本文主要是介绍【Python】科研代码学习:二 dataclass,pipeline,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【Python】科研代码学习:二 dataclass,pipeline
- 前言
- dataclass
- pipeline
前言
- 后文需要学习一下
transformers库,必要时会介绍其他相关的重要库和方法。 - 主要是从源代码、别人的技术文档学习,会更快些。
dataclass
- Python中的数据类dataclass详解
python中的dataclasses中的field用法实战
一文了解 Python3.7 新特性——dataclass装饰器 - 使用
Tuple存储数据:data = (1, 2, "abc"),获取:data[0] - 使用
Dict存储数据:data = {"name" : "Alice"},获取:data["Alice"] - 使用
namedtuple存储数据:导入from collections import namedtuple,Player = namedtuple('Player', ['name', 'number', 'position', 'age', 'grade']),jordan = Player('Micheal Jordan', 23, 'PG', 29, 'S+'),获取:jordan.name,但数据无法修改 - 使用自定义类存储数据,但在
__init__方法中传参数比较麻烦 - 使用
dataclass存储数据:
导入:from dataclasses import dataclass
声明:
@dataclass
class Player:name: strnumber: intposition: strage: intgrade: strjames = Player('Lebron James', 23, 'SF', 25, 'S')
- 它可以支持
Typing.Any, Typying.List等 ,可以设置默认值,可以数据嵌套,可以传 - 不可变类型:修改
@dataclass(frozen=True)
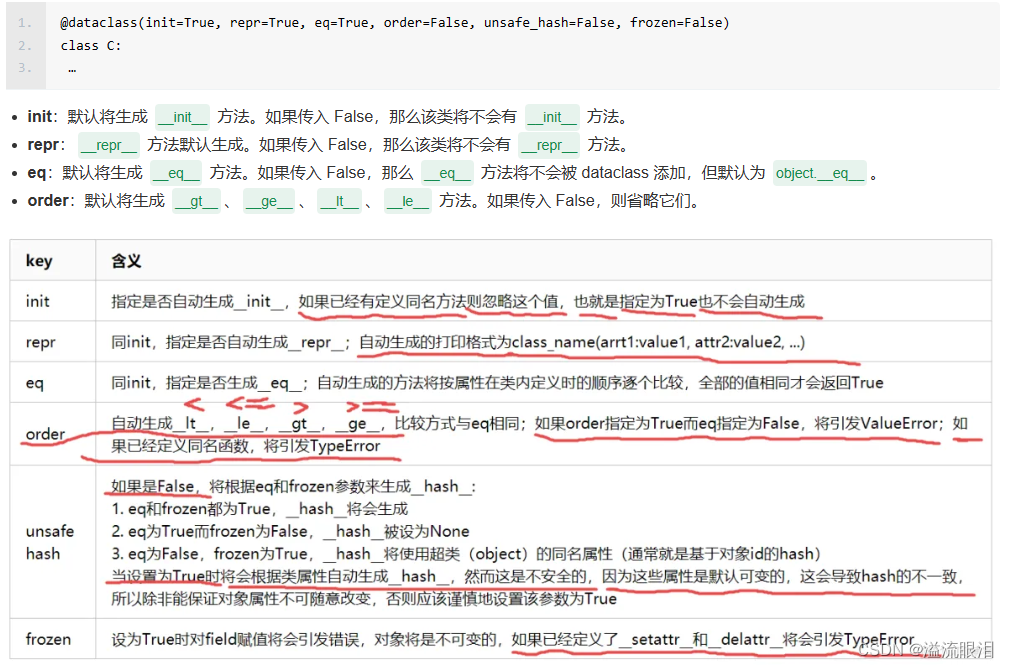
dataclasses.field:数据类的基石
看一下源码:
