本文主要是介绍图文并茂的讲清楚Linux零拷贝技术,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天我们来聊一聊Linux零拷贝技术,今天我们以一个比较有代表性的技术sendfile系统调用为切入点,详细介绍一下零拷贝技术的原理。
1.零拷贝技术简介
Linux零拷贝技术是一种优化数据传输的技术,它可以减少数据在内核态和用户态之间的拷贝次数,提高数据传输的效率。
在传统的数据传输过程中,数据需要从内核缓冲区拷贝至应用程序的缓冲区,然后再从应用程序缓冲区拷贝到网络设备的缓冲区,最后才能发送出去。
而零拷贝技术通过直接在应用程序和网络设备之间传输数据,避免了中间的拷贝过程,从而提高了数据传输的效率。
Linux零拷贝技术实现方式:
-
sendfile系统调用:sendfile系统调用可以在内核态中直接将文件内容发送到网络设备的缓冲区,避免了数据在用户态和内核态之间的拷贝。
-
splice系统调用:splice系统调用可以将一个文件描述符的数据直接传输到另一个文件描述符,也可以将数据从一个文件描述符传输到网络设备的缓冲区,避免了中间的拷贝过程。
-
mmap和write系统调用:mmap系统调用可以将文件映射到内存中,然后使用write系统调用将内存中的数据直接发送到网络设备的缓冲区,避免了数据在用户态和内核态之间的拷贝。
-
DMA(Direct Memory Access):DMA是一种硬件技术,可以直接将数据从内存传输到网络设备的缓冲区,避免了CPU的介入,提高了数据传输的效率。
2.sendfile系统调用
sendfile系统调用直接在内核中操作文件数据,将数据从源文件描述符复制到目标文件描述符的发送缓冲区,然后通过网络协议栈将数据发送出去。
这样就避免了数据在内核和用户空间之间的复制,提高了传输效率。
sendfile系统调用函数原型:
#include <sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);参数说明:
out_fd:目标文件描述符,用于发送数据。
in_fd:源文件描述符,从该文件读取数据。
offset:指定从源文件的哪个位置开始读取数据,可以为NULL表示从当前位置开始。
count:要传输的字节数。返回值:
成功:返回写入out_fd文件的字节数。
