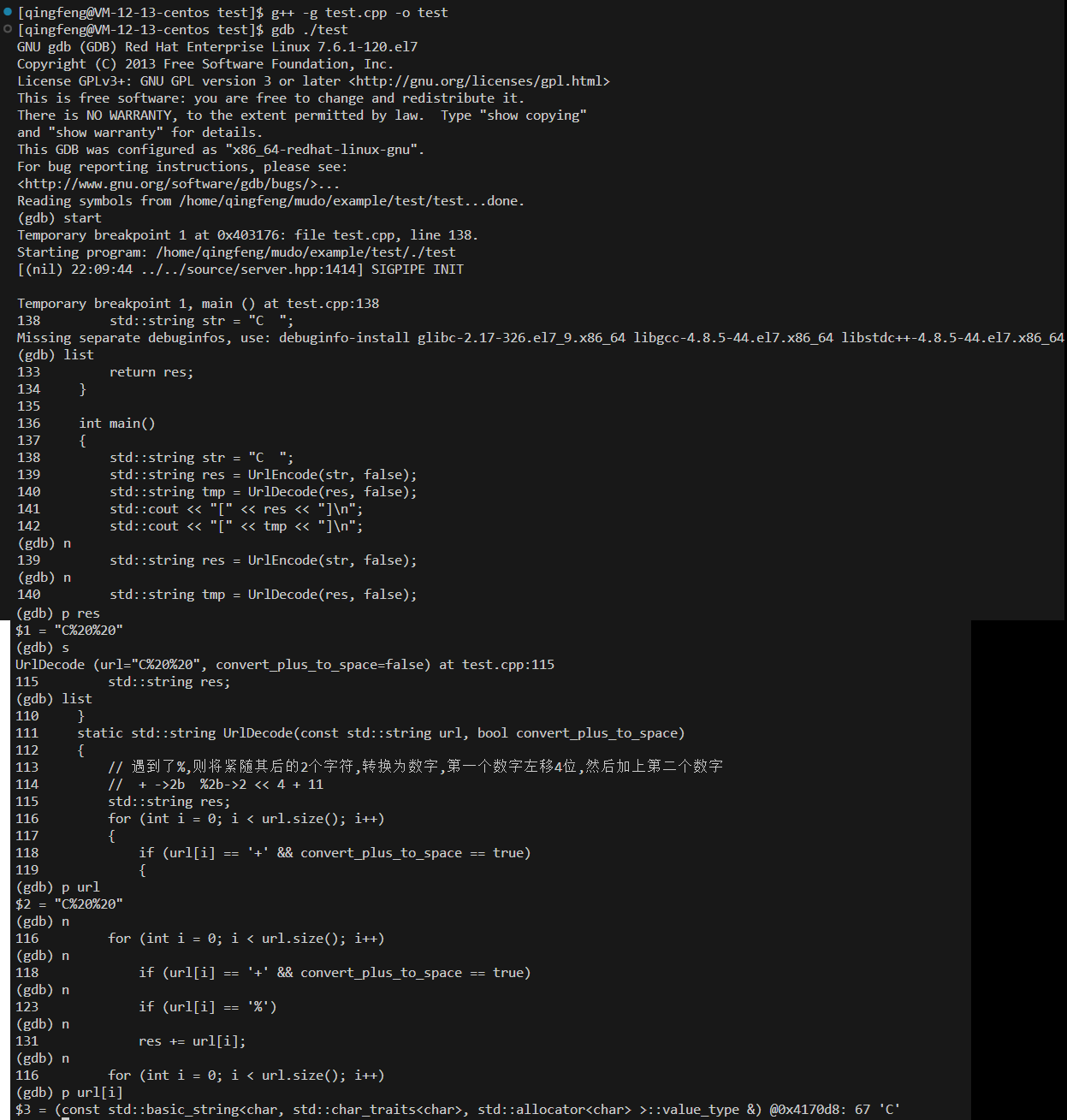
新增gdb调试手法
类功能
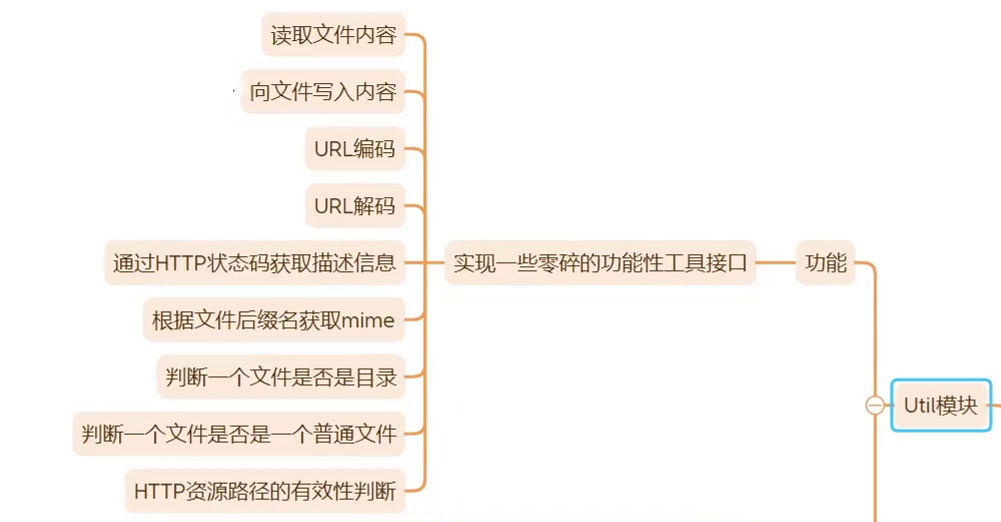
类定义
#include "../server.hpp"class Util{public :// 字符串分割函数size_t Split();// 读取文件内容static bool ReadFile();// 向文件写入数据static bool WriteFile();// URL编码static bool UrlEncode();// URL解码static bool UrlDecode();// 响应状态码的描述信息获取static std::string StatuDesc();// 根据文件后缀名获取文件mimestatic std::string ExtMime();// 判断一个文件是否是一个目录static bool IsDirectory();// 判断一个文件是否是一个普通文件static bool IsRegular();// http请求的资源路径有效性判断static bool VaildPath();
};类实现
#include "../server.hpp"
#include <sys/stat.h>
#include <fstream>class Util
{
public:// 字符串分割函数static size_t Split(const std::string &src, const std::string &sep, std::vector<std::string> *arry){size_t offset = 0;// 有10个字符,offset是查找的起始位置,范围应该是0~9,offset==10就代表已经越界了,返回查找的位置while (offset < src.size()){size_t pos = src.find(sep, offset); // 在src字符串偏移量offset处,开始向后查找sep字符/子串,返回查找到的位置if (pos == std::string::npos) // 没有找到特定的字符{// 将剩余的部分当做一个子串,放入arry中if (pos == src.size())break;arry->push_back(src.substr(offset));return arry->size();}if (pos == offset){offset = pos + sep.size();continue; // 当前字符串是一个空串,没有内容}arry->push_back(src.substr(offset, pos - offset));offset = pos + sep.size();}return arry->size();}// 读取文件的所有内容,将读取到的内容放到一个容器中static bool ReadFile(const std::string &filename, std::string *buf){std::ifstream ifs(filename, std::ios::binary); // 以二进制的方式读取if (ifs.is_open() == false){printf("OPEN %s FILE FAILED!!", filename.c_str());return