本文主要是介绍GreptimeDB v0.7 发布 — 全面支持云原生监控场景,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
就在上周,我们公布了 GreptimeDB 2024 路线图,揭示了今年 GreptimeDB 的几个重大版本计划。随着三月初春的到来,首个适用于生产级别的 GreptimeDB 开源版也在万物复苏的“惊蛰”时节如约而至。v0.7 版本标志着我们向生产就绪版本迈出的重要一步,我们欢迎社区的每一位成员积极参与使用,并提供宝贵的反馈意见。
从 v0.6 到 v0.7,Greptime 团队取得了显著的进步:累计合并了 184 个 Commits,修改了 705 个文件,包括 82 项功能增强、35 项 Bug 修复、19 次代码重构,以及大量的测试工作。 这期间,一共有 8 名独立贡献者参与 GreptimeDB 的代码贡献,特别感谢 Eugene Tolbakov 作为 GreptimeDB 首位 committer,持续活跃在 GreptimeDB 的代码贡献中,和我们一同成长!
更新重点(省流版)Metric Engine:针对可观测场景设计的全新引擎可被推荐使用,能处理大量的小表,适合云原生监控场景;Region Migration:优化了使用体验,可以通过 SQL 方便地执行 Region 迁移;Inverted Index:高效定位用户查询所涉及数据段,显著减少扫描数据文件所需 IO 操作,加速查询过程。
v0.7 是 GreptimeDB 开源以来少数几次的重大版本更新之一,此次我们也将在视频号直播。了解更多功能细节、观看 demo 演示,或者和我们核心开发团队深入交流,欢迎参与下周四(3 月 14 日)晚 19:30 的直播。
Region Migration
