本文主要是介绍influxdb2.0插入数据字段类型出现冲突问题解决,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、问题出现
一个学校换热站自控系统,会定时从换热站获取测点数据,并插入到influxdb数据库中。influxdb插入数据时,报错提示:
com.influxdb.exceptions.UnprocessableEntityException: failure writing points to database: partial write: field type conflict: input field "HuiYuanZhan.1500.Level_1_H" on measurement "HeatStationData" is type float, already exists as type string dropped=1
问题发生在名为 "HeatStationData" 的测量(measurement)上,其中字段 "HuiYuanZhan.1500.Level_1_H" 的数据类型存在冲突。这个字段在尝试写入时被识别为 float 类型,但它在数据库中已经存在,并且被定义为 string 类型。
InfluxDB 是一个时间序列数据库,它对每个测量中的字段类型有严格的要求。一旦一个字段被定义为某种类型(例如 string),后续写入的数据必须与该类型匹配。如果尝试将不同类型的数据写入同一个字段,InfluxDB 将拒绝写入并抛出错误。
二、查找原因
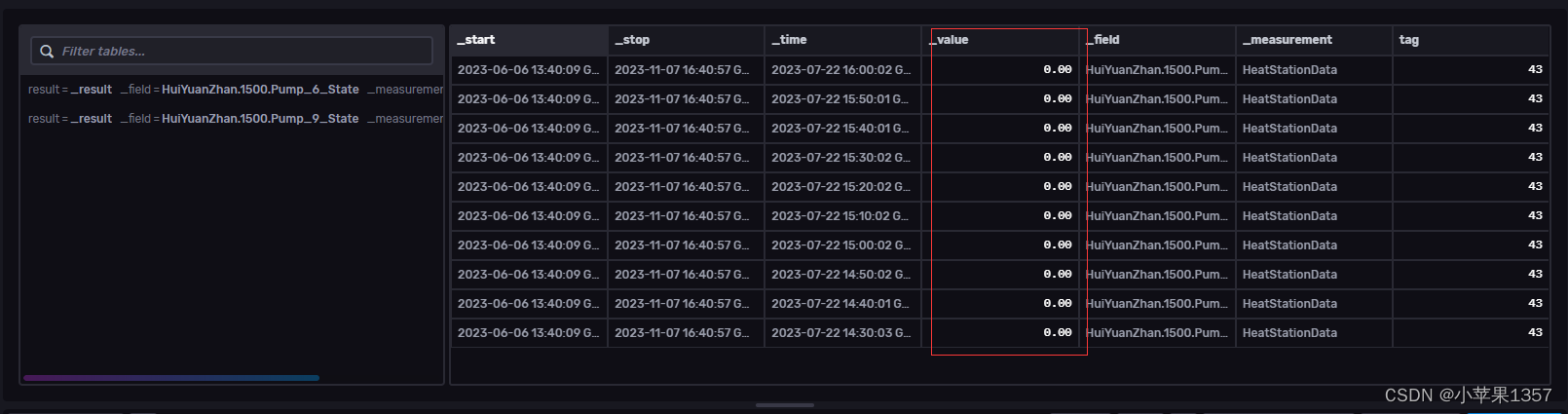
系统设计时,如果发生读取不到或者异常时,读取的空数据,也给了一个字符串的默认值"0.00",保证了哪怕时空数据也有个默认值,但是这与原来字段的数据类型float、integer、boolean等是不一致的。这个字符串的默认空值不知道为啥可以插入进去,有一段时间正好学校现场网络出现问题,导致系统无法读取到换热站的测点数据,数据库里存储了"0.00"的默认值。最近网络问题解决了,系统存取正常值时,报错无法插入了。
三、解决过程思路
1、把出现"0.00"默认值的,这一段时间的数据全部删除掉
influxdb并没有提供直接删除的flux语句,需要使用其他方法
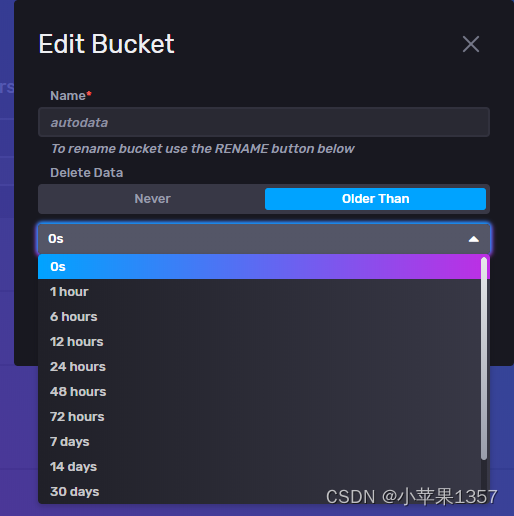
- bucket设置数据过期时间,操作范围是整个数据库的数据
- 命令行界面CLI,使用delete命令删除(我使用的是这种方式)
通过命令操作influxdb时,先要验证权限,这里直接验证token
//权限 设置token:export INFLUX_TOKEN='iCmM46X2GKl2G3rPTtlKHFHljH8tDkWi-e1wpWh_76wlKQ2JDvAqhbhJZz5jdQN4a-iEHT08vSVL4z5S8yUPgw=='influx delete --bucket autodata \--org auto \--start 2023-06-06T00:00:00Z \--stop 2024-03-07T15:16:01Z \--predicate '_measurement = "HeatStationData" and "tag" = "40" '- 访问api接口删除