false;}size_t fsize = 0; // 偏移量ifs.seekg(0, ifs.end); // 跳转读写位置到末尾fsize = ifs.tellg(); // 获取当前读写位置相对于起始位置的偏移量,从末尾偏移量刚好就是文件大小ifs.seekg(0, ifs.beg); // 跳转到起始位置buf->resize(fsize); // 开辟文件大小的空间ifs.read(&(*buf)[0], fsize); // c_str()返回的是一个const,所以不行if (ifs.good() == false){printf("READ %s FILE FAILED!!", filename.c_str());ifs.close();return false;}ifs.close();return true;}// 向文件写入数据static bool WriteFile(const std::string &filename, const std::string &buf){std::ofstream ofs(filename, std::ios::binary | std::ios::trunc);if (ofs.is_open() == false){printf("OPEN %s FILE FAILED!!", filename.c_str());return false;}ofs.write(buf.c_str(), buf.size());if (ofs.good() == false){ERR_LOG("WRITE %s FILE FAILED!", filename.c_str());ofs.close();return false;}ofs.close();return true;}// URL编码,避免URL中资源路径与查询字符串中的特殊字符与HTTP请求中特殊字符产生歧义// 编码格式:将特殊字符的ascii值,转换为两个16进制字符,前缀% C++ -> C%2B%2B// 不编码的特殊字符: RFC3986文档规定 . - _ ~ 字母,数字属于绝对不编码字符// RFC3986文档规定,编码格式 %HH// W3C标准中规定,查询字符串中的空格,需要编码为+, 解码则是+转空格static std::string UrlEncode(const std::string url, bool convert_space_to_plus){std::string res;for (auto &c : url){if (c == '.' || c == '-' || c == '_' || c == '~' || isalnum(c)){res += c;continue;}if (c == ' ' && convert_space_to_plus == true){res += '+';continue;}// 剩下的字符都是需要编码成为 %HH 格式char tmp[4] = {0};// snprintf 与 printf比较类似,都是格式化字符串,只不过一个是打印,一个是放到一块空间中snprintf(tmp, 4, "%%%02X", c);res += tmp;}return res;}static char HEXTOI(char c){if (c >= '0' && c <= '9')return c - '0';else if (c >= 