本文主要是介绍基于OpenCV的图形分析辨认05(补充),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、前言
二、实验内容
三、实验过程
一、前言
编程语言:Python,编程软件:vscode或pycharm,必备的第三方库:OpenCV,numpy,matplotlib,os等等。
关于OpenCV,numpy,matplotlib,os等第三方库的下载方式如下:
第一步,按住【Windows】和【R】调出运行界面,输入【cmd】,回车打开命令行。
第二步,输入以下安装命令(可以先升级一下pip指令)。
pip升级指令:
python -m pip install --upgrade pip
opencv库的清华源下载:
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
numpy库的清华源下载:
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
matplotlib库的清华源下载:
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
os库的清华源下载:
pip install os -i https://pypi.tuna.tsinghua.edu.cn/simple
二、实验内容
对提取出来的人脸特征数据集进行分类,使用MATLAB软件构建SVM支持向量机用于分类。
三、实验过程
以下是提取好的人脸特征数据集,分别用LBP和LDP在全局和局部情况下提取出来的。每一种提取方法下都是训练集和测试集。

特征数据集格式如下,其他一致:
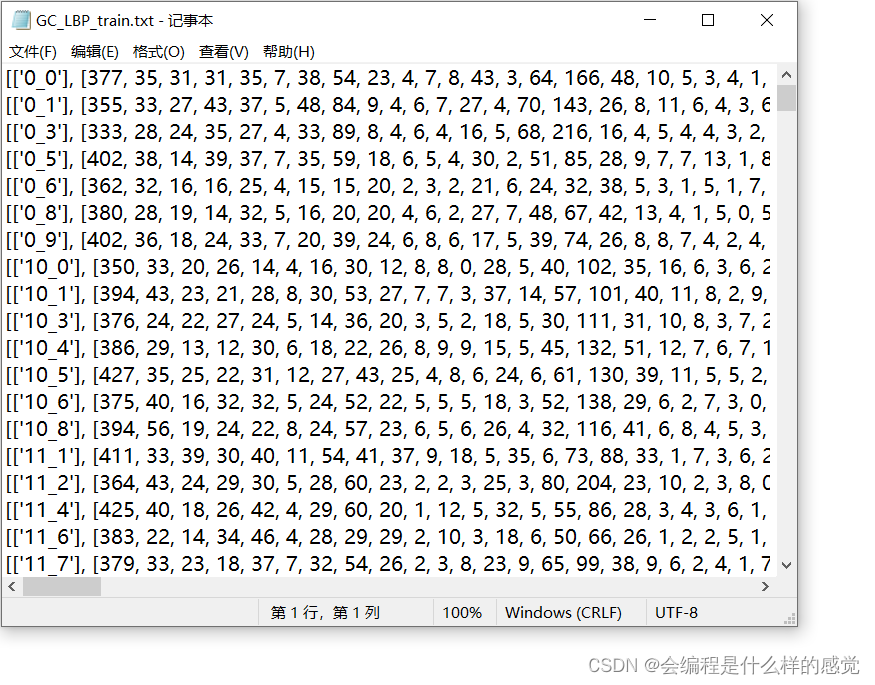
使用SVM检验识别的准确率(MATLAB软件):
导入训练数据和测试数据,分别将其归一化处理,创建SVM模型,并结合网格搜索法对训练数据进行训练,模型训练好以后,用于分类测试数据,并得到结果。MATLAB代码如下:
%% I. 清空环境变量
clc;clear ;close all%% II. 导入数据
% 选择需要的训练文件和测试文件
% data_train = importdata('D:\Image\GC_LBP_train.txt');
% data_test = importdata('D:\Image\GC_LBP_test.txt');
% data_train = importdata('D:\Image\GC_LDP_train.txt');
% data_test = importdata('D:\Image\GC_LDP_test.txt');
% data_train = importdata('D:\Image\LC_LBP_train.txt');
% data_test = importdata('D:\Image\LC_LBP_test.txt');
% data_train = importdata('D:\Image\LC_LBP_train.txt');
% data_test = importdata('D:\Image\LC_LBP_test.txt');
train_data = [];
for i = 1:322data1 = data_train{i, 1};data1_1 = data1(11:end-1);data_num = str2num(data1_1);train_data = [train_data;data_num];
end
AA = repmat(1:46,7);
AA = AA(1:322)';
train_data(:,257) = AA;
%% 读取测试文件
test_data = [];
for i = 1:138data2 = data_test{i, 1};data2_1 = data2(11: end-1);data_num_2 = str2num(data2_1);test_data = [test_data; data_num_2];
end
BB = repmat(1:46,3);
BB = BB(1:138)';
test_data(:,257) = BB;%%
% 训练集
train_matrix = train_data(:,(1:256));%训练集特征
