本文主要是介绍ODS概念总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概念
DB(Database)数据库
ODS(Operational Data Store)运营数据存储
DW(Data Warehouse)数据仓储
DM(Data Market)数据集市
ODS产生背景
人们对数据的处理行为可以划分为事务型数据处理(OLTP,On-Line Transaction Processing)和分析型数据处理(OLAP,On-Line Analytic Processing)。
事务型数据处理一般放在传统的数据库(Database,DB)中进行,分析型数据处理则需要在数据仓库(Data Warehouse,DW)中进行。但是有些操作型处理并不适合放在传统的数据库上完成,也有些分析型处理不适合在数据仓库中进行,这时候就需要第三种数据存储体系,操作数据存储(Operational Data Store,ODS)系统就因此产生。它的出现,也将DB&DW两层数据架构转变成DB&ODS&DW三层数据架构。
ODS 数据的基本特征
ODS中的数据具有以下4个基本特征:
①. 面向主题的:进入ODS的数据是来源于各个操作型数据库以及其他外部数据源,数据进入ODS前必须经过 ETL过程(抽取、清洗、转换、加载等)。
②. 集成的:ODS的数据来源于各个操作型数据库,同时也会在数据清理加工后进行一定程度的综合。
③. 可更新的:可以联机修改。这一点区别于数据仓库
④. 当前或接近当前的:“当前”是指数据在存取时刻是最新的,“接近当前”是指存取的数据是最近一段时间得到的。
ODS与DW的区别
ODS在DBODSDW三层体系结构中起到一个承上启下的作用。
ODS中的数据虽然具有DW中的数据的面向主题的、集成的特点,但是也有很多区别。
(1)存放的数据内容不同:
ODS中主要存放当前或接近当前的数据、细节数据,可以进行联机更新。
DW中主要存放细节数据和历史数据,以及各种程度的综合数据,不能进行联机更新。
ODS中也可以存放综合数据,但只在需要的时候生成。
(2)数据规模不同:
由于存放的数据内容不同,因此DW的数据规模远远超过ODS。
(3)技术支持不同:
ODS需要支持面向记录的联机更新,并随时保证其数据与数据源中的数据一致。
DW则需要支持ETL技术和数据快速存取技术等。
(4)面向的需求不同:
ODS主要面向两个需求:一是用于满足企业进行全局应用的需要,即企业级的OLTP和即时的OLAP;二是向数据仓库提供一致的数据环境用于数据抽取。
DW主要用于高层战略决策,供挖掘分析使用。
(5)使用者不同:
ODS主要使用者是企业中层管理人员,他们使用ODS进行企业日常管理和控制。
DW主要使用者是企业高层和数据分析人员。
DW(OLAP)场景的关键特征
- 大多数是读请求
- 数据总是以相当大的批(> 1000 rows)进行写入
- 不修改已添加的数据
- 每次查询都从数据库中读取大量的行,但是同时又仅需要少量的列
- 宽表,即每个表包含着大量的列
- 较少的查询(通常每台服务器每秒数百个查询或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小: 数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每一个查询除了一个大表外都很小
- 查询结果明显小于源数据,换句话说,数据被过滤或聚合后能够被盛放在单台服务器的内存中
很容易可以看出,OLAP场景与其他流行场景(例如,OLTP或K/V)有很大的不同, 因此想要使用OLTP或Key-Value数据库去高效的处理分析查询是没有意义的,例如,使用OLAP数据库去处理分析请求通常要优于使用MongoDB或Redis去处理分析请求。
DB&ODS&DW三层架构
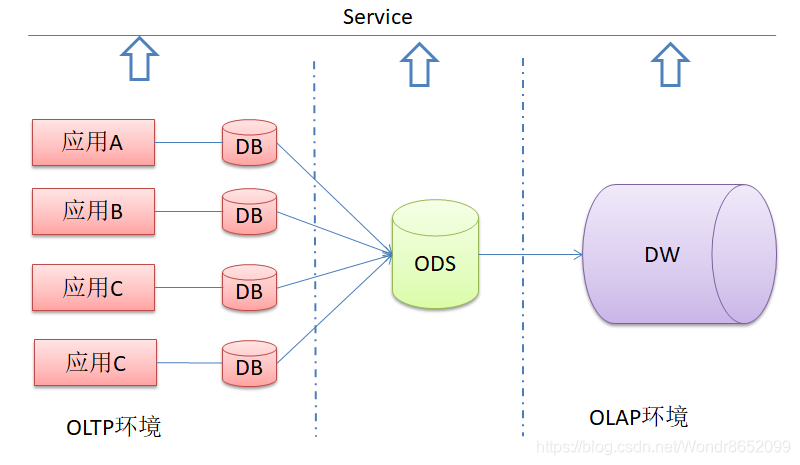
ODS和DW面向不同的用户,为不同的需求产生,因此都有不可替代的作用,两者相互结合、相互补充。
ODS在三层体系结构中扮演着承上启下的作用。
一方面,ODS在原来独立的各个DB的基础上建立了一个一致的、企业全局的、面向主题的数据环境,使原有的DB系统得到改造。
另一方面,ODS使DW卸去了数据集成、结构转换等一系列负担,对DW的数据追加通过ODS完成,大大简化的DW的数据传输接口和DW管理数据的复杂度。
ODS系统的建设,弥补了DB&DW两层体系结构的不足,但是ODS并不是必需的,当企业并不需要操作型集成信息时,基于DB&DW两层体系结构是较优的,如果需要,那么DB&ODS&DW三层体系结构则是较优的。
ODS技术选型
-
TiDB
TiDB 是 PingCAP 公司基于 Google Spanner / F1 论文实现的开源分布式 NewSQL 数据库。TiDB 的设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景。TiDB 具备如下 NewSQL 核心特性:- SQL支持 (TiDB 是 MySQL 兼容的)
- 水平线性弹性扩展
- 分布式事务
- 跨数据中心数据强一致性保证
- 故障自恢复的高可用
-
KUDU
Kudu是Cloudera开源的新型列式存储系统,是Apache Hadoop生态圈的成员之一(incubating),专门为了对快速变化的数据进行快速的分析,填补了以往Hadoop存储层的空缺。
kudu设计的初衷为了解决如下问题:- 对数据扫描(scan)和随机访问(random access)同时具有高性能,简化用户复杂的混合架构
- 高CPU效率,使用户购买的先进处理器的的花费得到最大回报
- 高IO性能,充分利用先进存储介质
- 支持数据的原地更新,避免额外的数据处理、数据移动
- 支持跨数据中心replication
Kudu的很多特性跟HBase很像,它支持索引键的查询和修改。Cloudera曾经想过基于Hbase进行修改,然而结论是对HBase的改动非常大,Kudu的数据模型和磁盘存储都与Hbase不同。HBase本身成功的适用于大量的其它场景,因此修改HBase很可能吃力不讨好。最后Cloudera决定开发一个全新的存储系统。
Kudu的定位是提供”fast analytics on fast data”,也就是在快速更新的数据上进行快速的查询。它定位OLAP和少量的OLTP工作流,如果有大量的random accesses,官方建议还是使用HBase最为合适。
这篇关于ODS概念总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