'a' && c <= 'z')return c - 'a' + 10; // 注意要加10,16进制中,字母a从11开始else if (c >= 'A' && c <= 'Z')return c - 'A' + 10;return -1;}// URL解码static std::string UrlDecode(const std::string url, bool convert_plus_to_space){// 遇到了%,则将紧随其后的2个字符,转换为数字,第一个数字左移4位,然后加上第二个数字// + ->2b %2b->2 << 4 + 11std::string res;for (int i = 0; i < url.size(); i++){if (url[i] == '+' && convert_plus_to_space == true){res += ' ';continue;}if (url[i] == '%'){char v1 = HEXTOI(url[i + 1]);char v2 = HEXTOI(url[i + 2]);char v = v1 * 16 + v2;i += 2;continue;}res += url[i];}return res;}// 响应状态码的描述信息获取static std::string StatuDesc(int statu){std::unordered_map<int, std::string> _statu_msg = {{100, "Continue"},{101, "Switching Protocol"},{102, "Processing"},{103, "Early Hints"},{200, "OK"},{201, "Created"},{202, "Accepted"},{203, "Non-Authoritative Information"},{204, "No Content"},{205, "Reset Content"},{206, "Partial Content"},{207, "Multi-Status"},{208, "Already Reported"},{226, "IM Used"},{300, "Multiple Choice"},{301, "Moved Permanently"},{302, "Found"},{303, "See Other"},{304, "Not Modified"},{305, "Use Proxy"},{306, "unused"},{307, "Temporary Redirect"},{308, "Permanent Redirect"},{400, "Bad Request"},{401, "Unauthorized"},{402, "Payment Required"},{403, "Forbidden"},{404, "Not Found"},{405, "Method Not Allowed"},{406, "Not Acceptable"},{407, "Proxy Authentication Required"},{408, "Request Timeout"},{409, "Conflict"},{410, "Gone"},{411, "Length Required"},{412, "Precondition Failed"},{413, "Payload