http://127.0.0.1:8088/api/v2/delete?org=gg&bucket=autocontroldata&precision=s 2、分析代码,找到赋值默认值的代码段,删除掉,改为读取不到数据时,不存储数据库,保证字段的数据类型一致。
问题代码:
for(int i=0;i<dataList.size();i++){Object value = dataList.get(i).getStatusCode().isBad() ? null : dataList.get(i).getValue().getValue();if(!(value instanceof Float)&&!(value instanceof Boolean)){if(value==null||value.equals(0)){value = "0.00";//System.out.println("float:" + value);}else{value = value+".00";//System.out.println("Integer-----------:" + value);}}
}优化代码:opc读取的数据,除了常规数据类型,还有一种UShort数据类型,但在influxdb中是没有的,所以在获取到数据后,需要对这一类型先转化成integer类型。
if(dataList.size()==nodeIdList.size()){for(int i=0;i<dataList.size();i++){/* Variant v = dataList.get(i).getValue();Optional<NodeId> dataType = v.getDataType();*/Object value = dataList.get(i).getStatusCode().isBad() ? null : dataList.get(i).getValue().getValue();if(value==null) {continue;}if(!(value instanceof Float)&&!(value instanceof Boolean)){if(value instanceof UShort){//UShort 转化成Integervalue = ((UShort) value).intValue();}}resultMap.put(nodeIdList.get(i),value);//System.out.println(resultMap.get("get"+nodeIdList.get(i)));}}因为有的时候测点的值可能是0/1/2这样的整型,也可能是1.2/2.5之类的浮点型,这可能是同一个字段的值,但是系统读取到的值会判断为整型和浮点型,这也会导致同一字段存储两种不同类型的值,所以需要再把整型先转化成浮点型,统一全部浮点型存储,避免出现类型不一致情况