失败:返回-1,并设置errno。3.sendfile实现原理
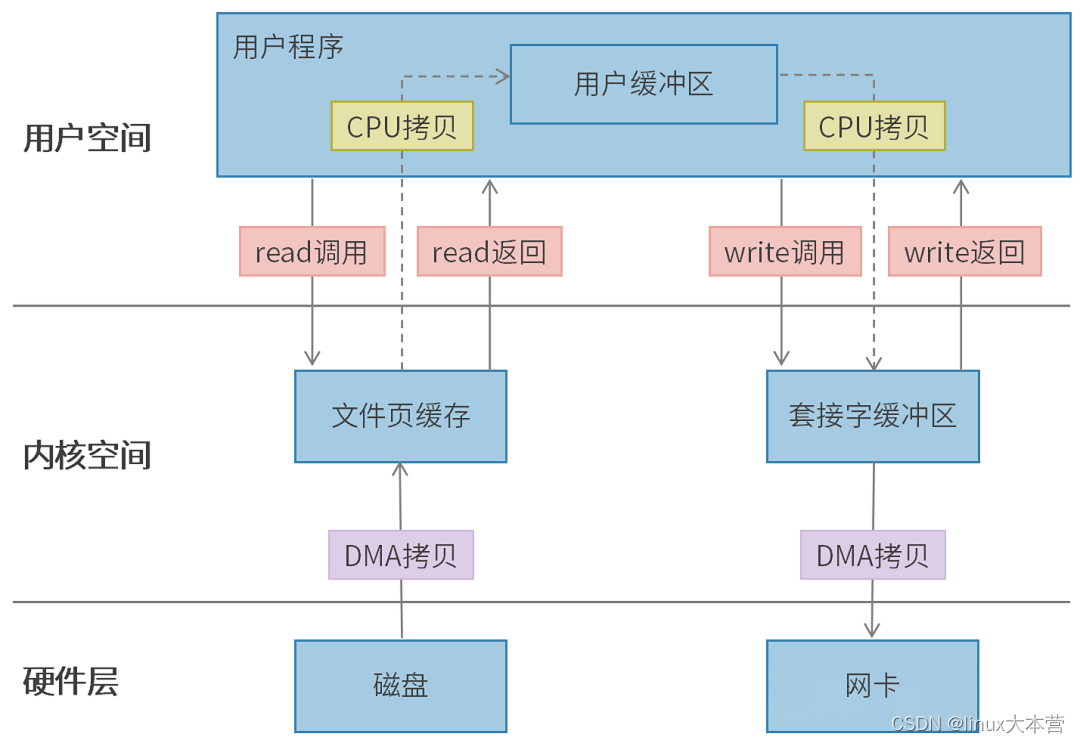
3.1 传统方式发送文件
使用传统方式把一个文件通过socket发送出去,我们需要执行一个比较长的路径。
路径:磁盘->文件页缓存->用户缓冲区->套接字缓冲区->网卡。
上下文切换和内存拷贝情况如下:
-
上下文切换:4次(read调用,read返回,write调用,write返回)
-
DMA拷贝:2次
-
CPU拷贝:2次(文件页缓存->用户缓冲区,用户缓冲区->套接字缓冲区)
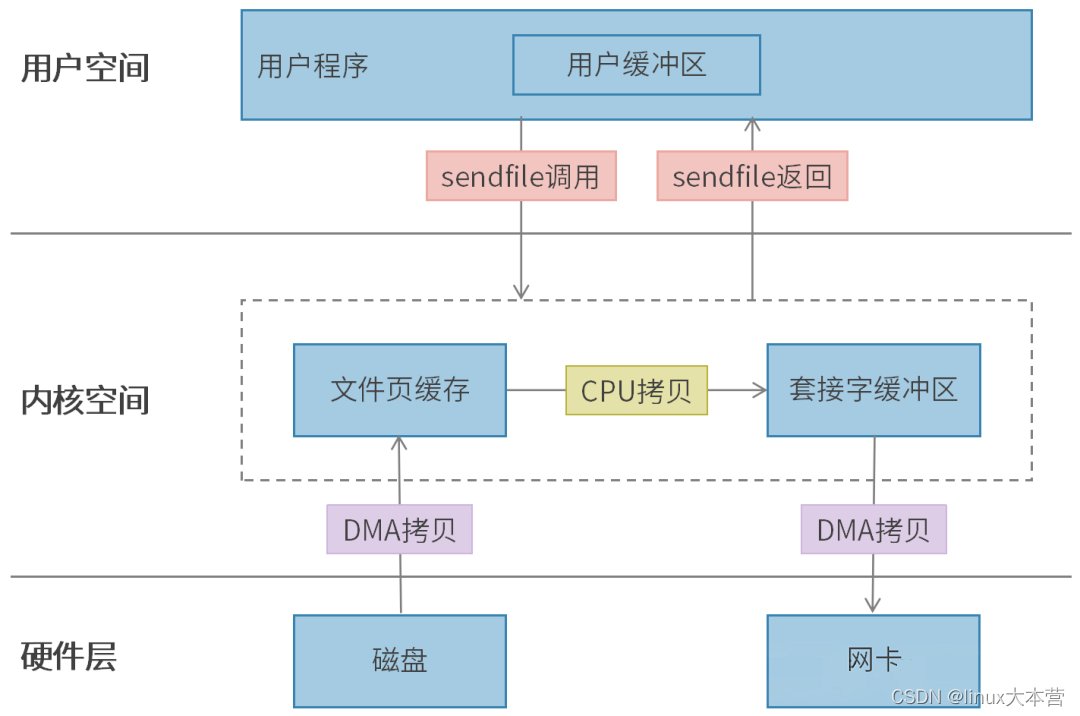
3.2 sendfile发送文件
使用sendfile发送文件,相对来说整个路径会短一些。
路径:磁盘->文件页缓存->套接字缓冲区->网卡。
上下文切换和内存拷贝情况如下:
上下文切换:2次(sendfile调用,sendfile返回)
DMA拷贝:2次
CPU拷贝:1次(文件页缓存->套接字缓冲区)
3.3 sendfile实现原理
sendfile实现的核心是管道,管道在Linux系统中应用的比较多,比如说通过管道实现进程间通信。
当需要将文件数据拷贝至socket缓冲区时,会临时创建一个管道(环形缓冲区),将文件数据先拷贝至管道,再将管道数据迁移至socket缓冲区,数据迁移并不是数据拷贝,只是将指针指向内存地址。

3.4 小节
通过采用sendfile发送文件,可以减少2次上下文切换和1次CPU拷贝,如果我们的实际应用场景是需要进行大量的文件发送,采用sendfile能够很大程度上提高系统性能。
相关视频推荐
2024年c/c++程序员如何提升自己的核心竞争力?这套linux c/c++后端服务器开发技术教程不要错过!![]() https://www.bilibili.com/video/BV1CF4m1L7hU/
https://www.bilibili.com/video/BV1CF4m1L7hU/
Linux C/C++开发(后端/音视频/游戏/嵌入式/高性能网络/存储/基础架构/安全)
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

4.管道
4.1 管道简介
管道在Linux系统中应用很广泛,除了零拷贝技术使用到管道,进程间通信同样使用到管道,那么管道到底是什么?