Too Large"},{414, "URI Too Long"},{415, "Unsupported Media Type"},{416, "Range Not Satisfiable"},{417, "Expectation Failed"},{418, "I'm a teapot"},{421, "Misdirected Request"},{422, "Unprocessable Entity"},{423, "Locked"},{424, "Failed Dependency"},{425, "Too Early"},{426, "Upgrade Required"},{428, "Precondition Required"},{429, "Too Many Requests"},{431, "Request Header Fields Too Large"},{451, "Unavailable For Legal Reasons"},{501, "Not Implemented"},{502, "Bad Gateway"},{503, "Service Unavailable"},{504, "Gateway Timeout"},{505, "HTTP Version Not Supported"},{506, "Variant Also Negotiates"},{507, "Insufficient Storage"},{508, "Loop Detected"},{510, "Not Extended"},{511, "Network Authentication Required"}};auto it = _statu_msg.find(statu);if (it != _statu_msg.end()){return it->second;}return "Unknow";}// 根据文件后缀名获取文件mimestatic std::string ExtMime(const std::string &filename){std::unordered_map<std::string, std::string> _mime_msg = {{".aac", "audio/aac"},{".abw", "application/x-abiword"},{".arc", "application/x-freearc"},{".avi", "video/x-msvideo"},{".azw", "application/vnd.amazon.ebook"},{".bin", "application/octet-stream"},{".bmp", "image/bmp"},{".bz", "application/x-bzip"},{".bz2", "application/x-bzip2"},{".csh", "application/x-csh"},{".css", "text/css"},{".csv", "text/csv"},{".doc", "application/msword"},{".docx", "application/vnd.openxmlformats-officedocument.wordprocessingml.document"},{".eot", "application/vnd.ms-fontobject"},{".epub