# This function is used instead of exposing Field creation directly,
# so that a type checker can be told (via overloads) that this is a
# function whose type depends on its parameters.
def field(*, default=MISSING, default_factory=MISSING, init=True, repr=True,hash=None, compare=True, metadata=None):"""Return an object to identify dataclass fields.default is the default value of the field. default_factory is a0-argument function called to initialize a field's value. If initis True, the field will be a parameter to the class's __init__()function. If repr is True, the field will be included in theobject's repr(). If hash is True, the field will be included inthe object's hash(). If compare is True, the field will be usedin comparison functions. metadata, if specified, must be amapping which is stored but not otherwise examined by dataclass.It is an error to specify both default and default_factory."""if default is not MISSING and default_factory is not MISSING:raise ValueError('cannot specify both default and default_factory')return Field(default, default_factory, init, repr, hash, compare,metadata)
- 1)
price : float = 0.0相当于price : float = field(default = '0.0') - 2)
default_factory提供的是一个零参数或全有默认参数的函数,作为初始化。 - 3)
default与default_factory只能二选一 - 4)对于可变对象
mutable类型的(如 list),必须使用filed(default_factory = list)等指定 - 5)
metadata是一个字典,该字典作为额外补充数据,不在dataclasses中使用,是给用户去调用额外的信息的。
其他参数解释:

- 现在再来看一下代码练习(截取了小部分代码)
应该就能看懂了(asdict将obj转成dict,fields相当于一堆 filed)
from dataclasses import asdict, dataclass, field, fields
@dataclass
class TrainingArguments:framework = "pt"output_dir: str = field(metadata={"help": "The output directory where the model predictions and checkpoints will be written."},)overwrite_output_dir: bool = field(default=False,metadata={"help": ("Overwrite the content of the output directory. ""Use this to continue training if output_dir points to a checkpoint directory.")},)do_train: bool = field(default=False, metadata={"help": "Whether to run training."})do_eval: bool = field(default=False, metadata={"help": "Whether to run eval on the dev set."})do_predict: bool = field(default=False, metadata={"help": "Whether to run predictions on the test set."})
pipeline
-
pipeline主要提供了HF模型的简易接口
HF官网-Pipelines
注意:官网左侧修改transformers的版本号,不同版本的API文档自然是有出入的
-
怎么学习调用比较好呢,一个推荐是,在上述官网的API中
我们按照我们需要进行的任务进行索引:
可以看分类索引
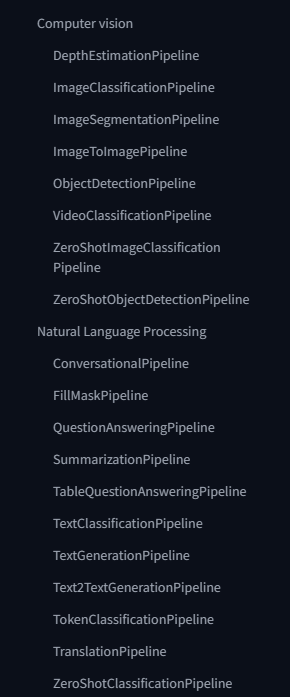
或者 task 参数的介绍
task (str) — The task defining which pipeline will be returned. Currently accepted tasks are:"audio-classification": will return a AudioClassificationPipeline.
"automatic-speech-recognition": will return a AutomaticSpeechRecognitionPipeline.
"conversational": will return a ConversationalPipeline.
"depth-estimation": will return a DepthEstimationPipeline.
"document-question-answering": will return a DocumentQuestionAnsweringPipeline.
"feature-extraction": will return a FeatureExtractionPipeline.
"fill-mask": will return a FillMaskPipeline:.
"image-classification": will return a ImageClassificationPipeline.
"image-feature-extraction": will return an ImageFeatureExtractionPipeline.
"image-segmentation": will return a ImageSegmentationPipeline.
"image-to-image": will return a ImageToImagePipeline.
"image-to-text": will return a ImageToTextPipeline.
"mask-generation": will return a MaskGenerationPipeline.
"object-detection": will return a ObjectDetectionPipeline.
"question-answering": will return a QuestionAnsweringPipeline.
"summarization": will return a SummarizationPipeline.
"table-question-answering": will return a TableQuestionAnsweringPipeline.
"text2text-generation": will return a Text2TextGenerationPipeline.
"text-classification" (alias "sentiment-analysis" available): will return a TextClassificationPipeline.
"text-generation": will return a TextGenerationPipeline:.
"text-to-audio" (alias "text-to-speech" available): will return a TextToAudioPipeline:.
"token-classification" (alias "ner" available): will return a TokenClassificationPipeline.
"translation": will return a TranslationPipeline.
"translation_xx_to_yy": will return a TranslationPipeline.
"video-classification": will return a VideoClassificationPipeline.
"visual-question-answering": will return a VisualQuestionAnsweringPipeline.
"zero-shot-classification": will return a ZeroShotClassificationPipeline.
"zero-shot-image-classification": will return a ZeroShotImageClassificationPipeline.
"zero-shot-audio-classification": will return a ZeroShotAudioClassificationPipeline.
"zero-shot-object-detection": will return a ZeroShotObjectDetectionPipeline.
- 比如说,我需要做文本总结任务,看到有
summarization,然后点击后面的SummarizationPipeline去索引它的用法(Usage):
from transformers import pipeline# use bart in pytorch
summarizer = pipeline("summarization")
summarizer("An apple a day, keeps the doctor away", min_length=5, max_length=20)# use t5 in tf
summarizer = pipeline("summarization", model="google-t5/t5-base", tokenizer="google-t5/t5-base", framework="tf")
summarizer("An apple a day, keeps the doctor away", min_length=5, max_length=20)
- 一个问题是,
model是一个可选参数嘛,有时候默认的模型只能做英文任务,这个时候我可以去 HF 官网,查找需要的模型,传入model参数即可。 - 一个比较重要的参数是
device,设置运行的单卡
device (int, optional, defaults to -1) — Device ordinal for CPU/GPU supports. Setting this to -1 will leverage CPU, a positive will run the model on the associated CUDA device id. You can pass native torch.device or a str too
- 如果想要多卡,那么需要使用
device_map,注意不能和device同时用
device_map (str or Dict[str, Union[int, str, torch.device], optional) — Sent directly as model_kwargs (just a simpler shortcut). When accelerate library is present, set device_map=“auto” to compute the most optimized
-
再看一下源码:

-
所以后续可能要详细看一下:
PreTrainedModel : model 的参数类型
PretrainedConfig : config 的参数类型
PreTrainedTokenizer : tokenizer 的参数类型
以及训练时必用的
Trainer
TrainingArguments
Data Collator
这篇关于【Python】科研代码学习:二 dataclass,pipeline的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