Region Migration 提供在 Datanode 之间迁移数据表的 Region 的能力,借助这个能力,我们可以容易地实现热点数据迁移,以及负载平衡的水平扩展。GreptimeDB 在发布 v0.6 时曾提到初步实现了 Region Migration,此次版本更新完善并优化了使用体验。
现在,我们可以通过 SQL 方便地执行 Region 迁移:
select migrate_region(region_id,from_dn_id,to_dn_id,[replay_timeout(s)]);
Metric Engine
Metric Engine 是针对可观测场景来设计的一个的全新引擎,它的主要目标是能处理大量的小表,特别适合云原生监控比如使用 Prometheus 的场景。通过利用合成的宽表,这个新的 Engine 提供指标数据存储和元数据复用的能力,“表”在它之上变得更轻量,它可以克服现有 Mito 引擎的表过于重量级的一些限制。

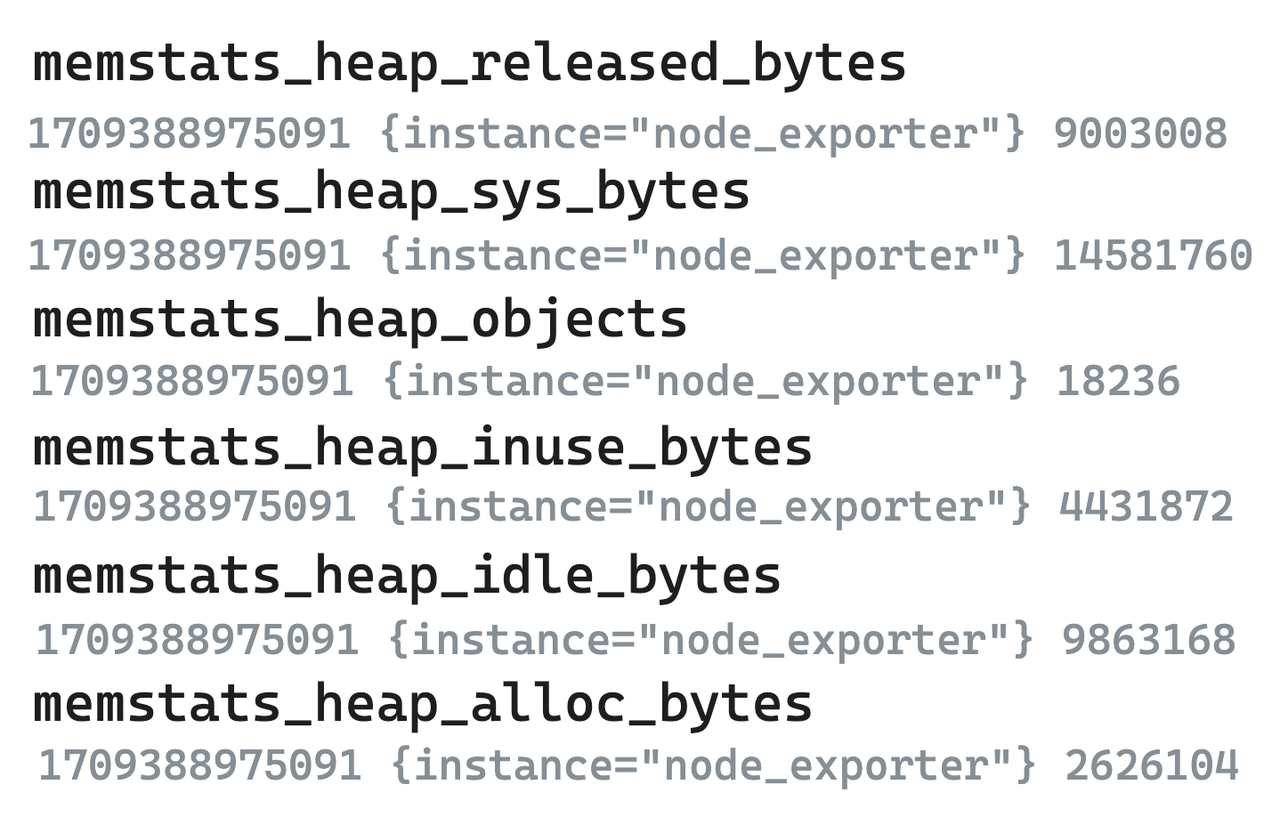
- 图例 - 原始 Metric 数据
- 以下六个 Node Exporter 的 Metrics 为例。在 Prometheus 为代表的单值模型系统中,即使是关联度很高的指标也需要拆成若干个分开存储。
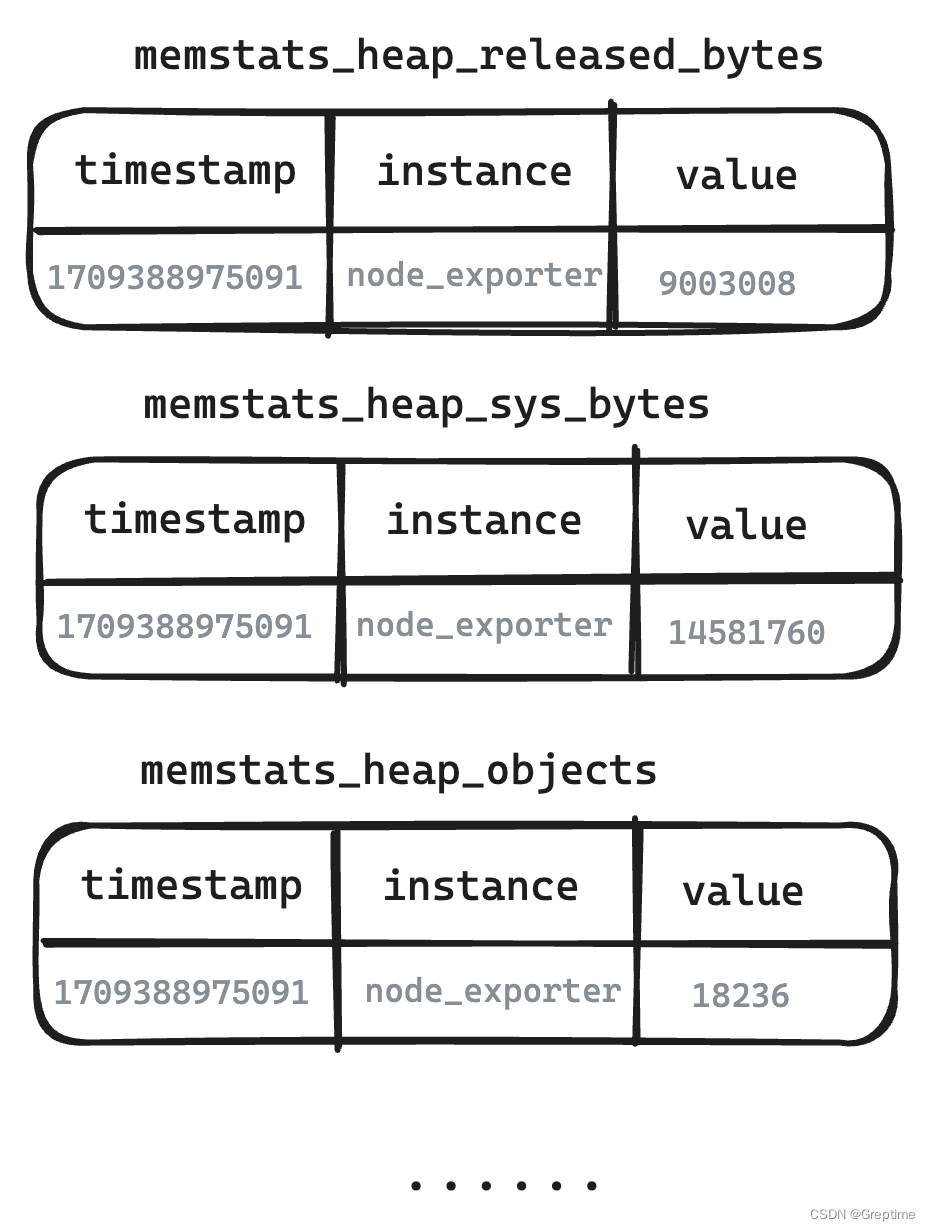
- 图例 - 用户视角的逻辑表
- Metric Engine 原汁原味地还原了 Metrics 的结构,用户见到的就是写入的 Metrics 结构。
-
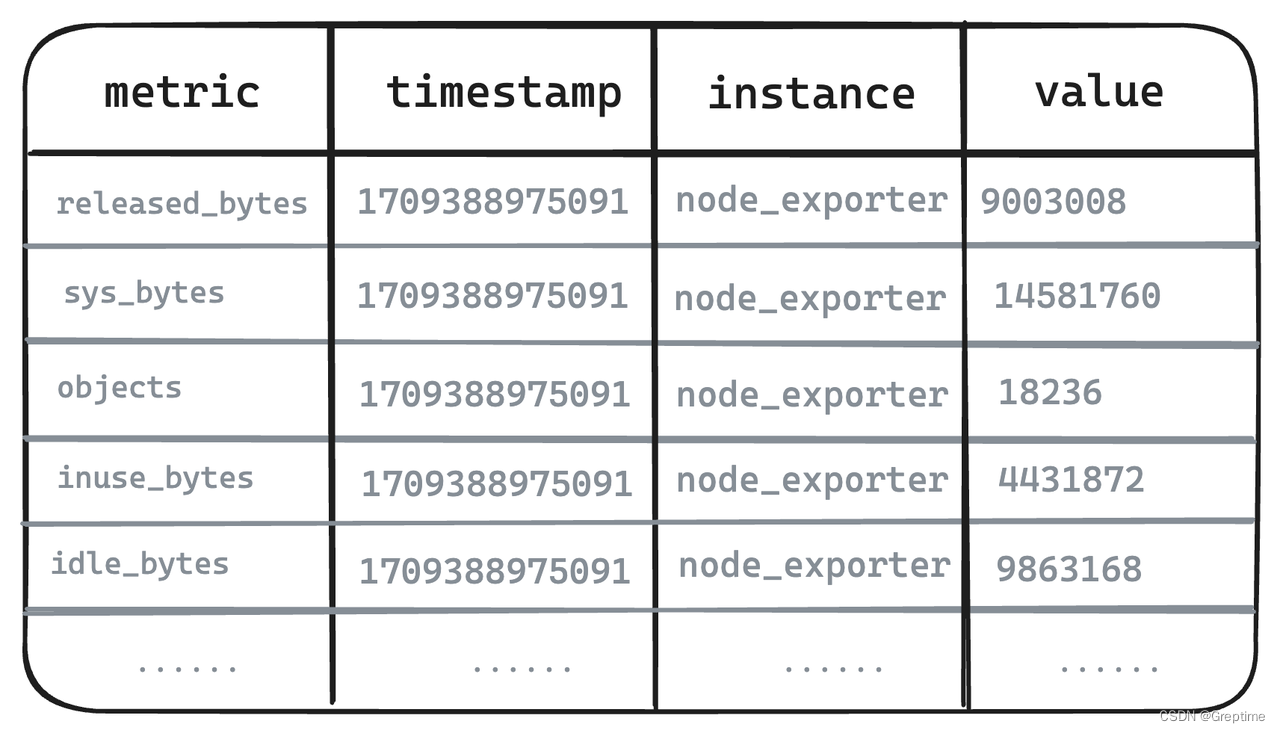
- 图例 - 存储视角的物理表
- 在存储层,Metric Engine 进行了映射,使用一张物理表来存储相关的数据,能够降低存储成本,并支撑更大规模的 Metrics 存储。
-