", "application/epub+zip"},{".gif", "image/gif"},{".htm", "text/html"},{".html", "text/html"},{".ico", "image/vnd.microsoft.icon"},{".ics", "text/calendar"},{".jar", "application/java-archive"},{".jpeg", "image/jpeg"},{".jpg", "image/jpeg"},{".js", "text/javascript"},{".json", "application/json"},{".jsonld", "application/ld+json"},{".mid", "audio/midi"},{".midi", "audio/x-midi"},{".mjs", "text/javascript"},{".mp3", "audio/mpeg"},{".mpeg", "video/mpeg"},{".mpkg", "application/vnd.apple.installer+xml"},{".odp", "application/vnd.oasis.opendocument.presentation"},{".ods", "application/vnd.oasis.opendocument.spreadsheet"},{".odt", "application/vnd.oasis.opendocument.text"},{".oga", "audio/ogg"},{".ogv", "video/ogg"},{".ogx", "application/ogg"},{".otf", "font/otf"},{".png", "image/png"},{".pdf", "application/pdf"},{".ppt", "application/vnd.ms-powerpoint"},{".pptx", "application/vnd.openxmlformats-officedocument.presentationml.presentation"},{".rar", "application/x-rar-compressed"},{".rtf", "application/rtf"},{".sh", "application/x-sh"},{".svg", "image/svg+xml"},{".swf", "application/x-shockwave-flash"},{".tar", "application/x-tar"},{".tif", "image/tiff"},{".tiff", "image/tiff"},{".ttf", "font/ttf"},{".txt", "text/plain"},{".vsd", "application/vnd.visio"},{".wav", "audio/wav"},{".weba", "audio/webm"},{".webm", "video/webm"},{".webp", "image/webp"},{".woff", "font/woff"},{".woff2", "font/woff2"},{".xhtml", "application/xhtml+xml"},{".xls", "application/vnd