管道是什么?
管道其实就是一个环形缓冲区,通过管道可以将数据从一个文件拷贝另外一个文件。
管道由struct pipe_inode_info结构体定义,该数据结构有4个重要成员:
-
pipe_buffer:管道缓冲区数组,一个固定长度的数组,每个数组成员都是一个缓冲区,对应一个struct pipe_buffer结构。
-
head:头部序号,表示当前可写缓冲区的位置,需要配合mask使用。
-
tail:尾部序号,表示当前可读缓冲区的位置,需要配合mask使用。
-
ring_size:管道缓冲区数组长度,ring_size - 1计算出mask,head & mask获取当前可写缓冲区数组下标,tail & mask获取当前可读缓冲区数组下标。
管道缓冲区由struct pipe_buffer定义,该结构有3个重要成员:
-
page:页指针
-
offset:数据在页中偏移
-
len:数据长度
管道已满或为空判断?
管道已满判断:
head - tail >= ring_size,表示管道已满。
管道为空判断:
head == tail,表示管道为空。
相关结构体定义
struct pipe_inode_info是Linux内核中用于管道文件的数据结构。它定义在include/linux/pipe_fs_i.h头文件中。
pipe_inode_info结构体的定义如下:
struct pipe_inode_info {unsigned int head; //头部序号unsigned int tail; //尾部序号unsigned int max_usage; //最大使用量unsigned int ring_size; //缓冲区数组大小unsigned int nr_accounted; //已使用缓冲区数量struct pipe_buffer *bufs; //缓冲区数组......
}struct pipe_buffer是Linux内核中用于管道(pipe)缓冲区的数据结构。它定义在include/linux/pipe_fs_i.h头文件中。
4.2 管道写
通过head & mask获取缓冲区数组下标,将数据写入pipe_buffer对应的内存页,数据起始位置为offset偏移值,写入的数据长度记录在len成员中。
完成数据写操作后,head头部序号增加1,指向下一个可写位置。

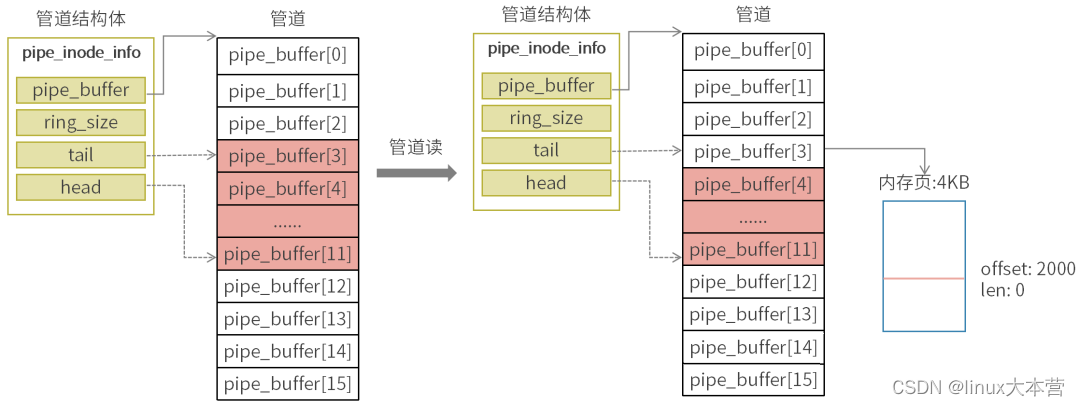
4.3 管道读
通过tail & mask获取缓冲区数组下标,将数据从pipe_buffer对应的内存页读取出来,数据起始位置为offset偏移值,读取数据长度不能大于len记录的数据长度。
完成数据读操作后,len设置成0,pipe_buffer被清空,tail尾部序号增加1,指向下一个可读位置。
5.总结
相比于传统的数据传输技术,零拷贝技术能够大大提高系统性能,在实际项目开发中,我们可以选择符合项目特点的零拷贝技术,以最低的成本提高系统性能。
这篇关于图文并茂的讲清楚Linux零拷贝技术的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