//转换数据类型 数值类型都为float---避免数据出现Integer和float的变化(一个字段只能有一种数据类型)Set set = map.keySet();for (Object o : set) {if(map.get(o) instanceof Integer){map.put((String)o,(int)map.get(o)* 1.0f);}}插入数据
try (WriteApi writeApi = influxDBClient.getWriteApi(writeOptions)) {//完整数据组装,包含数据库名称,索引,数据值集合,时间Point point = Point.measurement("HeatStationData").addTag("tag", savetag).addFields(map).time(Instant.now(), WritePrecision.S);//单条记录保存writeApi.writePoint(bucket, org,point);}catch (Exception e){e.printStackTrace();System.out.println("=============插入数据异常============="+new Date()+":"+e.getMessage());}3、删除异常数据类型的数据后,并没有用,插入还是失败,字段的数据类型已经被更改,最后选择迁移数据库,重新穿件新数据库,重新插入数据,将原有旧数据,想办法进行重新迁移
创建新的bucket:
项目配置文件更改要访问的bucket:

最终数据可以重新插入了
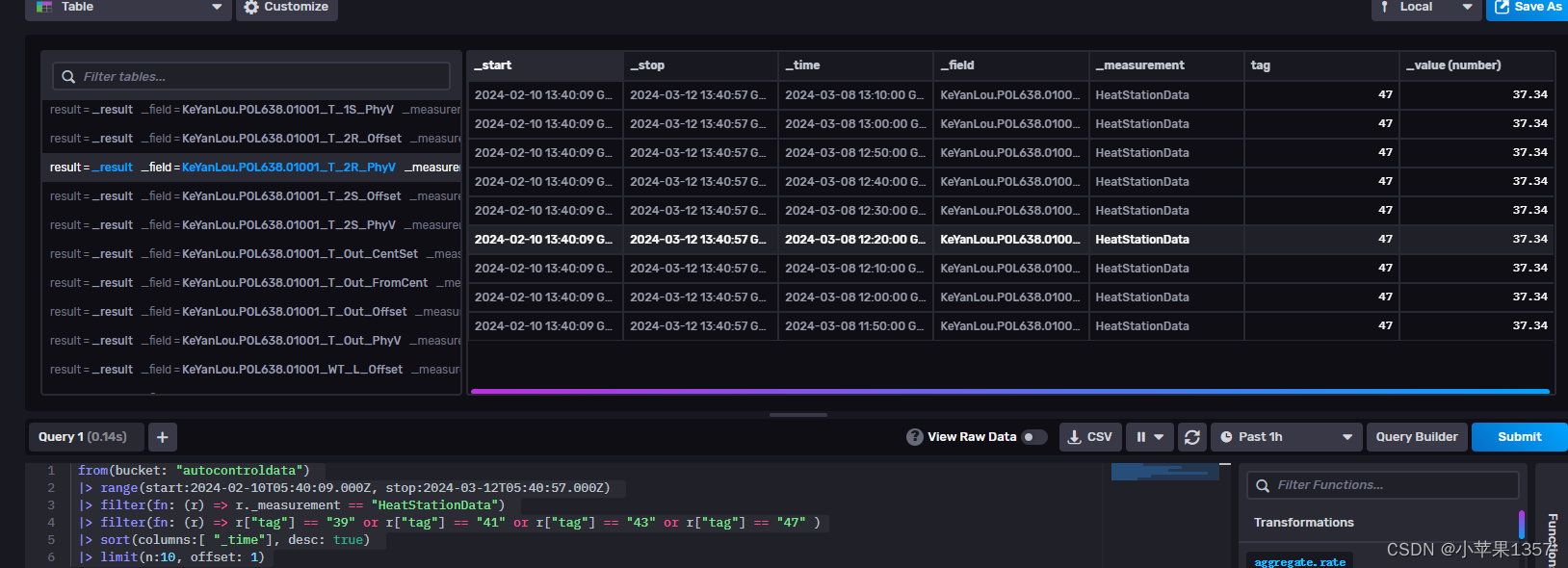
from(bucket: "autocontroldata") |> range(start:2024-02-10T05:40:09.000Z, stop:2024-04-12T05:40:57.000Z) |> filter(fn: (r) => r._measurement == "HeatStationData") |> filter(fn: (r) => r["tag"] == "39" or r["tag"] == "40" or r["tag"] == "41" or r["tag"] == "43" or r["tag"] == "47" )|> sort(columns:[ "_time"], desc: true) |> limit(n:10, offset: 1) 四、总结
一定要避免同一字段中插入不同的数据类型,无论是读取不到数据时,给默认值还是整型和浮点型的类型统一。一定要在代码中做好此类问题的规避,避免再出现这种情况,导致数据无法插入,这种问题会对数据造成巨大损失。
这篇关于influxdb2.0插入数据字段类型出现冲突问题解决的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