train_label = train_data(:,257);%训练集标签%%
% 测试集
test_matrix = test_data(:,(1:256));%测试集特征
test_label = test_data(:,257);%测试集特征%% III. 数据归一化
[Train_matrix,PS] = mapminmax(train_matrix',0,1);%归一化到-1至1之间
Train_matrix = Train_matrix';
Test_matrix = mapminmax('apply',test_matrix',PS);
Test_matrix = Test_matrix';%% IV. SVM创建/训练(RBF核函数)
%%
% 寻找最佳c/g参数——交叉验证方法
[c,g] = meshgrid(-10:0.2:10,-10:0.2:10);
[m,n] = size(c);
cg = zeros(m,n);
eps = 10^(-4);
v = 5;
bestc = 1;
bestg = 0.1;
bestacc = 0;
%%
for i = 1:mfor j = 1:ncmd = ['-v ',num2str(v),' -t 2',' -c ',num2str(2^c(i,j)),' -g ',num2str(2^g(i,j))];%Train_matrix矩阵的行列需要转至 -c损失函数、惩罚因子cg(i,j) = svmtrain(train_label,Train_matrix,cmd); if cg(i,j) > bestaccbestacc = cg(i,j);bestc = 2^c(i,j);bestg = 2^g(i,j);end if abs( cg(i,j)-bestacc )<=eps && bestc > 2^c(i,j) bestacc = cg(i,j);bestc = 2^c(i,j);bestg = 2^g(i,j);end end
end
cmd = [' -t 2',' -c ',num2str(bestc),' -g ',num2str(bestg)];%%
% 创建/训练SVM模型
model = svmtrain(train_label,Train_matrix,cmd);%% V. SVM仿真测试
[predict_label_1,accuracy_1,decision_values1] = svmpredict(train_label,Train_matrix,model);
[predict_label_2,accuracy_2,decision_values2] = svmpredict(test_label,Test_matrix,model);
result_1 = [train_label predict_label_1];
result_2 = [test_label predict_label_2];%% VI. 绘图
figure
plot(1:length(test_label),test_label,'r-*')
hold on
plot(1:length(test_label),predict_label_2,'b:o')
grid on
legend('真实类别','预测类别')
xlabel('测试集样本编号')
ylabel('测试集样本类别')
string = {'测试集SVM预测结果对比(RBF核函数)';['accuracy = ' num2str(accuracy_2(1)) '%']};
title(string)在分类结果上,会呈现训练集准确率100%,而测试集的准确率较低,说明SVM模型对训练集的提取效果较好,但用于测试集的效果较差,存在欠拟合情况,可能原因有在处理过程中,交叉验证的参数设置较小,导致模型训练的并不是很好,但较大的交叉验证参数会到模型训练时间过长。所以需要改进寻优方式,可以选择粒子群优化算法或者是遗传优化算法改进模型寻优过程,以寻求用较短的训练时间找到较为优异的分类情况。
都看到最后了,确定不点个赞吗?
这篇关于基于OpenCV的图形分析辨认05(补充)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