.ms-excel"},{".xlsx", "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"},{".xml", "application/xml"},{".xul", "application/vnd.mozilla.xul+xml"},{".zip", "application/zip"},{".3gp", "video/3gpp"},{".3g2", "video/3gpp2"},{".7z", "application/x-7z-compressed"},};// a.b.txt 获取文件名size_t pos = filename.find_last_of('.');if (pos != std::string::npos)return "application/octet-stream"; // 没找着,表示文件是一个二进制文件// 根据扩展名,获取mimestd::string ext = filename.substr(pos);auto it = _mime_msg.find(ext);if (it == _mime_msg.end())return "application/octet-stream";return it->second;}// 判断一个文件是否是一个目录static bool IsDirectory(const std::string &filename){struct stat st;int ret = stat(filename.c_str(), &st);if (ret < 0)return false;return S_ISDIR(st.st_mode);}// 判断一个文件是否是一个普通文件static bool IsRegular(const std::string &filename){struct stat st;int ret = stat(filename.c_str(), &st);if (ret < 0)return false;return S_ISREG(st.st_mode);}// http请求的资源路径有效性判断// /index.html --- 前边的/叫做相对根目录 映射的是某个服务器上的子目录// 想表达的意思就是,客户端只能请求相对根目录中的资源,其他地方的资源都不予理会// /../login, 这个路径中的..会让路径的查找跑到相对根目录之外,这是不合理的,不安全的static bool VaildPath();
};编译测试
各个函数依次测试功能
Split分割字符串测试

ReadFile读取测试
WriteFile写入测试
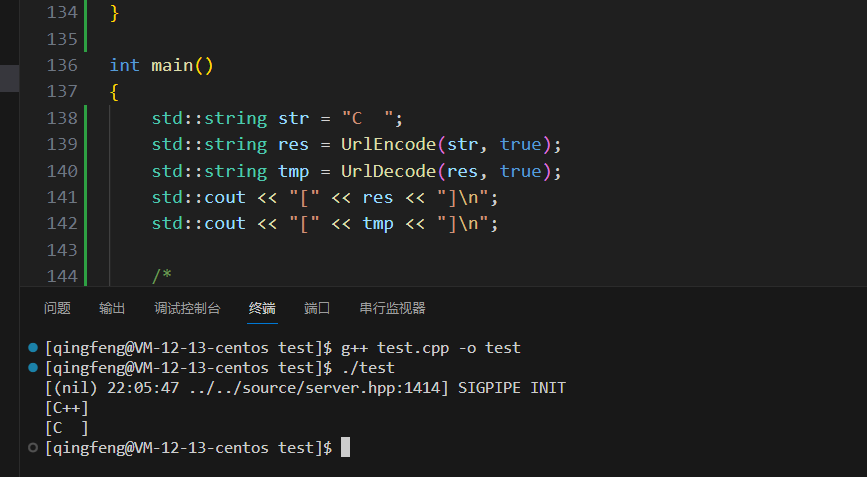
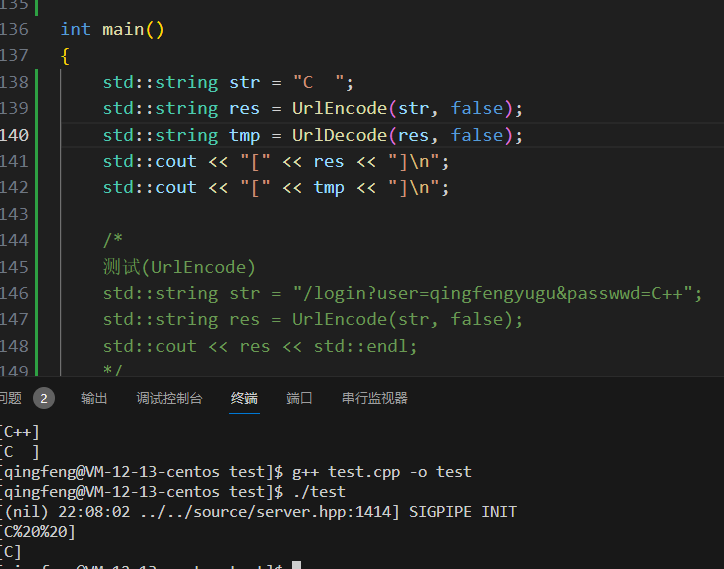
UrlEncode编码测试
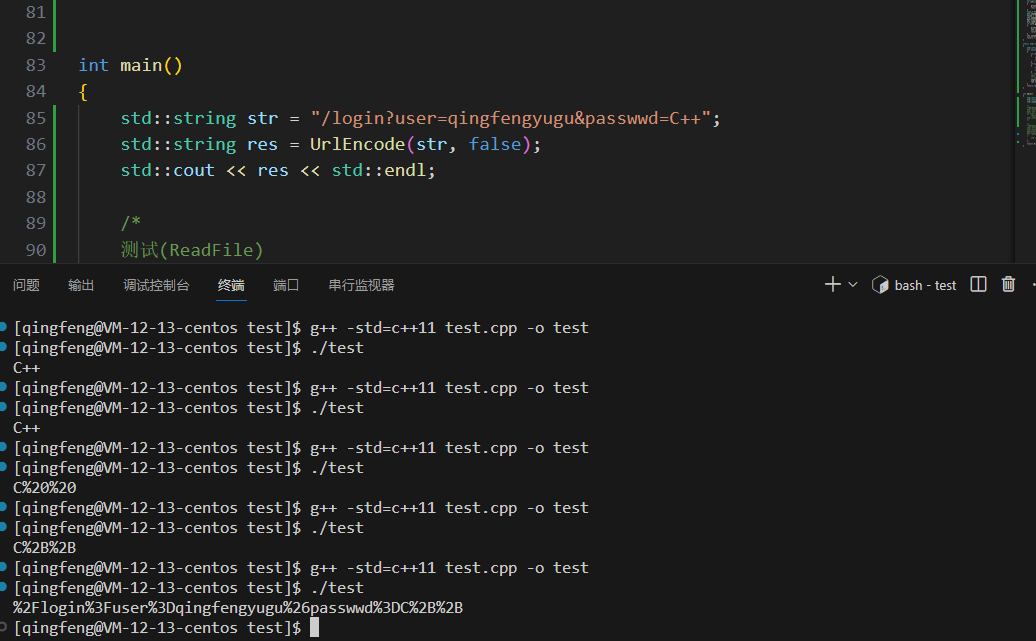
UrlDecode编码测试
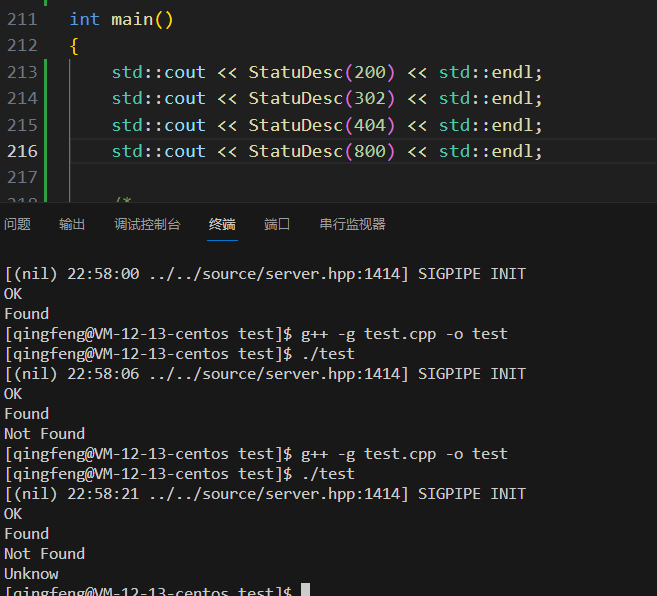
StatuDesc状态码信息获取测试
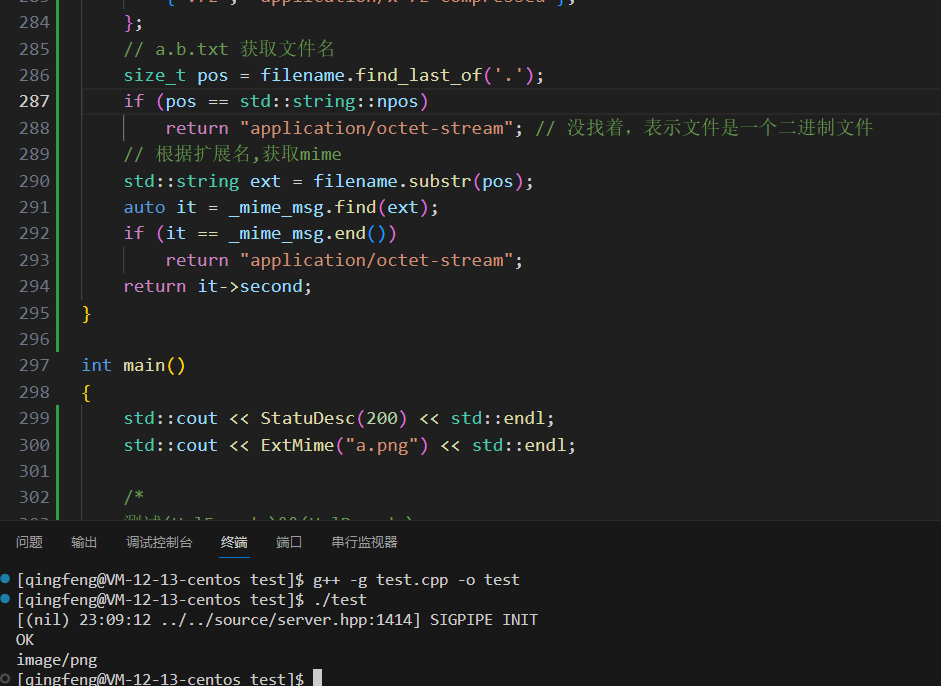
ExtMime后缀名获取文件mime测试
IsDirectory&IsRegular测试

VaildPath请求路径有效性判断测试