- 图例 - 接下来的研发计划:Fields 自动分组
- 在实际场景产生的 Metrics 中,大部分都是有关联性的。GreptimeDB 可以自动推导相关的指标并放合并到一起,不仅能跨 Metrics 减少时间线的数量,而且对于关联查询也很友好。

- 存储成本优化
- 基于 AWS S3 存储后端进行成本测试,各写入约三十分钟的时长的数据,总和写入量约 30w row/s 。统计过程中的各个操作发生的次数,根据 AWS 的报价估算成本。测试过程中 index 功能均开启。
报价参考 https://aws.amazon.com/s3/pricing/ 的 Standard 等级
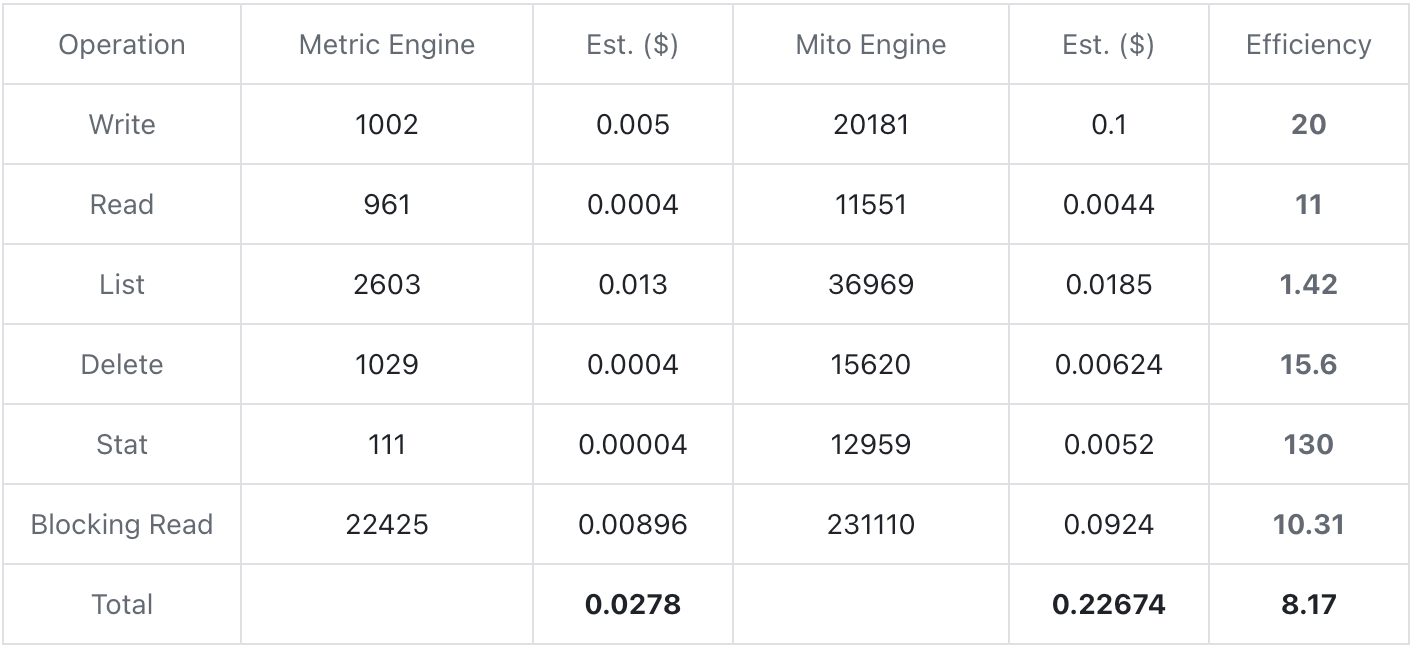
从上述测试表格可以看到,Metric Engine 能够通过减少物理表的数量大幅降低存储成本,各阶段操作次数均有数量级减少,折算的综合成本相比 Mito Engine 能降低八倍以上。
Inverted Index
Inverted Index 作为新引入的索引模块,旨在高效定位用户查询所涉及数据段,显著减少扫描数据文件所需 IO 操作,加速查询过程。TSBS 测试场景下场景性能平均提升 50%,部分场景性能提升近 200%。Inverted Index 的核心优势包括:
1. 开箱即用:系统自动生成合适的索引,用户无需额外指定;
2. 功能实用:支持多列列值的等值、范围和正则匹配,确保在多数场景下都能迅速定位和过滤数据;
3. 灵活适应:自动调控内部参数以平衡构建成本和查询效率,有效应对不同场景的索引需求
- 图例 - Inverted Index 的逻辑表示及数据定位过程
-
用户在多个列指定过滤条件,经过 Inverted Index 的快速定位,能排除掉大部分不匹配的数据段,最终得到较少的待扫描数据段,实现查询加速。

其他更新
1. 数据库的管理功能得到显著增强
我们对 information_schema 表进行了大幅补充,新增了 SCHEMATA 和 PARTITIONS 等信息。此外,新版本引入了众多新的 SQL 函数以实现对 DB 的管理操作。例如,现在通过 SQL 即可触发 Region Flush、执行 Region 迁移,还可以查询 procedure 的执行状态等。
2. 性能提升
在 v0.7 版本中,对 Memtable 进行了重构,提升了数据扫描速度并降低了内存占用。同时,我们针对对象存储的读写性能也做了许多的改进和优化。
升级指南
由于新版本存在一些重大变更,本次 v0.7 发布需要停机升级,推荐使用官方升级工具,大致升级流程如下:
- 创建一个全新的 v0.7 集群
- 关闭旧集群流量入口(停写)
- 通过 GreptimeDB CLI 升级工具导出表结构和数据
- 通过 GreptimeDB CLI 升级工具导入数据到新集群
- 入口流量切换至新集群
详细升级指南请参考:
-
中文:https://docs.greptime.cn/user-guide/upgrade
-
英文:https://docs.greptime.com/user-guide/upgrade
未来展望
我们下一个重要的里程碑在四月份,届时将推出 v0.8 版本。这一版本将引入 GreptimeFlow,一款优化的流计算方案,专门用于 GreptimeDB 数据流中执行连续聚合操作。考虑到灵活性的需求,GreptimeFlow 既可以集成进 GreptimeDB 计算层共同部署,也能作为独立服务部署。
除了功能层面的不断升级,我们在版本性能方面也在持续进行优化,v0.7 版本的性能虽然对比之前已经有了巨大的提升,但在可观测场景下距离部分主流方案还有一些差距,这也将是我们接下来的重点优化方向。