总编译

无异常,符合预期
测试案例代码
int main()
{std::cout << VaildPath("/html/../../index.html") << std::endl;/*测试(IsDirectory)&(IsRegular)std::cout << IsRegular("../regex/regex.cpp") << std::endl;std::cout << IsRegular("../regex") << std::endl;std::cout << IsDirectory("../regex/regex.cpp") << std::endl;std::cout << IsDirectory("../regex") << std::endl;*//*测试(StatuDesc)&(ExtMime)std::cout << StatuDesc(200) << std::endl;std::cout << ExtMime("a.png") << std::endl;*//*测试(UrlEncode)&(UrlDecode)std::string str = "C ";std::string res = UrlEncode(str, false);std::string tmp = UrlDecode(res, false);std::cout << "[" << res << "]\n";std::cout << "[" << tmp << "]\n";*//*测试(UrlEncode)std::string str = "/login?user=qingfengyugu&passwwd=C++";std::string res = UrlEncode(str, false);std::cout << res << std::endl;*//*测试(ReadFile)&(ReadFile)std::string buf;bool ret = ReadFile("../eventfd/eventfd.c", &buf);if (ret == false)return false;ret = WriteFile("./ttt.c", buf);if (ret == false)return false;*//*测试(Split)std::string str = "abc,,,";std::vector<std::string> arry;Split(str, ",", &arry);for (auto &s : arry){std::cout << "[" << s << "]\n";}*/return 0;
}补充
trunc截断
参考文献
c++ 输入输出流 ios::out 和ios::trunc有什么区别-CSDN博客
编码格式的规定

md5sum校验和比较两个文件是否一致
参考文献
Linux下使用md5sum计算和检验MD5码 - 知乎 (zhihu.com)
新增gdb调试手法
建议参考文献
GDB调试run和start的区别_gdb start-CSDN博客
gdb 的 s 和 si 指令有什么区别 - CSDN文库
详解gdb常用指令 | CS笔记 (pynote.net)
这篇关于Util工具类功能设计与类设计(http模块一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