欢迎阅读 GreptimeDB Roadmap 2024,全面了解我们全年的版本更新计划。也欢迎各位参与代码贡献或功能、性能的反馈和讨论,让我们携手见证 GreptimeDB 持续的成长与精进。
关于 Greptime:
Greptime 格睿科技致力于为智能汽车、物联网及可观测等产生大量时序数据的领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前主要有以下三款产品:
- GreptimeDB 是一款用 Rust 语言编写的时序数据库,具有分布式、开源、云原生和兼容性强等特点,帮助企业实时读写、处理和分析时序数据的同时降低长期存储成本。
- GreptimeCloud 可以为用户提供全托管的 DBaaS 服务,能够与可观测性、物联网等领域高度结合。
- GreptimeAI 是为 LLM 应用量身定制的可观测性解决方案。
- 车云一体解决方案是一款深入车企实际业务场景的时序数据库解决方案,解决了企业车辆数据呈几何倍数增长后的实际业务痛点。
GreptimeCloud 和 GreptimeAI 已正式公测,欢迎关注公众号或官网了解最新动态!对企业版 GreptimDB 感兴趣也欢迎联系小助手(微信搜索 greptime 添加小助手)。
官网:https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
文档:https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://www.greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime
这篇关于GreptimeDB v0.7 发布 — 全面支持云原生监控场景的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


